
This Groundbreaking AI Can Translate Any Input into Any Output. Here's Why That Matters.
CoDi is an "any-to-any" model that can take in any kind of data and give you any kind of output. The first of its kind.
AI is getting cleverer, folks. Gone are the days when artificial intelligence could only deal with a single type of input and spit out a single type of output. This is the era of CoDi: a game-changing generative model that can handle a mixed bag of inputs (think text, audio, video, images) and transmute them into any other combination of outputs.
Subscribe or follow me on Twitter for more content like this!
I stumbled across this audacious project via a tweet by Avi Schiffmann, the AI enthusiast whose curiosity knows no bounds.
So, naturally, I felt obliged to take a deep dive into the paper that details this exciting breakthrough. Strap in, because it's one wild ride.
Welcome to the Party, CoDi
So, what's so special about CoDi? First off, this AI powerhouse is more versatile than any generative model we've seen so far. It's not tied down to specific modalities like image-to-image or text-to-text. Oh no, CoDi is a free spirit, as it is an "any-to-any" model. This bad boy takes whatever you give it—language, image, video, audio—and transmutes it into a different modality.
Researchers at the University of North Carolina at Chapel Hill and Microsoft Azure Cognitive Services Research have crafted CoDi to not only manage multiple modalities at once, but to also generate outputs that are not even in the original training data. Now that's what we call punching above your weight.
What's even cooler is that this is all made possible by a novel composable generation strategy, enabling synchronized generation of intertwined modalities. Imagine a video with perfectly synced audio, produced by a machine that's essentially just guessing how they fit together. It's like some kind of AI remix artist.
But How Does It Work?
For those with a thirst for the technical nitty-gritty, CoDi uses a multi-stage training scheme, meaning it can train on a variety of tasks while inferring all sorts of combinations of inputs and outputs. It's like it has the ability to multitask.
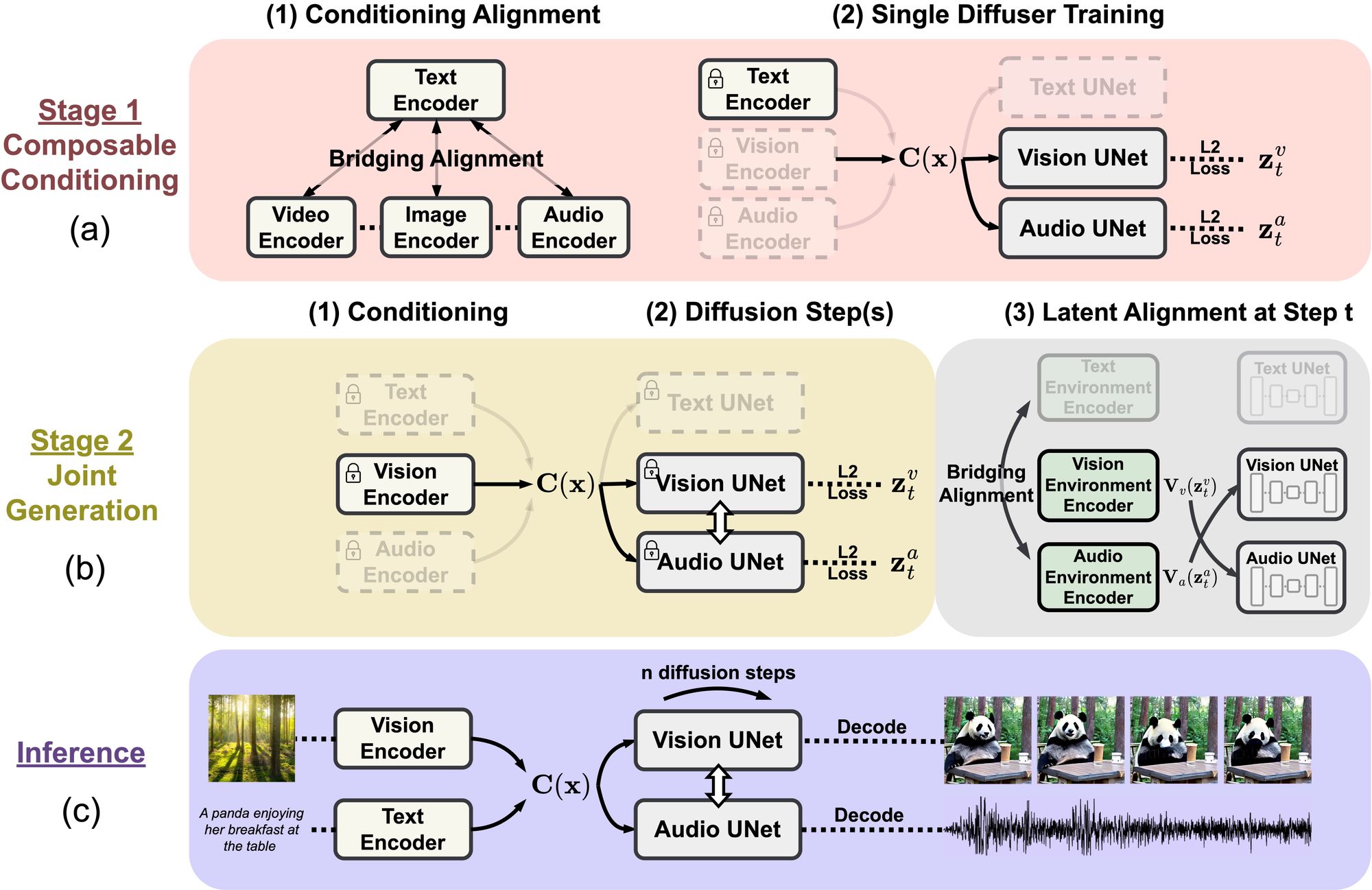
The model's utility is demonstrated in its architecture. The following section is a somewhat-technical summary of the key methods the creators use to get the model working the way they wanted.
Preliminary: Latent Diffusion Model
The foundation of CoDi is a diffusion model, specifically a Latent Diffusion Model (LDM). This form of generative AI learns data distributions by mimicking the diffusion of information over time. During training, it continually adds random noise to the input data, learning to reverse this process and clean the data back to its original form. When it's generating new data, it takes simple noise and denoises it to produce something that looks like the training data.
In the case of LDM, an autoencoder—a type of AI model that can recreate its input—is used to compress the data down into a smaller "latent" form, which is then diffused over time. This process drastically reduces the computational cost and improves the model's efficiency.
Composable Multimodal Conditioning
The unique aspect of CoDi lies in its composable multimodal conditioning. This component allows it to accept any combination of modalities—text, image, video, and audio—as inputs. This is achieved by aligning the input from all these modalities into the same space, which can be conveniently conditioned by interpolating their representations.
To ensure efficient computational operations, a simple technique called "Bridging Alignment" is used. Text is chosen as the "bridging" modality because it is commonly found paired with other modalities, such as text-image, text-video, and text-audio pairs. This method allows the model to align all four modalities in feature space, even when dual modalities like image-audio pairs are sparse.
Composable Diffusion
Training a model that can transform any input into any output is a demanding task requiring substantial learning on diverse data resources. To deal with this, CoDi is designed to be composable and integrative, meaning that individual models for each modality can be built independently and then smoothly integrated later.
For example, an image diffusion model can be used to transfer the knowledge and generation fidelity of an established model trained on large-scale, high-quality image datasets. Similarly, a video diffusion model can extend the image diffuser with temporal modules to model the temporal properties of videos.
In addition, the audio diffuser views the mel-spectrogram of audio as an image with one channel, and a text diffusion model uses a variational autoencoder to compress text data into a smaller latent form, like the other models.
Joint Multimodal Generation by Latent Alignment
The last piece of the puzzle is to allow these independently trained models to work together in generating multiple modalities simultaneously. This is achieved by adding cross-modal attention sublayers to the model. This "Latent Alignment" technique lets each modality-specific model pay attention to the others, projecting their latent variables into a shared space that they can all access.
This design allows for the seamless joint generation of any combination of modalities. For instance, even if only trained for the joint generation of modalities A and B, and B and C, CoDi can achieve the joint generation of modalities A and C without any additional training! Moreover, it can handle the joint generation of modalities A, B, and C concurrently. This versatility is possible because the model has learned to cross-attend between different modalities.
In essence, through these methods, CoDi can efficiently learn to convert any form of input into any other form of output, maintaining high generation quality for all synthesis flows. As a result, it opens up an entirely new realm of possibilities for multimodal AI interactions.
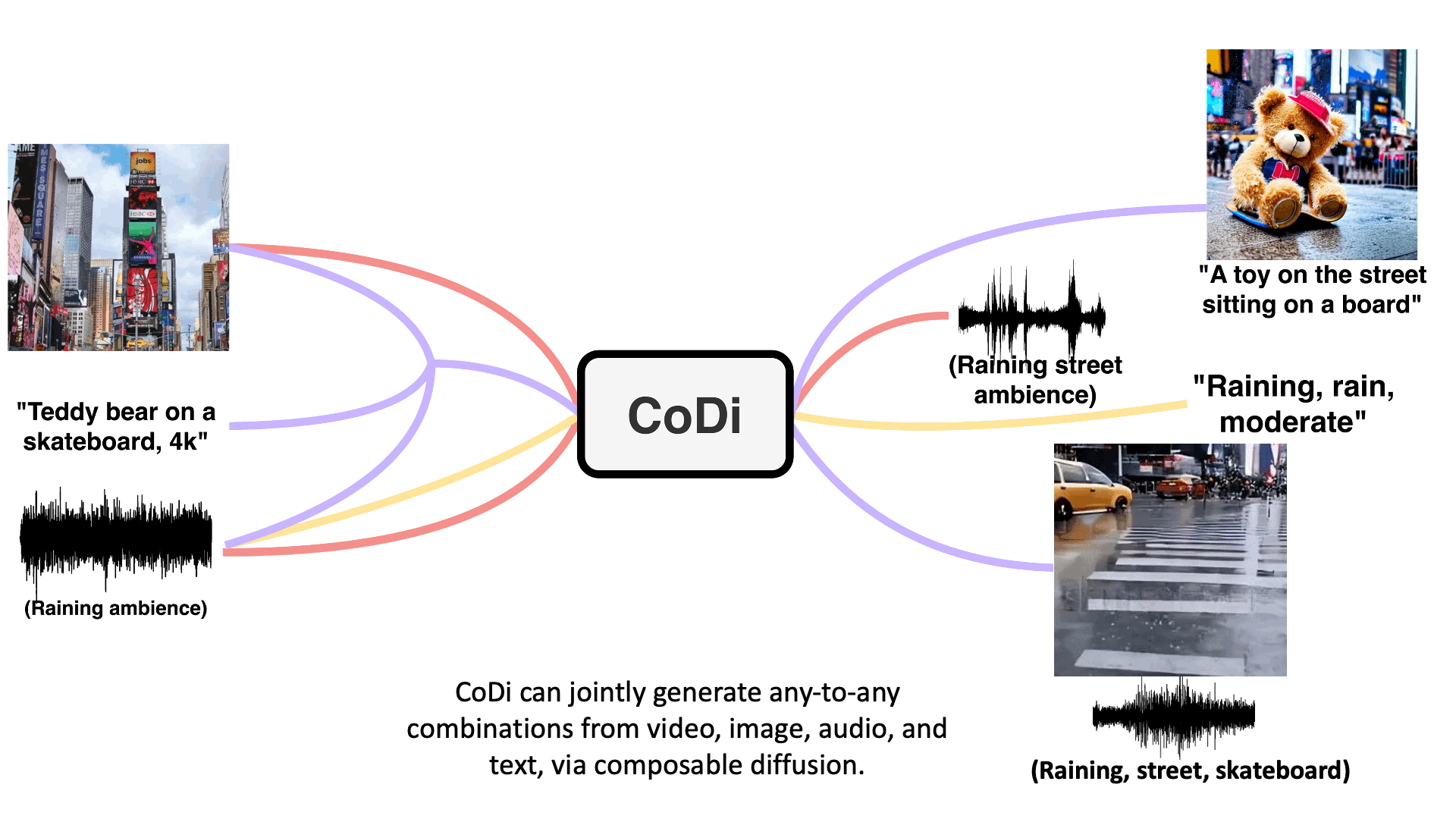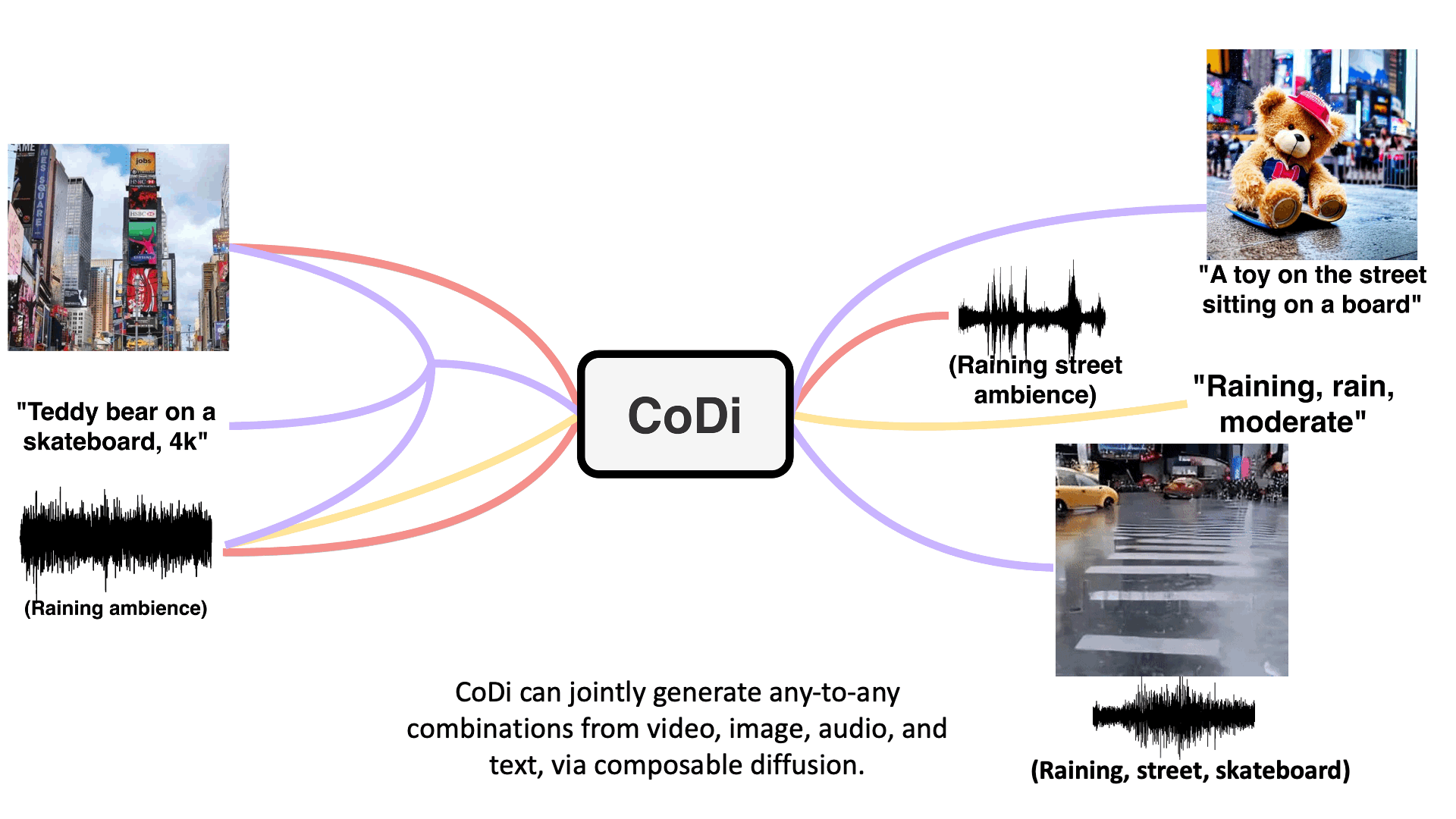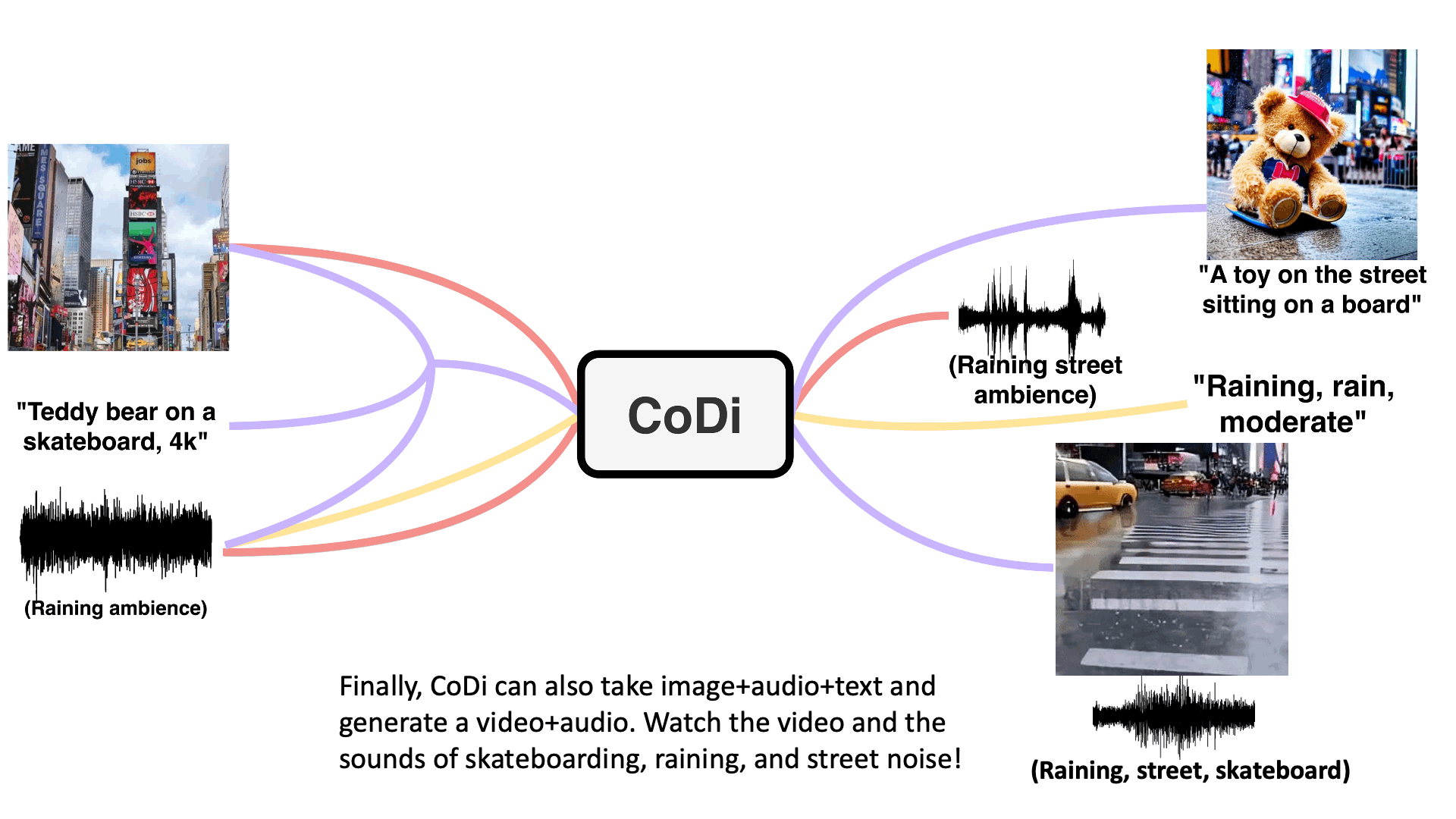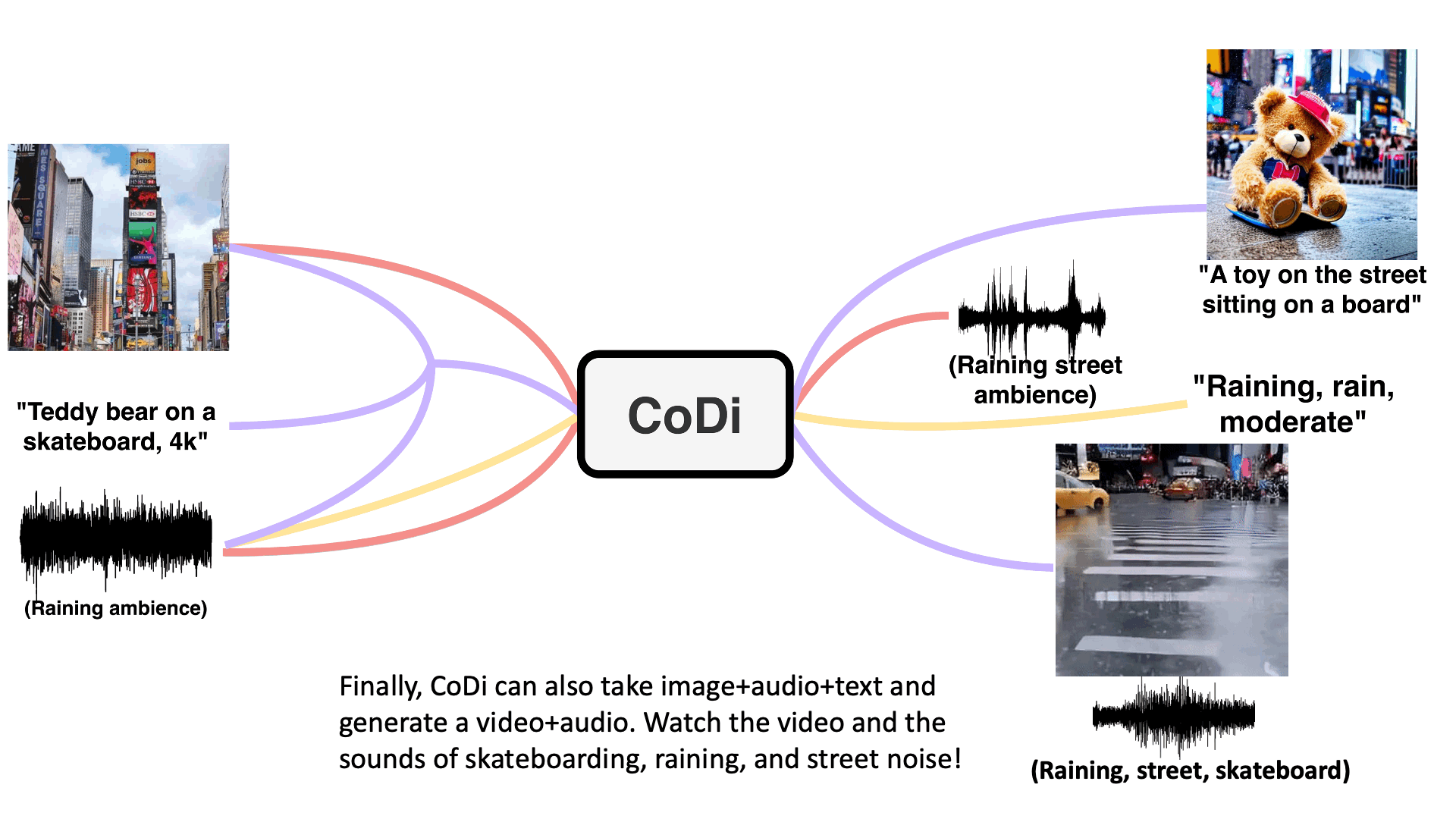
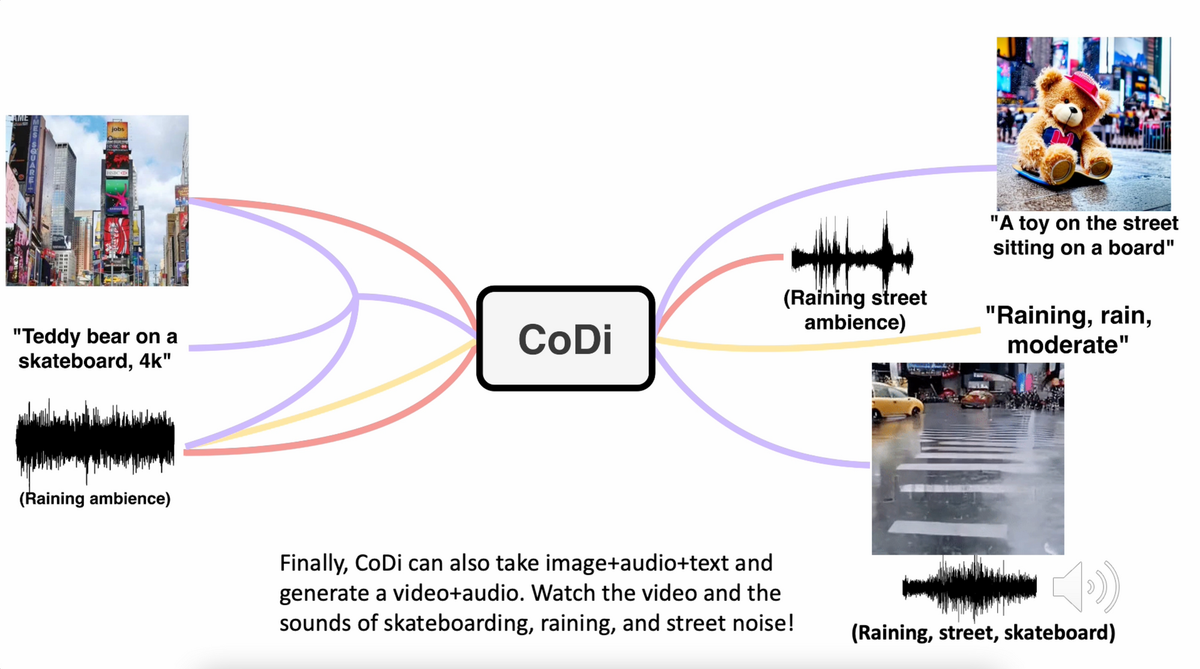
For example, provide CoDi with the text input "Teddy bear on a skateboard, 4k, high resolution" and it can output a video with accompanying sound. Or feed it text and an image with "Cyberpunk vibe" and it can generate text and an image fitting to the given theme.
Example generations are shown below - check the paper for interactive examples.

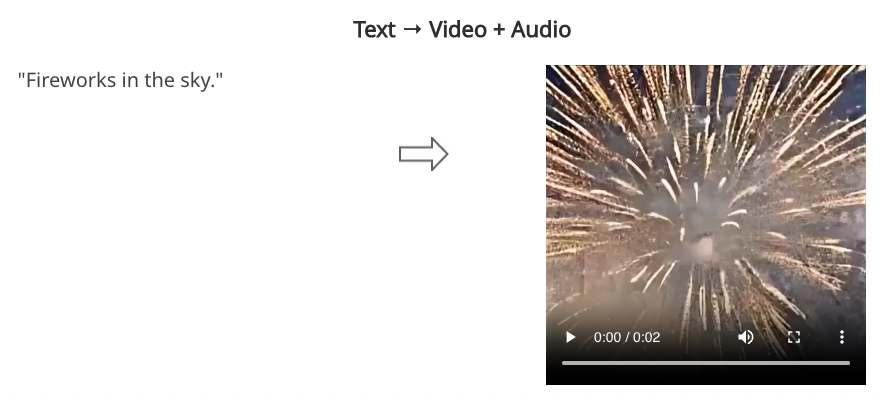
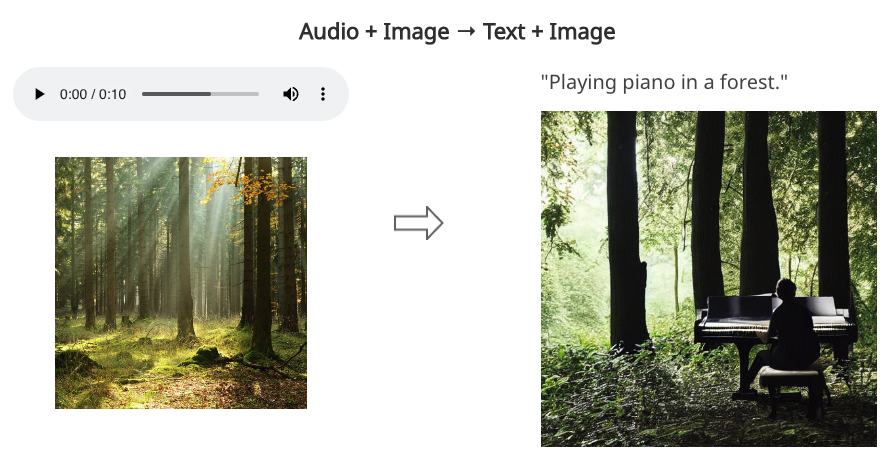
What Does This Mean for Us?
The implications of CoDi's any-to-any generation are vast. In a world that's becoming increasingly digital, having a tool like CoDi means being able to interact with technology in an even more versatile, natural, and human-like way. It could transform everything from virtual assistants to content creation, accessibility tools to entertainment.
But as always, the implications aren't purely utopian. As AI becomes better at generating realistic, multimodal outputs, the need for discerning real from AI-generated content becomes ever more crucial. Misinformation could become more convincing, and deepfakes more prevalent.
But let's not rain on the parade. CoDi is a significant step forward in AI technology, showcasing how far we've come in training machines to understand and recreate the rich tapestry of human communication.
If you want to dig deeper into the mechanics of CoDi, or maybe even experiment with it yourself, you can check out the open-source codebase on GitHub. Who knows what kind of wild transformations you could come up with using CoDi?
In the end, what makes CoDi truly revolutionary is its ability to seamlessly blend different types of data and generate outputs in a way that was previously thought impossible. It's like watching an alchemist at work, turning lead into gold. Except in this case, it's turning any type of input into any type of output. It's truly a remarkable era of AI that we are living in.
Subscribe or follow me on Twitter for more content like this!


Comments ()