
Converting Speech into Text with OpenAI's Whisper Model
Let's learn how to convert audio to text with the WhisperAI model
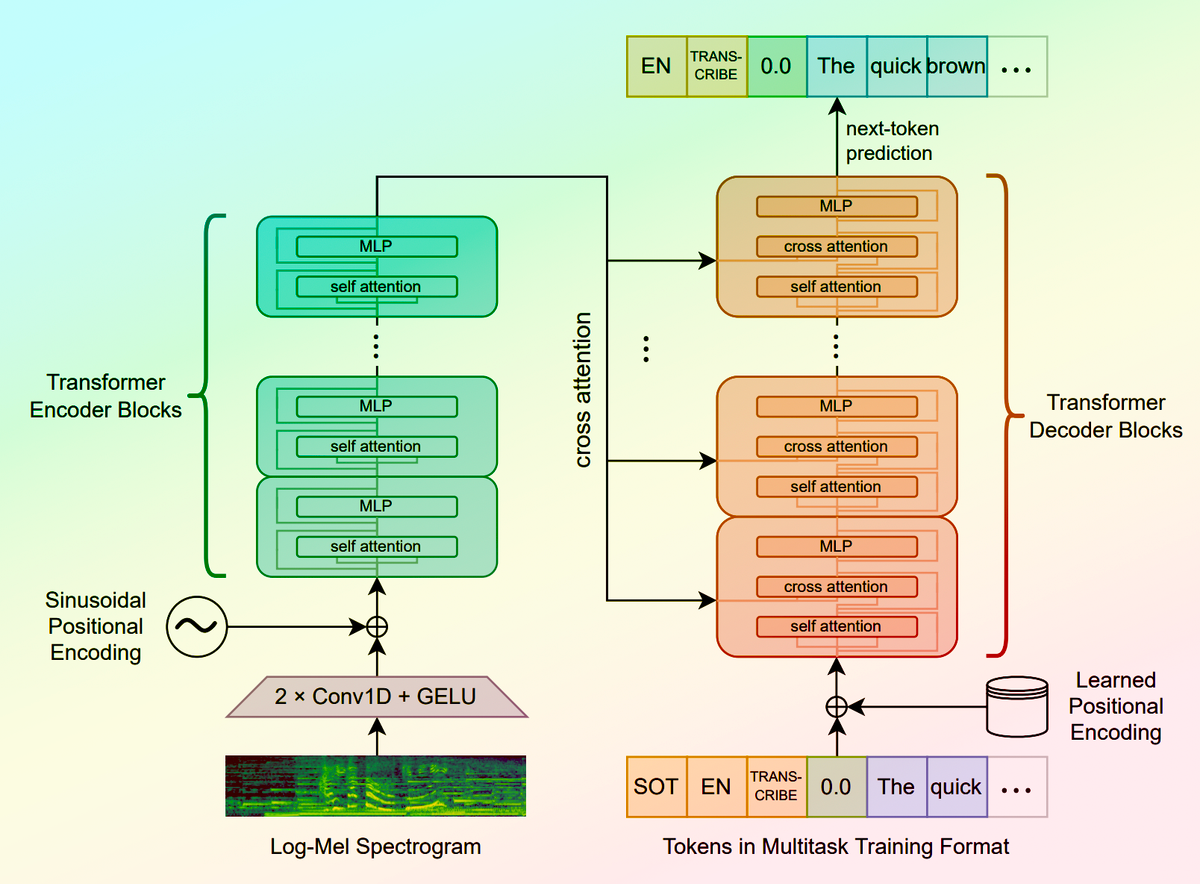
In our increasingly digital world, the need for transcribing speech to text is just getting more important. Whether it's for accessibility, content creation, data analysis, or something else, converting spoken language into written form is a problem that demands an efficient solution. Enter Whisper, an AI model by OpenAI that does exactly that: turning the spoken word into easily digestible text.
Subscribe or follow me on Twitter for more content like this!
This guide will walk you through what Whisper is, how it functions, and how to effectively use it. Currently ranked 19th on AIModels.fyi, Whisper is a powerful tool that can be of great use in various applications. We'll also explore how you can use AIModels.fyi to find similar models to suit your unique requirements. So, without further ado, let's delve into the world of AI-powered speech-to-text transcription.
About the Whisper Model
Whisper, an AI model created by OpenAI, is designed to convert speech in audio files into text. Its applications are extensive, ranging from generating subtitles for videos to transcribing interviews or meetings. With more than 2M runs, Whisper stands out as a reliable and popular model in its category.
The model takes an audio input and transcribes it into the written word, effectively bridging the gap between spoken and written language. Furthermore, it supports a vast number of languages, making it an excellent tool for multilingual projects. More detailed information about the model can be found on its detail page.
Understanding the Inputs and Outputs of the Whisper Model
Before diving into the usage of the Whisper model, it's important to understand what goes in and what comes out - that is, the inputs and outputs of the model.
Inputs
The primary input for Whisper is an audio file, which it processes and transcribes into text. Additional input parameters allow you to customize how the model operates:
model string: Allows you to select from different versions of the Whisper model.transcription string: Lets you choose the format for the transcription, with options for plain text, srt, or vtt.translate boolean: Gives you the ability to translate the text to English.language string: Allows you to specify the language spoken in the audio.temperature number: This parameter controls the 'creativity' of the model's output.suppress_tokens string: A list of token ids that you don't want the model to output.
Outputs
The model outputs an object containing the transcribed text, with several fields:
segments: The transcriptions are broken into segments.srt_file&txt_file: Transcription results can be obtained in these formats.translation: If the translation option is enabled, the translated text is provided here.transcription: This is the final transcribed text.detected_language: The language detected by the model.
Now that we understand what the model takes in and puts out, let's see how we can use it to solve our transcription problems!
Using the Whisper Model to Transcribe Speech to Text
Whether you're a coder who likes to get hands-on or prefer a more interactive demo approach, using the Whisper model is simple and straightforward.
Step 1: Authentication
First, you'll need to install the Replicate Node.js client and authenticate using your API token. This allows you to interact with the Whisper model programmatically.
npm install replicate
export REPLICATE_API_TOKEN=your_api_token_here
Step 2: Running the Model
After authenticating, you can run the model with your audio input:
import Replicate from "replicate";
const replicate = new Replicate({
auth: process.env.REPLICATE_API_TOKEN,
});
const output = await replicate.run(
"openai/whisper:91ee9c0c3df30478510ff8c8a3a545add1ad0259ad3a9f78fba57fbc05ee64f7",
{
input: {
audio: "your_audio_here"
}
}
);
You can also set a webhook to be called when the prediction is complete, which can be useful for asynchronous processing:
const prediction = await replicate.predictions.create({
version: "91ee9c0c3df30478510ff8c8a3a545add1ad0259ad3a9f78fba57fbc05ee64f7",
input: {
audio: "your_audio_here"
},
webhook: "https://example.com/your-webhook",
webhook_events_filter: ["completed"]
});
Taking it Further - Finding Other Audio-to-Text Models with AIModels.fyi
Perhaps you'd like to compare Whisper with other models or explore other models in the same problem space. How can you find them? Well, AIModels.fyi is a fantastic resource for this purpose, featuring a fully searchable and filterable database of AI models from various platforms.
Step 1: Visit AIModels.fyi
Head over to AIModels.fyi to start your search for similar models.
Step 2: Use the Search Bar
Use the search bar at the top of the page to search for models with specific keywords, such as "audio-to-text" or "transcription". This will display a list of relevant models.
Step 3: Filter the Results
After using the search bar, you can further narrow down the results by using the filters on the left side of the page. You can filter and search models based on various criteria, including:
- Platforms: The platform the model is hosted on, such as OpenAI, Hugging Face, etc.
- Creator: The creator or organization behind the model.
- Cost: The price range for using the model.
- Description: What the model does and what it's used for.
Step 4: Explore Model Details
Once you've found a model that catches your interest, click on it to view more details. You'll be able to see a comprehensive breakdown of the model's features, including its inputs and outputs, performance metrics, and use cases.
Conclusion
Whether you're a seasoned developer or a newcomer to the world of AI, OpenAI's Whisper is an accessible and powerful tool for converting speech into text. Coupled with resources like AIModels.fyi, it's easier than ever to find the perfect model for your unique project needs. Dive in and start exploring the possibilities today!
Subscribe or follow me on Twitter for more content like this!


Comments ()