
GPT-4 Doesn’t Know It’s Wrong: An Analysis of Iterative Prompting for Reasoning Problems
How real are the performance gains from self-reflection?
There has been tremendous enthusiasm around large language models (LLMs) like GPT-3 and GPT-4 and their potential to perform complex reasoning and language tasks. Some researchers have claimed these models exhibit an "emergent" capability for self-reflection (like SELF-RAG) and critique that allows them to improve reasoning performance over multiple iterations of prompting.
How real are these performance gains from self-reflection? A rigorous new study attempts to quantitatively answer just how effective iterative prompting truly is for boosting reasoning skills in LLMs.
Subscribe or follow me on Twitter for more content like this!
The promise and hype around iterative prompting
The core premise behind using iterative prompting for reasoning tasks is that it should be easier for LLMs to verify solutions than to generate them from scratch. So by having the model critique its own solutions iteratively, its reasoning performance should improve over multiple rounds.
This notion fits with the overarching excitement and hype surrounding LLMs. Despite limitations on reasoning demonstrated in other studies, there is a persistent narrative that scale and technique alone will unlock more and more human-like capabilities in these models. The hope is that given enough data and iterations, LLMs will become adept at logic, reasoning, and even self-reflection. If true, this would make iterative prompting a key technique for developing more robust reasoning skills.
Some researchers have actively promoted this vision. For example, a 2023 article from Stanford stated that LLMs that incorporate "self-reflection" can substantially improve performance on complex tasks over just a few iterations. This ties closely into the corporate messaging around "self-supervised learning" and models critiquing themselves. The notion that iterative prompting enables models to spot their own mistakes and correct themselves has gained widespread traction. I swear I've even seen it myself when using ChatGPT.
But does this capability truly exist, or are we fooling ourselves? Can we demonstrate it exists rigorously?
Putting iterative prompting to the test
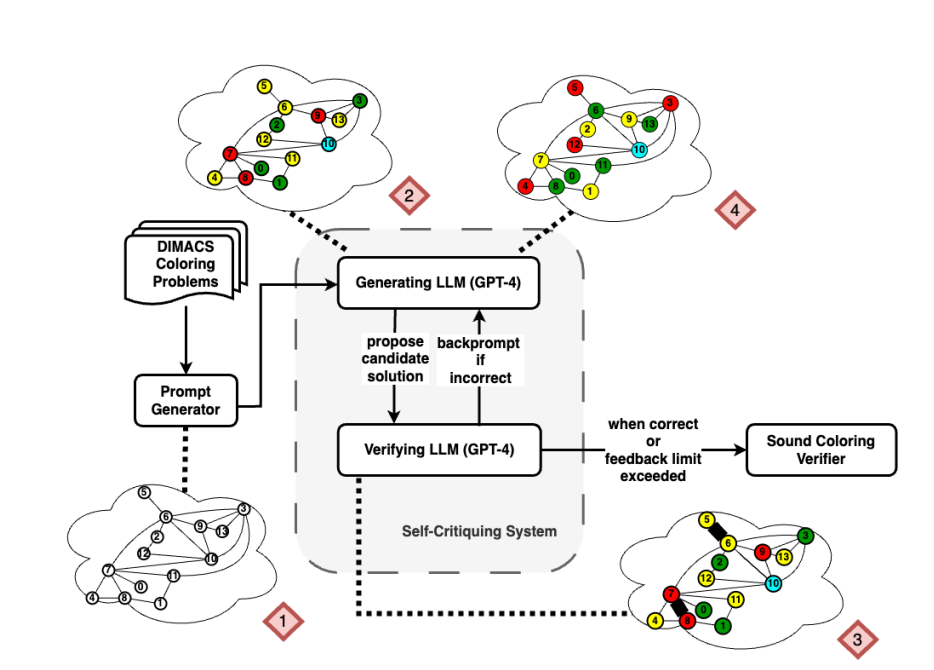
To dig into the effectiveness of iterative prompting, researchers from Arizona State University focused on the canonical NP-hard problem of graph coloring. This problem involves assigning colors to nodes in a graph such that no two adjacent nodes share the same color (think of the logic needed to make maps of the world readable by ensuring that no bordering countries share the same color). This task represents a form of constraint satisfaction with connections to scheduling and other reasoning tasks.
The researchers tested the performance of GPT-4 on solving and verifying graph coloring instances across 100 different random graphs. They experimented with different prompting strategies:
- Direct generation of a single coloring without feedback
- Iterative self-critique where the model provides feedback on its own solutions
- Iterative prompting with external feedback from a correct verifier, including binary feedback, first error identification, and enumeration of all errors.
For comparison, they also tried variations such as higher temperature and prompting for multiple independent solutions.
Key results: limitations of iterative prompting
The results reveal significant limitations of iterative prompting for improving reasoning capabilities:
- GPT-4 struggled to directly solve graph coloring instances, only succeeding on 16% of graphs.
- Surprisingly, GPT-4 was equally poor at verifying colorings, failing to recognize when a solution was valid.
- With self-critiquing, performance declined even further, with GPT-4 incorrectly rejecting its own occasional correct solutions.
- External feedback did help somewhat, improving success to ~40%, but minimal "try again" feedback was as effective as detailed error identification.
- Asking GPT-4 for multiple independent solutions and selecting any correct ones performed just as well as iterative prompting.
In essence, any gains from iterative prompting stem largely from having multiple chances for a correct solution to occur, not from any true error identification or reasoned critiquing by the LLM itself.
Assessing the evidence from a critical perspective
Digging deeper into the numerical results:
- In 40 cases, GPT-4 generated a valid solution but incorrectly rejected it when self-critiquing. This demonstrates a clear lack of reasoning ability.
- With external feedback, the type of feedback provided barely improved results over binary pass/fail feedback. This suggests the content of prompts mattered little.
- The LLM blindly "corrected" errors in prompts randomly stating a correct edge was wrong 94% of the time, demonstrating it does not actually understand or reason about the feedback.
Additionally, when verifying solutions independently, the authors note: "Out of 100 optimal colorings, it only agreed that 2 were correct. Expanding to the entire set of 500 colorings, of which 118 of them are correct, it only claimed 30 of them as correct. Of those, it was right 5 times. This isn’t because of any special property of correctness–the same holds true in the non-optimal coloring set, in which it only marked 10% of instances as non-optimal."
Overall, the quantitative results decisively demonstrate that iterative prompting fails to enhance reasoning capabilities as claimed. The evidence shows behavior much closer to blind trial-and-error than nuanced self-critiquing or comprehension.
Broader significance and conclusions
This study provides compelling evidence that counters the dominant narrative around LLMs and iterative prompting. Rather than exhibiting sophisticated self-reflection, LLMs seem to simply generate multiple guesses, with slight improvements stemming from brute force rather than true reasoning. Their critiquing skills cannot be assumed to match human capabilities. This has some big implications for models that rely on critiquing agents as part of a proposed agent-based framework for solving complex tasks like 3D modeling and film directing (as I've written about here).
The conclusions warrant skepticism around claims that LLMs will smoothly develop complex reasoning solely through scale and training on massive datasets. While iterative prompting may still prove useful in some domains, its limitations call for further rigorous interrogation of how well LLMs can master core capacities like logical reasoning versus merely optimizing predictive accuracy. If the AI community's goals include robust reasoning, it cannot rely on iterative prompting as a panacea.
As with any study, there's room for improvement. Graph coloring represents just one task. Testing iterative prompting on diverse reasoning problems and investigating where it does and does not work will provide a fuller understanding. Regardless, this research delivers a blow to the hype around "self-supervised" LLMs dynamically improving their own solutions. Unbridled optimism must be tempered with rigorous skepticism and testing. Where reasoning is concerned, LLMs probably still have a long way to go.
Subscribe or follow me on Twitter for more content like this!
Related reading:
I've written about a few topics related to this one. You might find these other articles interesting



Comments ()