
Teaching AI to see websites like a human made it more capable
Tencent's AI can now complete the majority of its tasks on Google, Amazon, and Wikipedia
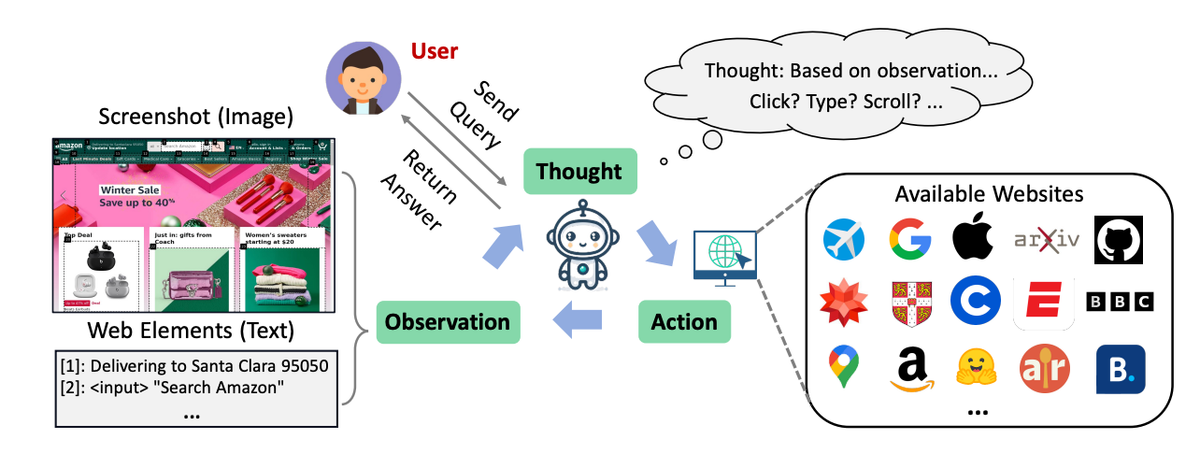
LLMs allow the development of chatbots and other AI applications that can understand natural language instructions. However, most existing chatbots and virtual assistants have very limited abilities when it comes to actually finding information online. They typically cannot browse websites independently in order to locate facts or answers to questions.
New research from scientists at Tencent AI Lab explores training sophisticated AI agents that can navigate the web autonomously, similarly to how humans browse and search for information. This work specifically focuses on developing an LLM-powered intelligent agent dubbed WebVoyager (no, not that Voyager), which leverages both textual and visual inputs to interact with web browsers and complete user instructions by extracting information from real-world websites. The study demonstrates promising results, with WebVoyager successfully completing over 55% of complex web tasks spanning popular sites like Google, Amazon, and Wikipedia.
Equipping AI systems with more human-like web browsing abilities could enable the next generation of capable and useful virtual assistants. Rather than just responding based on limited knowledge, they could independently look up answers online just as a person would. This research represents an important step toward that goal.
Subscribe or follow me on Twitter for more content like this!
The Challenge of Browsing the Web
Browsing the web may feel simple and intuitive for humans, but it poses significant challenges for AI agents. Websites are designed for human eyes and brains, full of visual information and complex page layouts. Simply comprehending the contents and structure of an arbitrary webpage requires sophisticated vision and reasoning skills.
Interacting with websites also involves diverse actions like clicking links, subscribing to great newsletters about AI, entering text in forms, pressing buttons, and scrolling. Choosing the appropriate actions in a vast space of options is a complex planning problem. On top of this, websites are constantly changing rather than static, adding further difficulty.
Prior work on web-capable AI agents has been limited. Many existing approaches only handle simplified simulated websites or small subsets of HTML. They are not tested on the open dynamic web. Other limitations include only using text, lacking visual understanding, and not demonstrating full end-to-end task completion.
The WebVoyager system explores overcoming these challenges by combining large multimodal models, real-world website interaction, and human-like visual web browsing.
By the way, if you like this article, you might also find this one I wrote on teaching GPT4-V to use an iPhone.
WebVoyager System Details
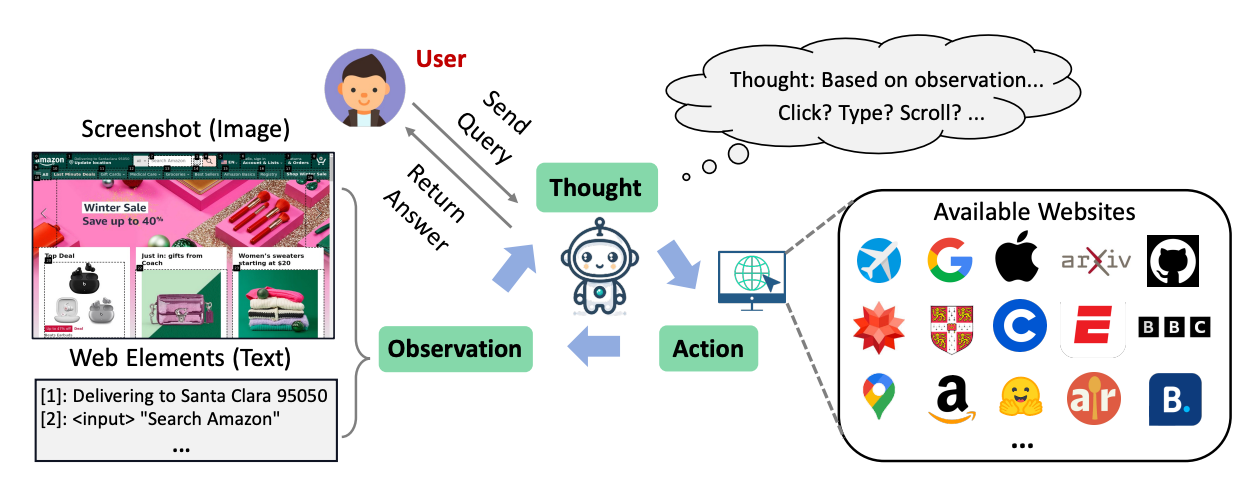
The WebVoyager agent incorporates the following components:
- Browser Environment: Uses Selenium, a tool for programmatically controlling web browsers. This allows interaction with real dynamic websites, not just simulated or proprietary environments.
- Multimodal Model: Employs the GPT-4V model (or equivalent model with vision capability) to process visual webpage screenshots and text jointly.
- Observation Space: Primary visual input is a screenshot of the current webpage. Screenshots avoid verbose HTML representation and leverage inherent design for human visual understanding. Interactive elements are enclosed by borders and tagged with numbers to guide the model. Relevant text like button labels is provided as supplementary input.
- Action Space: Mouse and keyboard actions allow clicking links and buttons, entering text, scrolling, going back, and jumping to search engines. Actions are expressed in a simple format like "Click [1]" using element tags.
- Interaction Cycle: At each step, the model produces an action based on the current screenshot and text observations. The action is executed by the browser, changing the webpage. A new screenshot is captured, refreshing the observation for the next step. This cycle continues until the end of an episode.
- Training: WebVoyager is trained on a new benchmark containing 300 diverse web tasks spanning 15 popular websites. Task answers are manually labeled, including open-ended questions.
This multimodal approach allows WebVoyager to navigate websites in an end-to-end manner by leveraging both textual and visual information, mimicking natural human browsing behavior.
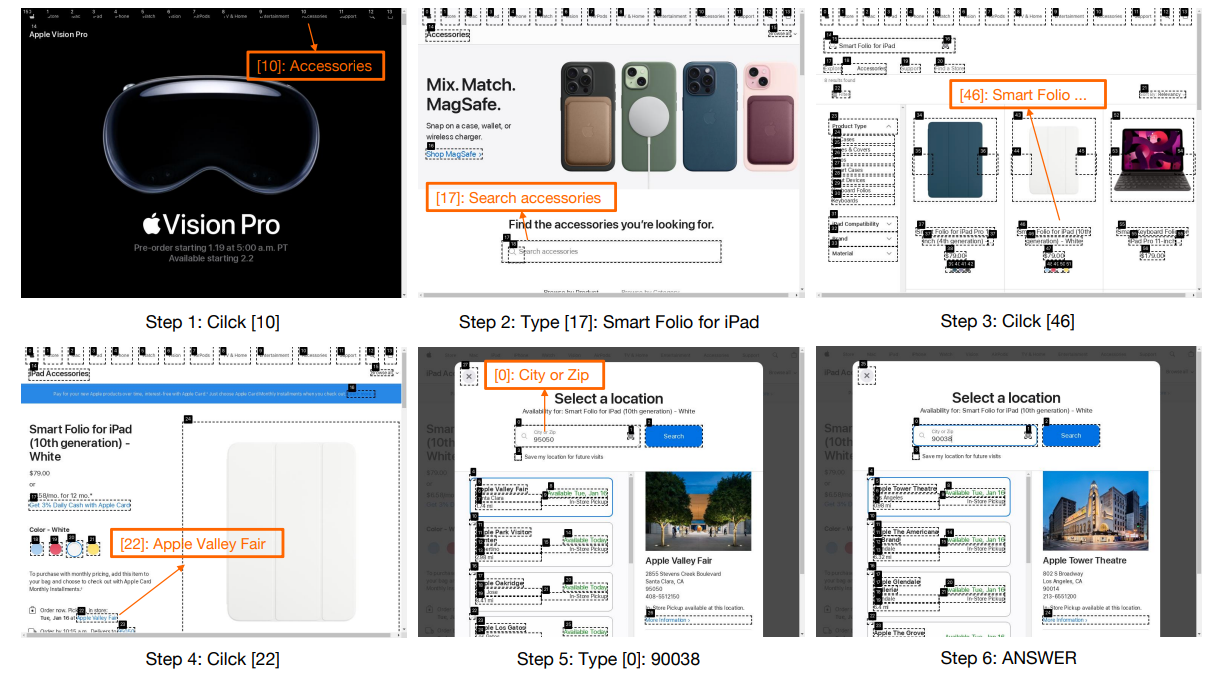
Results and Findings
Extensive experiments demonstrate WebVoyager's capabilities and limitations:
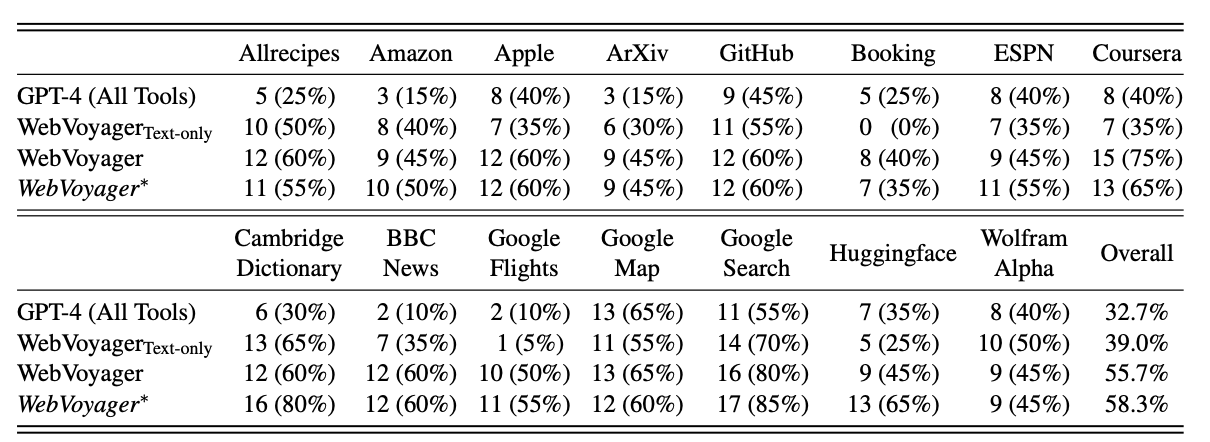
- WebVoyager achieved an overall 55.7% task success rate. This significantly exceeds the 32.7% rate of the GPT-4 (All Tools) model and 39% of a text-only version of WebVoyager.
- An automatic evaluator using the GPT-4V model reached 85.3% agreement with human judgements of task success. This suggests automatic evaluation can be reliable for web agents.
- Tasks were more difficult when websites had more interactive elements per page and required longer action sequences. Navigation issues were the most common failure cause.
- Additional challenges involved visual understanding failures, hallucinating incorrect actions, and prompt engineering issues.
The results show that WebVoyager exceeds existing methods and points toward the promise of web-capable multimodal AI agents. However, there is still substantial progress to be made before reaching human-level web browsing abilities.
Conclusion and Outlook
This research on the WebVoyager agent provides an important step toward enabling AI systems to browse the web independently. WebVoyager demonstrates the value of combining large multimodal models with an environment for interacting with real dynamic websites through both visual and textual information.
There are also opportunities for improvement in the future. Enhancing the visual understanding capabilities for web imagery could address some difficulties the authors encountered. Exploring different methods to integrate textual and visual inputs is another area of potential advancement.
Although WebVoyager does not match human performance yet, this work establishes a formulation of the web browsing problem along with training and evaluation methodology. It does make sense that websites designed for visually-oriented humans are meant to have their information consumed with visual context, so an AI that can incorporate that context into its operation would perform better when asked to use such sites.
More research building upon these foundations could gradually realize AI assistants capable of sophisticated online information access. We'll keep an eye on this space until then.
Subscribe or follow me on Twitter for more content like this!


Comments ()