
Ever Wanted to Ask a Picture a Question? A Beginner's Guide to BLIP-2
If a picture's worth a thousand words, maybe it's time to make one talk.

Tired of manually analyzing images? Struggling to turn pictures you love into usable prompts? Want a tool that can auto-caption any picture you generate? Want to ask a picture a question?
The BLIP-2 model is here to help! This powerful AI model can answer questions about images and generate captions, making your life easier. In this guide, I'll walk you through how to use the BLIP-2 model to analyze and caption images. I'll even show you how you can use the model to interrogate images!
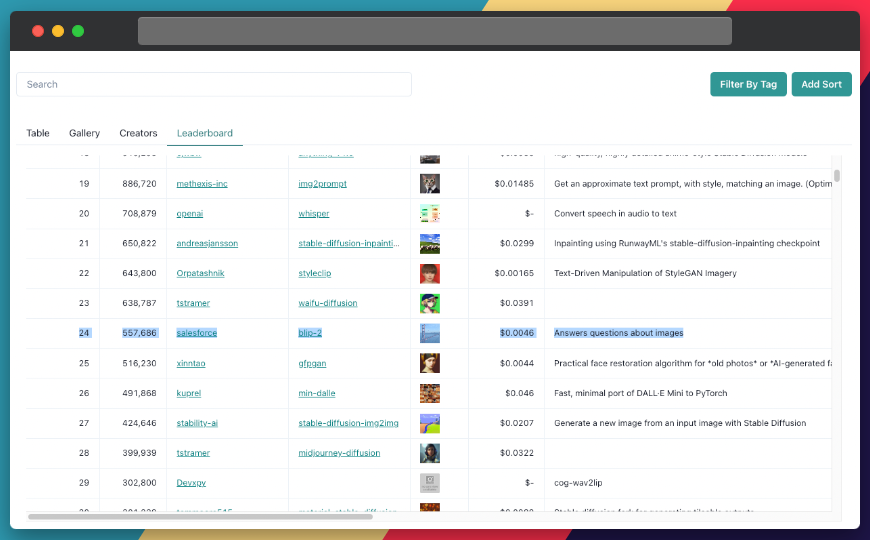
BLIP-2 is currently one of the most popular models on Replicate, coming in at number 24, with almost 560,000 runs. It has an average cost of $0.0046 per run, which makes it pretty affordable for most applications. Its creator is none other than Salesforce, which is one of the most popular creators on Replicate - number 5 overall, with three models that pull in a combined 9.5M runs!
I'll show you how to run BLIP-2 using Node.js and Replicate. Replicate is a platform that lets you easily interact with AI models via a simple API. We'll also see how to use Replicate Codex, a free community tool, to find similar models and decide which one is the best fit for your project. Let's begin!
About the BLIP-2 Model
BLIP-2 is an advanced AI model that can answer questions about images and generate captions. This model utilizes a generic and efficient pre-training strategy, combining pretrained vision models and large language models (LLMs) for vision-language pertaining.
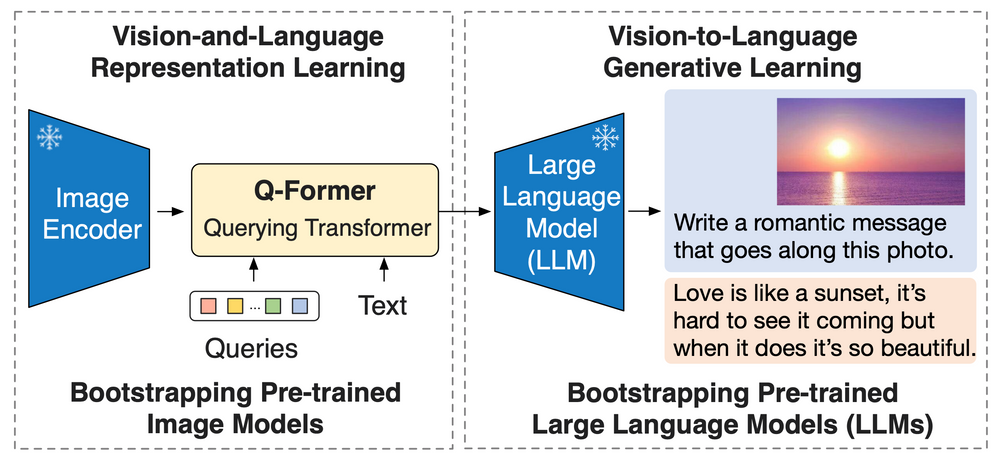
It outperforms Flamingo on zero-shot VQAv2 (65.0 vs 56.3), establishing a new state-of-the-art on zero-shot captioning (on NoCaps with a 121.6 CIDEr score vs the previous best of 113.2). Equipped with powerful LLMs such as OPT and FlanT5, BLIP-2 unlocks innovative zero-shot instructed vision-to-language generation capabilities for a wide range of applications.
This is all very technical jargon, so in plain English:
- BLIP-2 is better at answering visual questions (a task called VQAv2) without any prior training (zero-shot) compared to another model called Flamingo. BLIP-2 gets a score of 65.0, while Flamingo gets a score of 56.3.
- BLIP-2 also sets a new record in generating descriptions for images without prior training (zero-shot captioning). It does this on a dataset called NoCaps, where it gets a score of 121.6 using a metric called CIDEr. The previous best score was 113.2.
- BLIP-2 can be combined with powerful language models like OPT and FlanT5 to create new and exciting ways to generate language from visual input (like images). This can be used for a variety of applications.
You can learn more at the official repo. You can also compare BLIP-2 to the predecessor BLIP model.
Understanding the Inputs and Outputs of the BLIP-2 Model
Before we start playing around with the model, let's take a moment to study the expected inputs and outputs. We'll see how you can manipulate these values and what the effect of those changes will be.
Inputs
image(file): Input image to query or caption.caption(boolean): Select if you want to generate image captions instead of asking questions.question(string): Question to ask about this image (default: "What is this a picture of?")context(string, optional): Previous questions and answers to be used as context for answering the current question.use_nucleus_sampling(boolean): Toggles the model using nucleus sampling to generate responses.temperature(number): Temperature for use with nucleus sampling (default: 1)
Outputs
The model outputs a string that represents the answer or caption. The output is a very simple JSON object, as shown below:
{
"type": "string",
"title": "Output"
}A Step-by-Step Guide to Using the BLIP-2 Model for Image Analysis and Captioning
If you prefer a hands-on approach, you can interact directly with the BLIP-2 model's "demo" on Replicate via their UI. You can use this link to access the interface and try it out! This is an excellent way to play with the model's parameters and get quick feedback.
If you're more technical and looking to build a tool on top of the BLIP-2 model, follow these simple steps:
Step 1: Install the Replicate Node.js client
For this example, we'll be working with Node.js. So to start, we need to use npm to install the Node.js Replicate client. You can do this easily with the code below.
npm install replicate
Step 2: Authenticate with your API token
You can find your token on Replicate's site, in the account area.
export REPLICATE_API_TOKEN=[token]
Step 3: Run the model
To run the model with Node.js, simply use the code below. Be sure to format your input with all the fields and values in the "Inputs" section above.
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const output = await replicate.run(
"andreasjansson/blip-2:4b32258c42e9efd4288bb9910bc532a69727f9acd26aa08e175713a0a857a608",
{
input: {
image: "..."
}
}
);
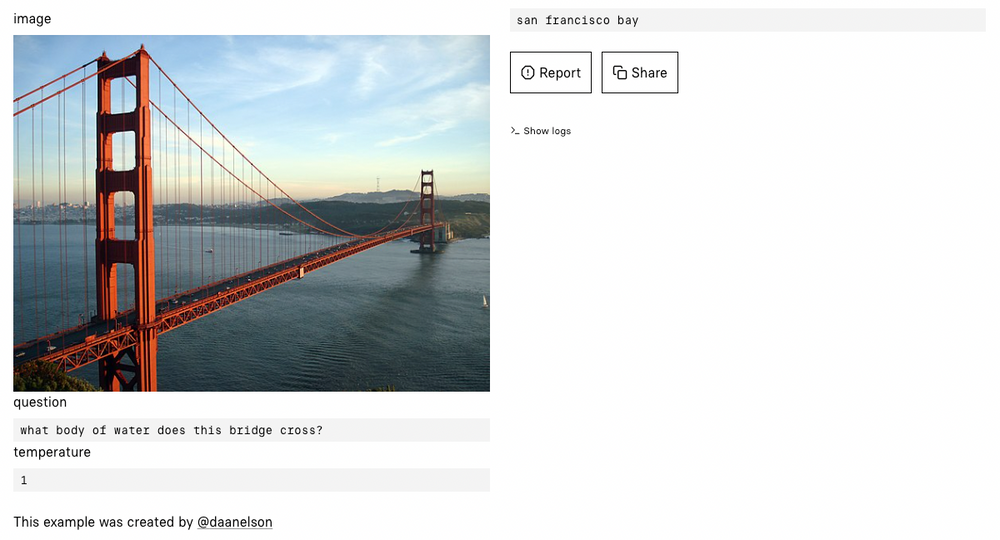
For example, if you provide the image below as the input, which the question set to "What is this a picture of?" and the temperature set to "1," the model will provide the output: "marina bay sands, singapore."

Sometimes, generations will take a long time. If you're interested in a strategy that will help you see when the run completes, you can also set up a webhook URL. You can refer to the webhook documentation for details on setting this up. Here's an example implementation of a webhook that should do the trick in this case.
const prediction = await replicate.predictions.create({
version: "4b32258c42e9efd4288bb9910bc532a69727f9acd26aa08e175713a0a857a608",
input: {
image: "..."
},
webhook: "https://example.com/your-webhook",
webhook_events_filter: ["completed"]
});
You can also review the Replicate Node.js library documentation for more info.
Taking it Further - Finding Other Image Analysis Models with Replicate Codex
Replicate Codex is a fantastic resource for discovering AI models that cater to various creative needs, including image generation, image-to-image conversion, and much more. It's a fully searchable, filterable, tagged database of all the models on Replicate, and also allows you to compare models and sort by price or explore by the creator. It's free, and it also has a digest email that will alert you when new models come out so you can try them.
If you're interested in finding similar models to BLIP-2, follow these steps:
Step 1: Visit Replicate Codex
Head over to Replicate Codex to begin your search for similar models.
Step 2: Use the Search Bar
Use the search bar at the top of the page to search for models with specific keywords, such as "image analysis," "image captioning," or "question answering." This will show you a list of models related to your search query.
Step 3: Filter the Results
On the left side of the search results page, you'll find several filters that can help you narrow down the list of models. You can filter and sort models by type (Image-to-Image, Text-to-Image, etc.), cost, popularity, or even specific creators.
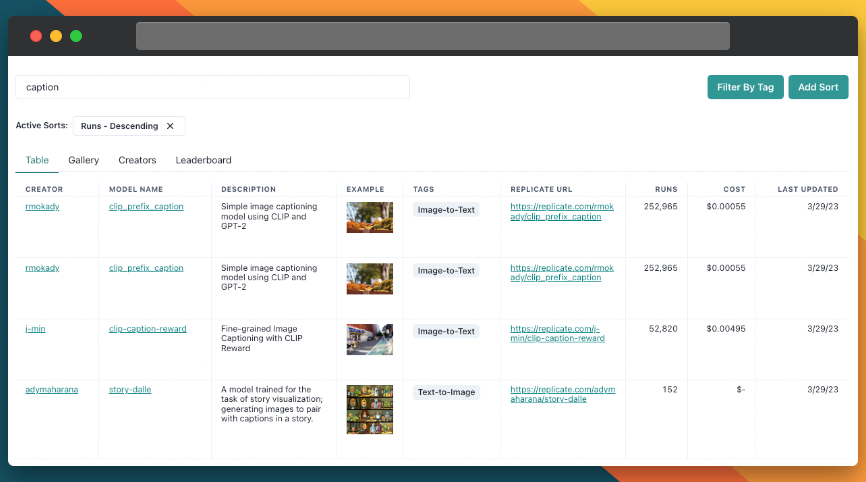
By applying these filters and sorts, you can find the models that best suit your specific needs and preferences. For example, if you're looking for an image analysis model that's the next most popular, you can just search and then sort by popularity, as shown in the example above. I chose to search by "caption" in this case.
Step 4: Explore and Compare Models
Once you have a list of models that match your search criteria and filters, you can click on each model to view more details about them. This includes a description of the model, its inputs and outputs, example code, and more.
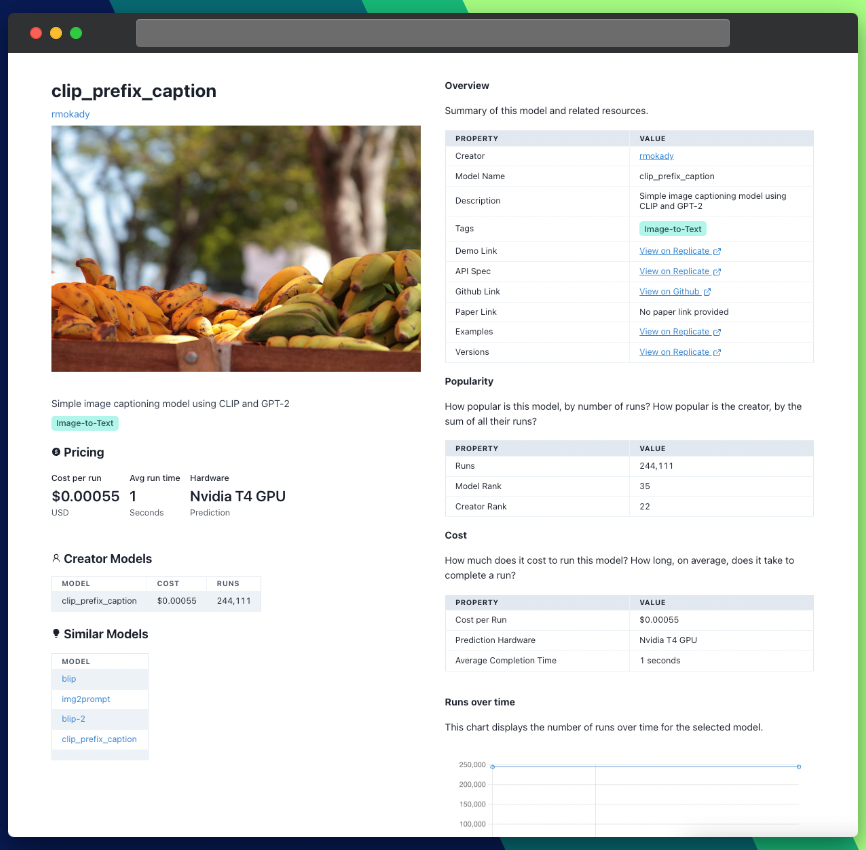
You can also compare the models' performance, pricing, and features to find the one that best fits your needs. Some models may have a higher resolution output, while others might focus more on preserving details or improving color accuracy. By comparing different models, you can choose the one that aligns with your requirements and expectations.
Conclusion
In this beginner-friendly guide, we introduced the BLIP-2 model, its capabilities, and saw how to use it for image analysis and captioning. We also discussed how to use the search and filter features in Replicate Codex to find similar models and compare their outputs, allowing us to broaden our horizons in the world of AI-powered image analysis and captioning.
I hope this guide has inspired you to explore the creative possibilities of AI and bring your imagination to life. Don't forget to subscribe for more tutorials, updates on new and improved AI models, and a wealth of inspiration for your next creative project.
Happy captioning, and thank you for reading. I hope you enjoy exploring the world of AI with BLIP-2 and Replicate Codex!
Subscribe or follow me on Twitter for more content like this!


Comments ()