
Thought Propagation: Teaching LLMs to Solve Complex Reasoning Tasks with Analogies
Humans solve complex and novel problems using analogies. Can LLMs do the same?
Large language models (LLMs) such as GPT-3, PaLM, and GPT-4 have demonstrated impressive natural language processing abilities. When prompted with examples, they can carry out textual reasoning, finish stories, answer questions, and more. However, their reasoning capabilities still lag behind humans in critical ways. LLMs struggle with complex, multi-step reasoning challenges that require finding optimal solutions or long-term planning.
Recent research from Yale University and the Chinese Academy of Science proposes an innovative technique called "Thought Propagation" to enhance LLMs' reasoning through analogical thinking. This approach shows significant promise in overcoming the inherent limitations of large language models' logic capabilities.
Subscribe or follow me on Twitter for more content like this!
The Promise and Limits of Large Language Models
The advent of giant neural network models like GPT-3 with over 175 billion parameters marked a major milestone in natural language processing. Their foundation is "self-supervised" pre-training on massive text corpora, enabling them to model the statistics of human language impressively.
Early demonstrations showed LLMs' few-shot learning ability. When given just a handful of textual examples, they could perform tasks like translation, summarization, and question answering. Their skills could also be expanded to programming, math, and common sense reasoning with the right prompts.
However, LLMs have clear limitations. They have no true understanding of language or concepts. Their knowledge comes solely from recognizing patterns in their training data. As statistical models, they have difficulty with complex compositional generalization.
Most importantly, LLMs lack systematic reasoning abilities. They cannot carry out the step-by-step deduction that allows humans to solve challenging problems. LLMs' reasoning is local and "short-sighted", making it hard for them to find optimal solutions or maintain consistent reasoning over long time scales.
This is manifest in failures on tasks like mathematical proof, strategic planning, and logical deduction. Their defective reasoning stems from two core issues:
- Inability to reuse insights from prior experience. Humans intrinsically build up reusable knowledge and intuition from practice that aids in solving new problems. In contrast, LLMs tackle each problem "from scratch" without drawing on prior solutions.
- Compounding errors during multi-step reasoning. Humans monitor their reasoning chains and revise initial steps when needed. But errors made by LLMs in early stages of inference get amplified as they steer later reasoning down wrong paths.
These weaknesses significantly hamper LLMs on complex challenges requiring global optima or long-term planning. New methods are needed to overcome these systematic flaws.
(Related reading: Can LLMs self-correct their own reasoning? Probably not.)
Thought Propagation: Reasoning Through Problem Analogy
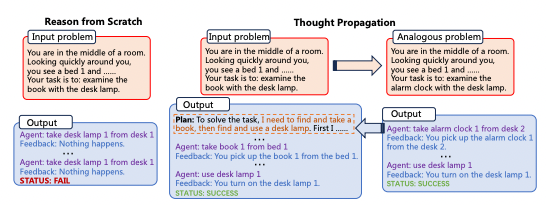
The Thought Propagation (TP) model proposed in the paper mentioned above aims to augment LLMs' reasoning through analogical thinking. The approach is inspired by human cognition: when faced with a new problem, we often compare it to similar problems we've already solved to derive strategies.
The core premise is prompting the LLM to explore "analogous" problems related to the input before solving it. Their solutions can provide insights to either directly solve the input or extract useful plans to follow.
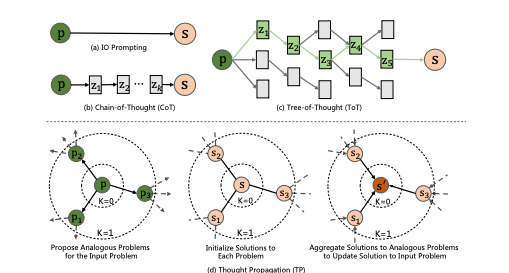
Concretely, Thought Propagation involves 3 stages:
- Propose analogous problems. The LLM is prompted to generate a set of analogous problems that share useful similarities with the input problem. This guides the model to retrieve potentially relevant prior experience.
- Solve the analogous problems. Existing prompting techniques like chain-of-thought are used to have the LLM solve each analogous problem.
- Aggregate the solutions. The solutions are combined in two ways.One: Directly infer a new solution for the input problem based on the analogical solutions. Two: Derive high-level plans or strategies by comparing the analogical solutions to the input problem
This enables reusing prior experience and heuristics. The model can also cross-check its initial reasoning against analogical solutions to refine them.
Thought Propagation is model-agnostic and can build on any prompting approach for the individual problem-solving steps. The key novelty is eliciting analogical thinking to bootstrap the complex reasoning process.
Evaluating Thought Propagation
The researchers tested Thought Propagation on three challenging reasoning tasks:
- Shortest path problems. Finding optimal paths between nodes in graphs requires global planning and search. Standard techniques fail even on simple graphs.
- Story writing. Generating coherent, creative stories is an open-ended challenge. LLMs often lose consistency or logic when given high-level outline prompts.
- Long-term planning for LLM agents. LLM "agents" that interact with text environments struggle with long-term strategies. Their plans drift or get trapped in loops.
Thought Propagation significantly boosted performance across different LLMs:
- In shortest path tasks, it increased finding the optimal path by 15% over baselines
- For story writing, it raised coherence scores by ~2 points
- In LLM planning, it improved task completion rates by 15%
- It even exceeded sophisticated methods like chain-of-thought prompting, demonstrating the power of analogical reasoning.
Interestingly, gains are saturated after 1-2 layers of analogical propagation. More layers increased computational costs without much benefit.
Key Insights on Enhancing LLM Reasoning
The Thought Propagation model provides a compelling new technique for complex LLM reasoning. By prompting analogical thinking, it helps overcome inherent weaknesses like a lack of reusable knowledge and cascading local errors.
More broadly, I think this is interesting because it highlights the value of "meta-cognition" for artificial reasoning systems. Having models explicitly reflect on and enhance their own reasoning process leads to collective improvements.
Thought Propagation also opens intriguing parallels with human psychology. Analogical thinking is a hallmark of human problem-solving. Maybe this ability evolved because it confers systematic benefits like more efficient search and error correction. LLMs show analogous advantages through prompted analogy.
However, there are some limitations to these findings. Efficiently generating useful analogous problems is non-trivial, and chaining long analogical reasoning paths can become unwieldy. Controlling and coordinating multi-step inference chains also remains difficult.
But by creatively addressing inherent reasoning weaknesses in LLMs, Thought Propagation provides an interesting. With further development, induced analogical thinking could make LLMs' reasoning far more robust. This demonstrates paths towards more human-like deduction in large language models.
Subscribe or follow me on Twitter for more content like this!


Comments ()