
SELF-RAG: Improving the Factual Accuracy of Large Language Models through Self-Reflection
In recent years, artificial intelligence researchers have made astounding progress developing large language models that can generate remarkably human-like text. Models like GPT-3 and PaLM with billions or trillions of parameters display impressive versatility in language tasks. However, a major limitation persists - these models still frequently generate factual inaccuracies and unsupported claims. Overcoming this limitation is critical for reliably deploying LLMs in real-world applications like search engines, chatbots, and content creation tools.
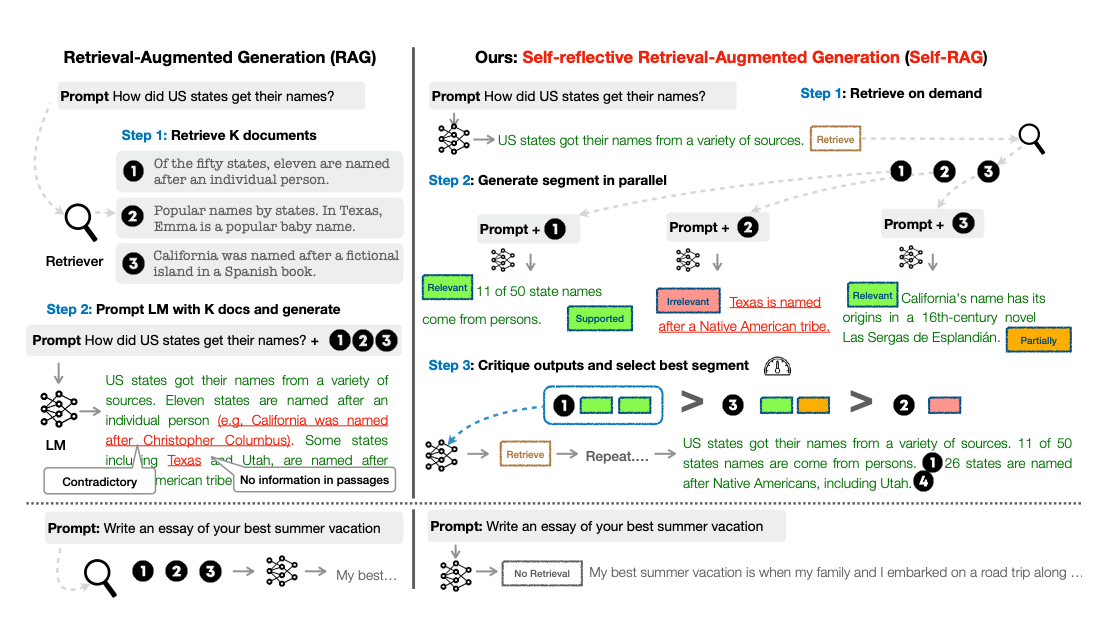
A team from the University of Washington and IBM Research recently made important headway on this challenge. In a paper published on arXiv, they introduced a novel technique called Self-Reflective Retrieval-Augmented Generation (SELF-RAG) that trains LLMs to enhance their own factual accuracy through selective retrieval of knowledge and self-critiquing of generations.
Subscribe or follow me on Twitter for more content like this!
The Persistent Problem of Factual Inaccuracy
Despite their human-like capabilities, LLMs inherently lack true understanding of the world. They are pattern recognition systems trained on vast amounts of text data. As a result, the knowledge encoded in their parameters is imperfect and prone to hallucination or contradiction. Prior work has shown LLMs often generate logical fallacies, unsafe advice, racist or biased statements, and other factual inaccuracies.
This severely limits the real-world applicability of LLMs. They cannot be reliably deployed in high-stakes domains like medicine, science, and finance where mistakes carry serious consequences. More research is urgently needed to address the factual grounding of LLMs. The authors cite this as the key motivation for developing SELF-RAG.
Prior Attempts at Mitigating Factual Errors
Some prior work attempted to mitigate factual errors in LLMs using retrieval augmentations. These approaches retrieve relevant passages from knowledge sources like Wikipedia and prepend them to the LLM's input. The retrieved passages provide factual context to inform the model's output.
However, standard retrieval augmentations have significant drawbacks. Indiscriminately retrieving passages slows inference and can pollute the input with irrelevant or contradictory information. More importantly, retrieved passages do not guarantee the model will actually be consistent with the factual evidence. The output may ignore or misinterpret the context.
How SELF-RAG Works - Technical Details
SELF-RAG tackles these challenges through a creative combination of selective retrieval and self-critiquing. The framework trains any off-the-shelf LLM to:
- Decide when retrieving external information is needed to improve factual accuracy. The model learns to generate special "retrieve" tokens to selectively trigger passage retrieval from Wikipedia and other corpora.
- Critique its own generations using novel "reflection tokens." These act as fine-grained feedback on relevance of retrieved passages and whether model outputs are properly supported by evidence.
The model is trained end-to-end by exposing it to examples of retrieved passages and reflection tokens generated by an initial critic model. The final trained model predicts standard output tokens alongside critique and retrieval tokens.
During inference, the model's self-critiques enable elegant control over trade-offs between retrieval frequency, output factuality, and creativity. The authors propose decoding algorithms that use the reflection tokens to filter or rank outputs.
Assessing SELF-RAG's Performance
The paper presents a comprehensive evaluation of SELF-RAG against strong baselines like ChatGPT on question answering, reasoning, and long-form generation tasks. The results are very promising:
- SELF-RAG (7B and 13B parameters) significantly outperformed all non-proprietary models across 6 diverse tasks. It even surpassed ChatGPT (175B parameters) on several metrics.
- On a factuality dataset, SELF-RAG-7B achieved 81.2% accuracy compared to just 71.2% for CoVE, a concurrent work using iterative prompt engineering.
- For biography generation, SELF-RAG-7B scored 80.2 on a factuality metric, versus just 71.8 for ChatGPT. Qualitative examples showed it produced more factual summaries with proper citations.
- On a long-form QA dataset, SELF-RAG-13B achieved far higher citation precision and recall than other models. This indicates it more accurately attributed factual claims to supporting evidence.
The ablation studies convincingly demonstrate the benefits of SELF-RAG's unique retrieve-then-critique approach. Removing either retrieval on demand or self-critiquing significantly degraded performance across tasks. SELF-RAG appears to hit a sweet spot between leveraging knowledge and retaining model creativity.
Limitations and Open Questions
However, SELF-RAG is not yet a silver bullet for factual accuracy in LLMs. The paper's human evaluation found it still generated some unsupported claims on certain examples. There remain open questions around training data scale, retrieving from broader knowledge sources, and optimizing the reliability of self-critiques. Integrating retrieval and reflection also incurs a cost in inference latency.
Nonetheless, SELF-RAG represents an exciting step towards more grounded LLMs. The work pioneers a paradigm of LLMs that are not purely static, but can dynamically strengthen their own knowledge as needed through context retrieval and self-assessment. This points the way to increasingly robust and trustworthy AI systems.
PS: I've written about a few topics tangential to this one. I recommend reading the following:
- Can LLMs self-correct their own reasoning? Probably not.
- Researchers Discover Emergent Linear Structures in How LLMs Represent Truth
Subscribe or follow me on Twitter for more content like this!


Comments ()