
Creating Mind-Blowing Realistic Images From Simple Inputs with Stable Diffusion
A beginner's guide to Stable Diffusion Realistic Vision and LoRAs

Have you ever wished you could just describe an image to your computer and have it magically appear before your eyes? Or turn a low-quality avatar or sketch into a high-quality shot with your face on it? Well, now you can! Stable Diffusion Realistic Vision is an AI model that produces incredibly realistic images based on your descriptions or input pictures. It can transform even the most basic inputs into realistic photos. Neat!
In this guide, we'll walk you through how to use this model in your browser, and then how to take it even further with LoRAs. Ranked 64 on Replicate Codex, this model is a powerful tool you'll definitely want in your creative arsenal.
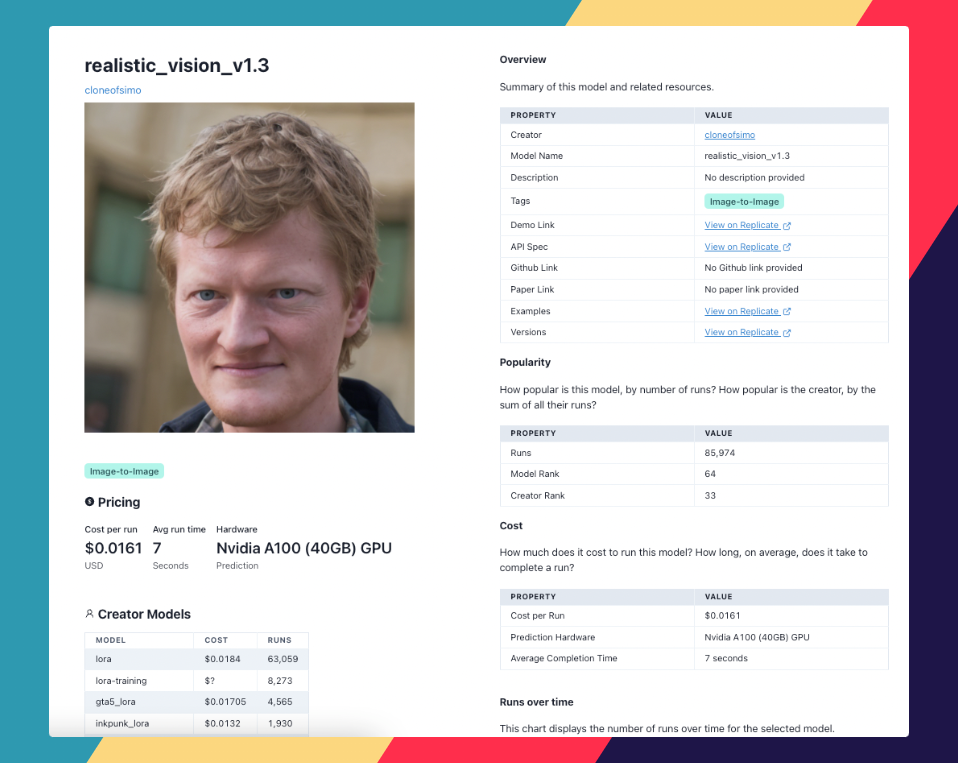
We'll also see how we can use Replicate Codex to find similar models and decide which one we like. Let's begin.
About the Stable Diffusion Realistic Vision Model
Stable Diffusion Realistic Vision (realistic_vision_v1.3), created by cloneofsimo, is an image-to-image AI model that generates stunningly realistic images from textual descriptions. It leverages the power of Stable Diffusion, a latent text-to-image diffusion model, to create photorealistic images from any text input.
LoRAs, or Learned Robust Artistic Styles, are files that can be applied to existing Stable Diffusion models to produce images based on specific concepts like art styles, characters, real-life people, objects, or themes. By combining the Stable Diffusion Realistic Vision model with LoRAs, you can create unique, personalized images tailored to your needs and preferences.
Understanding the Inputs and Outputs of the Stable Diffusion Realistic Vision Model
Inputs
The model requires a few inputs to generate an image:
- prompt: A text description of the image you want to create. Use
<1>,<2>,<3>, etc., to specify LoRA concepts. - negative_prompt: (Optional) Specify things you don't want to see in the output.
- width and height: Dimensions of the output image. Maximum size is 1024x768 or 768x1024 due to memory limits.
- num_outputs: Number of images to output.
- num_inference_steps: Number of denoising steps.
- guidance_scale: Scale for classifier-free guidance.
Outputs
The model will output an array of image URLs, one for each generated image.
Now that we understand the inputs and outputs, let's dive into how to use the model to create mind-blowing images.
A Step-by-Step Guide to Using Stable Diffusion Realistic Vision Model
If you're not up for coding, you can interact directly with this model's "demo" on Replicate via their UI. You can use this link to interact directly with the interface and try it out! This is a nice way to play with the model's parameters and get some quick feedback and validation.
Step 1: Set Up Your Environment
First, install the necessary Node.js package:
npm install replicateThen, copy your API token and authenticate by setting it as an environment variable:
export REPLICATE_API_TOKEN=[token]Step 2: Run the Model
Now, run the model with your desired input parameters:
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const output = await replicate.run(
"cloneofsimo/realistic_vision_v1.3:db1c4227cbc7f985e335b2f0388cd6d3aa06d95087d6a71c5b3e07413738fa13",
{
input: {
prompt: "a photo of <1> riding a horse on Mars",
width: 512,
height: 512,
num_outputs: 1,
num_inference_steps: 50,
guidance_scale: 7.5
}
}
);
Replace <1> with a specific LoRA concept if you want to customize the image even more. You can also adjust the other parameters as needed.
Recall from above that you can also provide an image input value. If you supply a file as an input argument for that field, the Image-to-Image mode will be invoked. You can see an example of an image-to-image run below.

For more information on Img2Img AIs (and how to run them), you can view our complete guide here.
The output variable will contain an array of image URLs generated by the model.
Taking it Further - Finding Other Image-to-Image Models with Replicate Codex
Replicate Codex is a fantastic resource for discovering AI models that cater to various creative needs, including image generation, image-to-image conversion, and much more. It's a fully searchable, filterable, tagged database of all the models on Replicate, and also allows you to compare models and sort by price or explore by the creator. It's free, and it also has a digest email that will alert you when new models come out so you can try them.
If you're interested in finding similar models to Stable Diffusion Realistic Vision, follow these steps:
Step 1: Visit Replicate Codex
Head over to Replicate Codex to begin your search for similar models.
Step 2: Use the Search Bar
Use the search bar at the top of the page to search for models with specific keywords, such as "realistic images" or "image generation." This will show you a list of models related to your search query.
Step 3: Filter the Results
On the left side of the search results page, you'll find several filters that can help you narrow down the list of models. You can filter and sort by models by type (Image-to-Image, Text-to-Image, etc.), cost, popularity, or even specific creators.
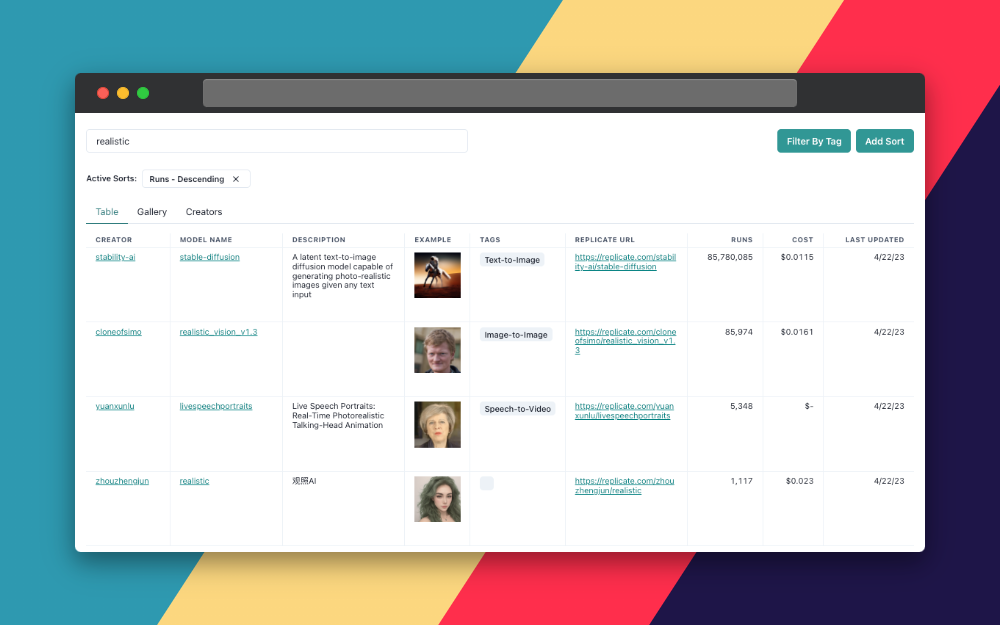
By applying these filters, you can find the models that best suit your specific needs and preferences. For example, if you're looking for an image generation model that's the most popular, you can just search and then sort by popularity.
Conclusion
In this guide, we explored how to use the Stable Diffusion Realistic Vision model to generate incredibly realistic images based on textual descriptions. We also discussed how to leverage the search and filter features in Replicate Codex to find similar models and compare their outputs, allowing us to broaden our horizons in the world of AI-powered image generation.
I hope this guide has inspired you to explore the creative possibilities of AI and bring your imagination to life. Don't forget to subscribe for more tutorials, updates on new and improved AI models, and a wealth of inspiration for your next creative project. Happy image enhancing and exploring the world of AI with Replicate Codex!
Subscribe or follow me on Twitter for more content like this!


Comments ()