
A builder's guide to synthesizing sound effects, music, and dialog with AudioLDM
What makes this model special? What can you build with it? An in-depth guide to creating sound and speech from text or audio files using AudioLDM text-to-audio.
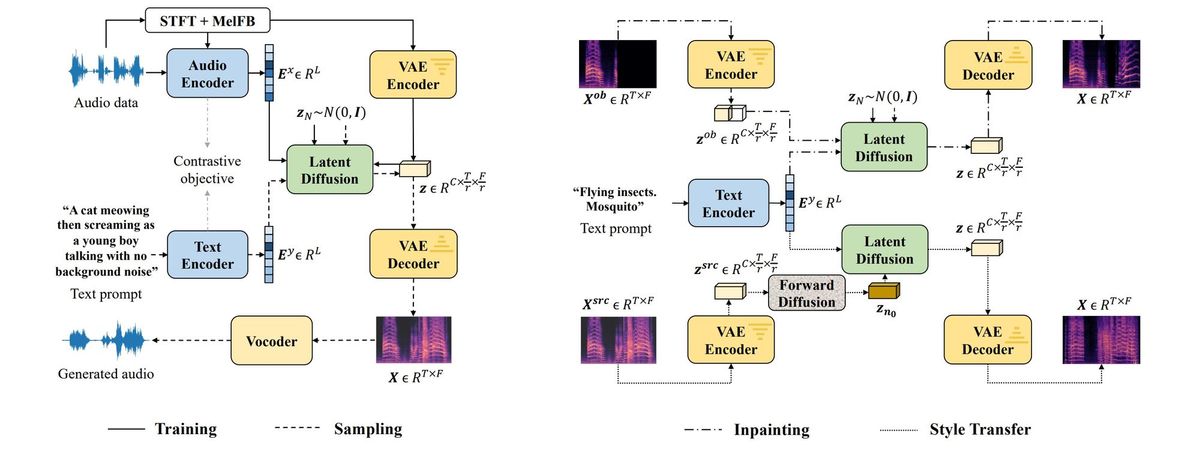
In the realm of text-to-audio AI models, the race to create more realistic, immersive experiences has been heating up. A promising runner in this race is AudioLDM, which uses some novel techniques to generate speech, sound effects, or music from text or audio prompts. But how exactly does AudioLDM achieve this? And more importantly, what does the way in which the tech works tell us about the kinds of products we can build with it?
In this article, we'll study AudioLDM to see what makes it special and understand how we can take advantage of those unusual and special capabilities to build interesting new startup products. Let's begin.
Subscribe or follow me on Twitter for more content like this!
AudioLDM at a glance
LDM stands for Latent Diffusion Model. AudioLDM is a novel AI system that uses latent diffusion to generate high-quality speech, sound effects, and music from text prompts. It can either create sounds from just text or use text prompts to guide the manipulation of a supplied audio file.
Check out this video demo from the creator's project website, showing off some of the unique generations the model can create. I liked the upbeat pop music the best, and I also thought the children singing, while creepy, was pretty interesting.
Key features of AudioLDM:
- Uses a Latent Diffusion Model (LDM) to synthesize sound
- Trained in an unsupervised manner on large unlabeled audio datasets
- Operates in a continuous latent space rather than discrete tokens
- Employs Cross-Modal Latent Alignment Pretraining (CLAP) to map text and audio
- Can generate speech, music, and sound effects from text prompts or a combination of a text and an audio prompt
- Allows control over attributes like speaker identity, accent, etc.
- Synthesizes realistic sound effects and music
- Creates sounds not limited to human speech (e.g. nature sounds)
- Generates audio samples up to 10 seconds long
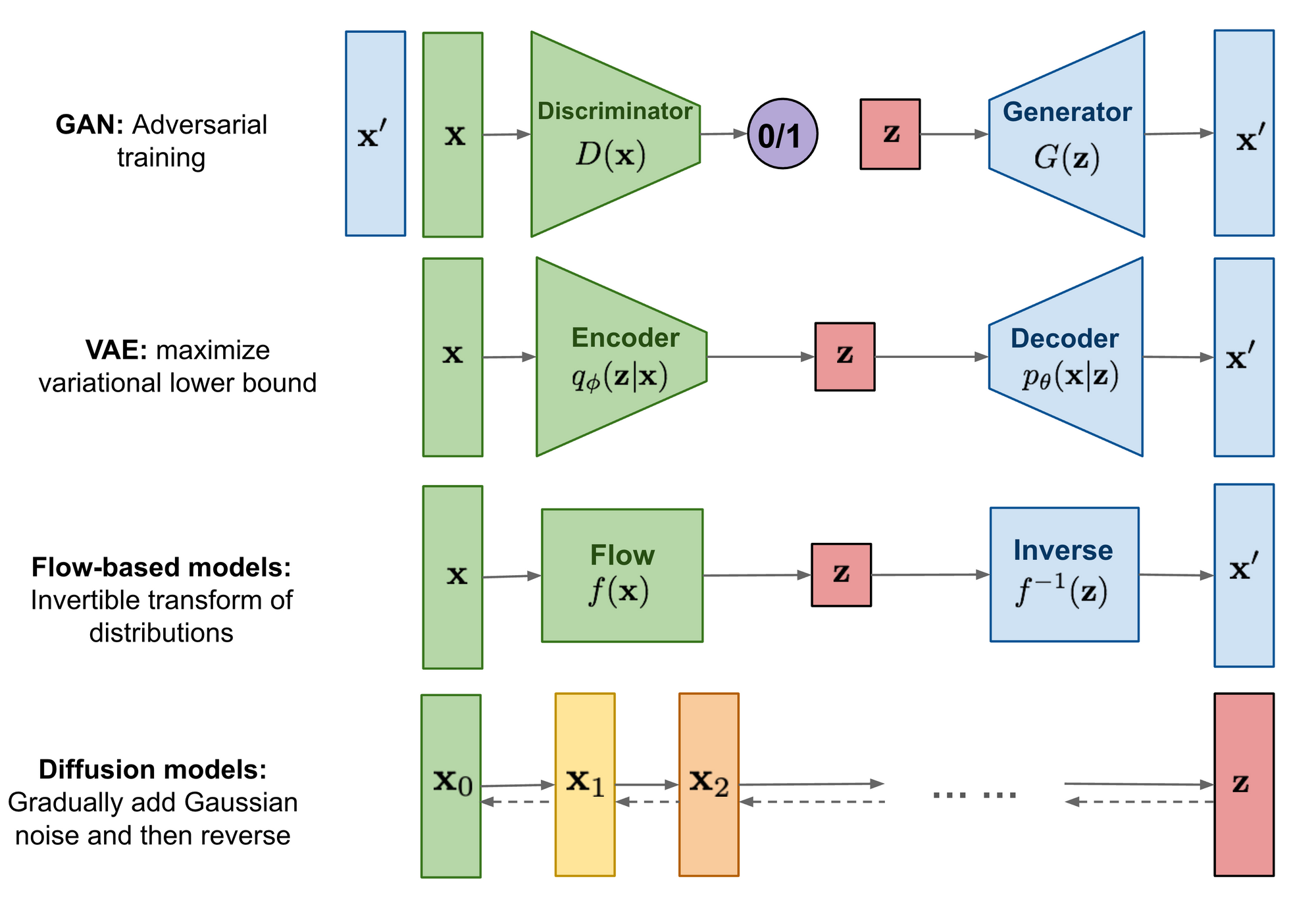
In a nutshell, AudioLDM pushes boundaries in controllable audio synthesis and lets us build some innovative text-to-audio products and services that were previously difficult to build. There are opportunities in gaming, audiobooks, accessibility, and beyond. Let's see a few.
AudioLDM Use Cases
There are lots of world-changing AI products just waiting to be built, all powered by AudioLDM. The capability to create high-quality, customizable synthetic sound isn't just an interesting theoretical outcome to read about on Arxiv—it also enables a host of new impactful applications for text-to-audio technology. Here are a few:
- Unleash Immersive Gaming Experiences: With AudioLDM, you can break the shackles of generic gaming dialogues. Imagine games where every character has a unique voice and speech pattern. Your games will no longer be about just play—they become living, breathing digital realms filled with distinct personalities that heighten immersion for gamers. You can also use the model to create sound effects from just a text prompt.
- Revolutionize the Audiobook Landscape: It's time to take the listener on a journey. Use AudioLDM to create audiobooks where each character speaks in a unique voice. Transform the listening experience from a monologue to a dynamic conversation, and create theatre-like immersion for your audience.
- Reimagine Learning Platforms: Learning is personal, and so should be the learning platforms. Use AudioLDM to offer personalized voices that cater to individual learner needs in your language learning apps or online media. Make the learning process more efficient, enjoyable, and inclusive.
- Drive Accessibility Forward: With AudioLDM, you can make technology more accessible for individuals with disabilities. Whether it's screen readers or voice assistants, you can customize and control the synthesized speech to make your user experience more personal and effective.
As you can see here, there are a lot of potential startups waiting to be built. How are you going to use AudioLDM to build a text-to-audio product that will reshape your industry? Let's peel back the layers to understand what makes AudioLDM tick, and how you can harness its power to fuel your startup's growth.
The Technology Behind AudioLDM
If you're considering AudioLDM as a tool to create your next product, you need to understand the distinct technological principles that make this AI model unique. AudioLDM's text-to-audio capabilities are built on three pillars: its usage of 'unpaired learning', its operation within a 'continuous latent space', and a special technique known as 'Cross-Modal Latent Alignment Pretraining' (CLAP). Each of these elements contributes to its ability to synthesize controllable, high-quality sound.
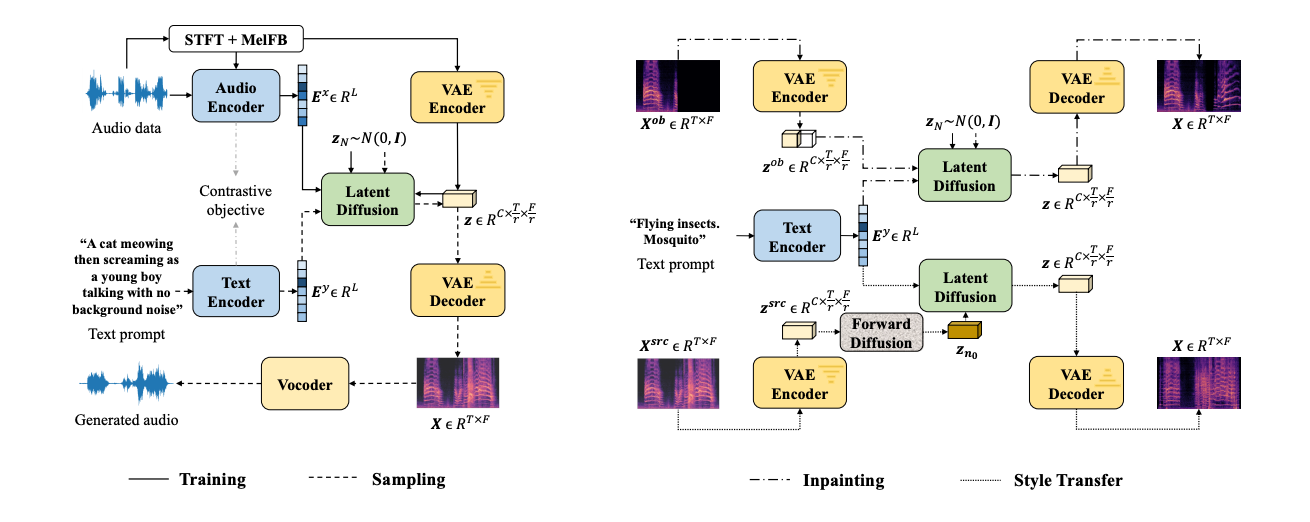
Let's look at each element in more detail to understand why they matter.
Unpaired Learning
Most AI models expect tidy datasets of aligned input-output pairs during training - for example, large tables of audio clips perfectly matched to their text transcriptions. AudioLDM rips up this playbook, learning entirely from unpaired audio data without any accompanying text.
It relies on a clever self-supervised pretraining scheme. The model tries to reconstruct audio waveforms from compressed latent representations of those sounds. By minimizing the reconstruction error, it's forced to encode all the most salient features of natural speech into the latent space.
Once AudioLDM has learned to represent audio data in this compact form, it can then condition its internal generative model on text prompts. This unpaired approach means we bypass cumbersome labeled datasets, instead unleashing the model on oceans of unlabeled audio data.
Latent Space vs. Tokens
Many speech models generate audio as a series of discrete, categorical outputs - like putting together Lego blocks to form sounds. But AudioLDM breaks free of this restrictive paradigm.
It operates in a smooth, continuous latent space obtained by condensing audio spectrograms using a variational autoencoder (VAE). A spectrogram is a visual representation of the spectrum of frequencies in a sound over time. It displays the intensity levels of different frequencies as they vary through an audio clip. Spectrograms are created by applying a Fourier transform to break down sound waves into component frequencies.
A variational autoencoder (VAE) is a type of neural network used for dimensionality reduction and generative modeling. It consists of an encoder and a decoder. The encoder compresses input data into a lower-dimensional latent space. The decoder tries to reconstruct the original input from points in the latent space. VAEs are used in many different models, and are often used in image generators like Anything v3 VAE.
In a VAE, the encoder outputs a mean and variance for each latent dimension. These define a Gaussian distribution in the latent space. Sampling from these distributions and passing samples through the decoder allows generating new data similar to inputs.
So for AudioLDM, the VAE condenses audio spectrograms into a smooth latent space. Interpolating between latent vectors mixes different voices and sounds. The decoder converts latent points back into realistic audio by leveraging patterns learned from training data. This gives AudioLDM its expressive generative capabilities.
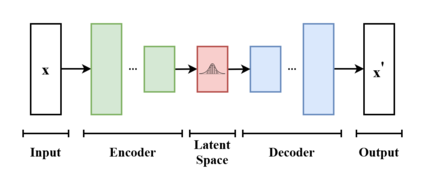
This continuity also encodes natural variation and uncertainty inherent to speech. Sampling latent points results in diverse outputs, even when the text prompt stays fixed. And lower-dimensional latent modeling greatly reduces computational overhead.
Bridging Modalities with Cross-Modal Conditioning
Here's the trick that lets AudioLDM synthesize speech without explicitly training on aligned text-audio pairs. It uses CLAP (Cross-Modal Latent Alignment Pretraining) to create a shared embedding space between both modalities.
Essentially, CLAP teaches the model the intrinsic relationships between textual concepts and their associated acoustic patterns. AudioLDM taps into these co-embeddings, using the audio-side to represent its internal generative model and the text-side to provide conditional inputs that guide the speech output.
This technique gives AudioLDM huge flexibility in synthesizing voices from free-form text prompts. Even for unusual text inputs, the cross-modal embeddings convey informative guidance rooted in the structures of natural speech. In the paper, for example, the creators demonstrate that AudioLDM can create sounds from very unusual text prompts, like "a wolf is singing a beautiful song."
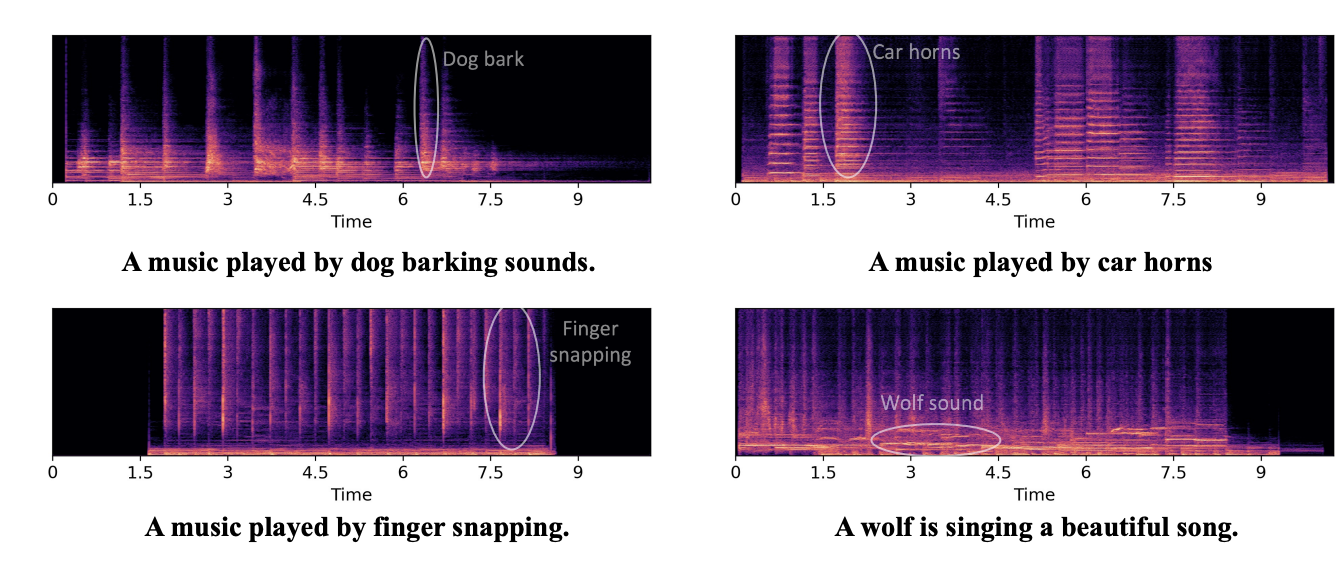
So by breaking conventions with unpaired learning, opening up greater possibilities through continuous latent modeling, and leveraging cross-modal conditioning, AudioLDM manages to unlock new horizons for controllable speech synthesis. Its technical inventiveness has opened exciting doors for creating more immersive, expressive conversational experiences.
AudioLDM's strengths and weaknesses
While AudioLDM demonstrates leading-edge achievements in controllable audio synthesis, it excels better at some tasks than others. Let's examine its capabilities and limitations for critical audio generation use cases.
Diverse Audio Creation and Speech Synthesis
AudioLDM shines at producing novel sound effects and music described in text prompts. Training on diverse datasets like AudioSet equips it to synthesize a wide range of sounds. Its continuous latent space enables smooth interpolations for generating musical notes and transitions. These traits make AudioLDM a versatile tool for audio creators.
Intelligible but Imperfect Speech
For speech synthesis, AudioLDM can generate intelligible voices from text and manipulate attributes like speaker identity based on prompts. It's capable of generating intelligible speech from text and can use attributes like the speaker's identity based on prompts. However, speech quality falls short of specialized state-of-the-art TTS models. Subtleties like emphasis and cadence may not translate accurately, and artifacts are often audible.
Long-Form Audio Still a Challenge
A current limitation is that AudioLDM works best for short clips of up to 10 seconds. Maintaining consistency over longer timescales is difficult as outputs are produced auto-regressively in small steps. Generating coherent long-form audio like podcasts or audiobooks remains an open research problem. You may wish to check into other models for these kinds of applications.
The Nuances of Speech and Data Dependencies
Despite its groundbreaking achievements, AudioLDM struggles with the complexity of human speech. While it can generate a diverse array of voices, it often fails to replicate the subtle emotional nuances and natural cadence inherent to human speech. This means elements like emphasis, sarcasm, and vocal richness are sometimes lost in translation.
Further, AudioLDM's unpaired training scheme, although reducing the need for labeled data, remains a data-hungry beast. The model requires massive quantities of unlabeled audio data for pretraining, which may be beyond the reach of early-stage startups. Data partnerships could offer a solution, but come with their own set of legal and privacy issues.
The complexities of AudioLDM extend beyond data needs. The model's advanced neural architecture demands significant computational resources for training, which can pose a challenge for startups with limited hardware capabilities. While cloud-based AI services could offset these demands, they would inevitably incur considerable costs.
Precision Editing Limitations
As a generative model, AudioLDM is designed for stochastic synthesis rather than precise audio editing. Operations like voice conversion or sound filtering require specialized techniques beyond their capabilities. If editing precision is needed, AudioLDM may not suffice in its current form.
Black Box Outputs
Like many neural networks, the internal workings of AudioLDM are opaque. This makes debugging quality issues and diagnosing unintended biases in the synthesized voices more difficult. Mechanisms to peek inside the black box and gain insight into failure modes would aid responsible development.
By knowing about these limitations, you can make informed decisions about integrating AudioLDM into products, and direct research efforts towards mitigating the vulnerabilities. AI advances like AudioLDM inevitably bring new challenges alongside their benefits. Keeping grounded about their shortcomings is crucial to steer progress in the right direction.
Comparing Apples to Apples: AudioLDM Vs. the Rest
There are several AI models for generating audio from text prompts. Here we'll compare some of the popular options to AudioLDM to help determine the right fit for your needs.
Riffusion
Riffusion uses stable diffusion to generate musical audio in real-time. It's useful for building things like interactive music apps. AudioLDM can also create music, but isn't specialized for real-time generation. Consider Riffusion if you need dynamic, improvisational music.
Musicgen
Musicgen converts text prompts into musical compositions. This makes it useful for assisting musicians, composers, or music students. AudioLDM has wider sound synthesis capabilities beyond just music. Musicgen may offer higher quality and more control for music specifically.
Bark
Bark generates realistic speech and sound effects from the text. The speech sounds more natural than AudioLDM and Bark is great to use if you're building voice assistants or audiobooks. The bark is focused on high-fidelity speech, while AudioLDM has a greater diversity of sound effects. Bark may be preferable for voice-centric applications.
Tortoise TTS
Tortoise TTS converts text to natural-sounding speech. Like Bark, it's useful for voice assistants, audio books, and speech synthesis. Tortoise TTS specializes in human-like voices, but AudioLDM enables greater voice control and variation. Choose based on speech quality needs.
Summary
For specialized music generation, consider Riffusion or Musicgen. For voice-centric applications, Bark or Tortoise TTS may be ideal. AudioLDM provides versatile sound synthesis and voice control, but less focus on tailored domains.
Here is a comparison table for the audio generation models, using data from AIModels.fyi.
| Model | Creator | Cost per Run | Avg Run Time | Hardware | Use Cases |
|---|---|---|---|---|---|
| Riffusion | riffusion | $0.0066 | 12 seconds | Nvidia T4 GPU | Real-time music generation, interactive music apps |
| Musicgen | joehoover | $0.0943 | 41 seconds | Nvidia A100 GPU | Assisting musicians, composers, music students |
| Bark | suno-ai | $0.0297 | 54 seconds | Nvidia T4 GPU | Voice assistants, audio books, sound effects |
| Tortoise TTS | afiaka87 | - | - | Nvidia T4 GPU | Voice assistants, audio books, speech synthesis |
Wrapping Up: Is AudioLDM the best model for your text-to-audio product?
AudioLDM demonstrates cutting-edge innovation in controllable audio synthesis. Its novel techniques open up new creative possibilities that were once inconceivable. However, as with any new technology, there are tradeoffs to weigh before integrating it into products.
Consider these key questions:
- Does your application require specialized music generation or exceptionally natural speech? Models like Riffusion, Musicgen, Bark, and Tortoise TTS may be better suited.
- Can you accommodate AudioLDM's heavy data and compute requirements? If not, opt for lighter and more accessible alternatives.
- Is precision editing critical? AudioLDM is better for generative use cases than editing workflows.
- Are model interpretability and transparency important? AudioLDM's "black box" nature may pose challenges.
- Does your team have ML ops maturity to responsibly develop with AudioLDM? If not, you may be able to leverage a model hosting provider or platform like Replicate, but at an increased cost.
- Are your end goals focused on niche audio domains? More specialized models could be a better fit.
By weighing these key factors against the breakthrough capabilities AudioLDM provides, you can determine if now is the right time to pilot it in your products. With diligent evaluation, you can strategically harness AudioLDM's power to provide delightful user experiences and disrupt industries. Remember that AI models are improving all the time, and future advances may change key factors that could tip the scales in favor of implementing this model. Be sure to keep a close eye on models like this one to see how they improve and change. Thanks for reading!
Subscribe or follow me on Twitter for more content like this!
Resources and Further Reading
You might find some of these other articles interesting or helpful in your quest to build your AI project.
- Converting Speech into Text with OpenAI's Whisper Model - Overview of the Whisper speech-to-text model.
- Audio LDM: AI Text to Audio Generation with Latent Diffusion Models - Explains how AudioLDM synthesizes speech and sound from text.
- Learn How to Harness the Power of AI for Lip Syncing Videos - Guide to making your friends lip sync with AI models.
- Real-ESRGAN vs. Real-ESRGAN: From Theoretical to Real-World Super Resolution with AI - Compares image upscaling models. Another technical dive similar to this one.
- Comparing Bark and Tortoise TTS - A comparison of two similar models that generate audio from text.
Subscribe or follow me on Twitter for more content like this!


Comments ()