
Researchers Discover Emergent Linear Structures in How LLMs Represent Truth
LLMs contain a specific "truth direction" denoting factual truth values.
Artificial intelligence systems like large language models have shown impressive capabilities, such as engaging in conversation, answering questions, and generating coherent text. However, they are also prone to making clearly false statements or hallucinating incorrect information. For example, LLMs may state as true something which is obviously untrue to any human, or make up facts and details that have no basis in reality.
This issue of AI systems generating falsehoods is important for both practical and ethical reasons. On a practical level, we would like AI systems that assist us to provide truthful information so we can rely on them. Generating blatantly false statements reduces trust in and usefulness of AI. Ethically, there are concerns that widespread false claims from AI could spread misinformation or cause other harms if deployed irresponsibly.
Therefore, an important challenge is developing techniques to determine when an AI system "knows" or "believes" a statement is actually true or false, versus simply generating plausible-sounding but incorrect text. Access to an AI's internal representation of the truth or falsity of a statement could allow filtering out false claims before they are output. Recent research has begun exploring this direction.
Specifically, researchers have tried "probing" the internal neural network representations of LLMs to see if directions or vectors corresponding to true statements can be identified. For example, a probe may attempt to classify if the LLM representation of the statement "The sky is green" is oriented closer to true or false statements. However, it has been unclear whether such probes really identify abstract "truth" or simply features of text correlated with but distinct from truth.
For instance, a probe trained on simple true statements may rely on them being more common or statistically plausible, rather than their truth value specifically. The tendency of probes to fail on negated statements like "The sky is not green" highlights this issue. Do probes truly extract the logic of truth, or just features loosely predictive of it?
Subscribe or follow me on Twitter for more content like this!
Key Findings
A new paper from researchers at MIT and Northeastern University digs deeper into this problem. Their work provides several strands of evidence that LLM representations may contain a specific "truth direction" denoting factual truth values.
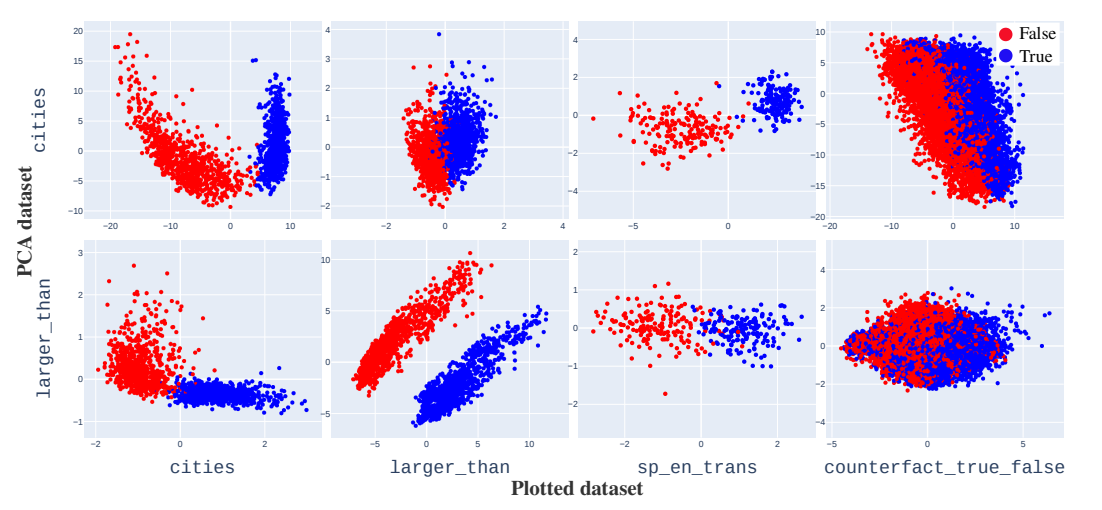
First, the researchers curated diverse datasets of simple true/false factual statements, like "Lima is the capital of Peru" (true) and "Boston is the capital of Canada" (false). Visualizing LLM representations of these statements reveals clear linear separation between true and false examples. This structure emerges along the first few principal components of variation.
Intuitively, this suggests LLM representations may have a "truth axis" denoting how factual a statement is. True examples cluster on one side, false on the other. This provides initial evidence of an explicit truth direction in LLM internals.
Second, the researchers systematically tested whether linear "probes" trained on one dataset could accurately classify the truth of totally distinct datasets. For instance, a probe trained only on mathematical comparisons like "9 is greater than 7" (true) transferred well to identifying the truth of Spanish-English translations like "Gato means cat" (true).
The ability of probes to generalize supports that they identify a general notion of truth, not just patterns coincidentally correlated with truth in narrow datasets. In technical terms, this provides stronger "correlational" evidence for a truth direction.
Third, through careful experimentation, the researchers directly manipulated LLM internal representations in ways that caused them to flip the assessed truth value of statements. For example, surgically adding the "truth vector" identified by a probe to the LLM's processing made it assess false statements as true, and vice versa.
This establishes strong "causal" evidence showing the truth directions extracted by probes are functionally implicated in the model's logical reasoning about factual truth. This goes beyond mere correlation.
Together, these multiple strands of analysis provide compelling support for the presence of an explicit, linear representation of factual truth in LLM internals. Identifying such a stable truth direction opens possibilities for filtering out false statements before they are output by LLMs.
What does this mean in plain English?
In plain English, this research provides solid evidence that deep learning models like LLMs can linearly represent factual truth in their internal learned representations. Using visualization, generalization tests, and surgical manipulation, the researchers establish that LLM neural networks contain a kind of "truth vector" pointing towards definitely true statements and away from false ones.
By training "probes" on simple true/false datasets, we can extract this truth direction from an LLM's high-dimensional representations. The probes work by identifying which way encodings of true statements tend to point, versus false ones. This provides interpretable insights into how AI systems internally model fundamental concepts like objective truth.
Adding the extracted truth vector into the model's processing makes it assess false claims as true, and vice versa. This shows the vector plays a causal role in logical reasoning, rather than merely being correlated with truth. Altogether, this research provides significant evidence that the abstract notion of factual truth really is encoded in the learned representations of AI systems.
Of course, limitations remain. The simple statements studied may fail to capture more complex or controversial truths. There is still work to do extracting more general "truth thresholds" beyond directions. Nonetheless, this research highlights some pretty good progress in inspecting how AI represents truth, which could help make future systems more truthful.
Significance and Limitations
Understanding how AI systems represent notions of truth is crucial for improving their reliability. If models explicitly encode truth vs falsity in their learned representations, this opens possibilities for making them less prone to falsehoods and hallucination. Extracting an interpretable representation of truth also makes AIs more transparent, explainable, and trustworthy.
However, many open challenges remain. This study focused on simple factual statements (like which cities are state capitals), but complex truths involving ambiguity, controversy, or nuance may be harder to capture. The methods may not work as well for cutting-edge LLMs with different architectures. And there is also more work needed to extract "truth thresholds" beyond just directions in order to make firm true/false classifications.
Nonetheless, this research makes significant progress on a very difficult problem. The evidence it provides for linear truth representations in AI systems is an important step. Truthfulness is a critical requirement as AI grows more powerful and ubiquitous. Research like this highlights promising paths towards making future systems less prone to spouting falsehoods.
Subscribe or follow me on Twitter for more content like this!


Comments ()