
ALMT: Using text to narrow focus in multimodal sentiment analysis improves performance
A new way to filter multimodal data for sentiment analysis using text guidance improves performance
Sentiment analysis, the capability to understand human emotions and attitudes, is a vital technology for natural language processing. Sentiment analysis has traditionally relied on textual data, but multimodal sentiment analysis has emerged as an active research area in recent years. Multimodal sentiment analysis aims to better model human sentiment by incorporating diverse modalities beyond just text, such as audio, video, and physiological signals. However, combining multiple modalities introduces new challenges, especially around irrelevant and conflicting information across modalities. In this blog post, we dive deep into a new technique called Adaptive Language-guided Multimodal Transformer (ALMT) that tackles these challenges by filtering multimodal signals under text guidance.
Subscribe or follow me on Twitter for more content like this!
The Promise and Pitfalls of Multimodality
Humans express sentiments through multiple intertwined channels, including language, vocal intonations, facial expressions, gestures, and more. Multimodal systems attempt to capture this complexity by analyzing text, audio, and video inputs together. The promise is that additional modalities like vocal tone and facial cues provide complementary signals that text alone misses. This should improve fine-grained understanding of sentiments beyond what words explicitly convey.
However, simply combining inputs from different modalities via naive fusion is insufficient. Not all signals from audio, video or other sources are equally useful for sentiment analysis. In fact, much of this information may be irrelevant or even misleading:
- Visual data like scene background, lighting, head pose may not correlate with sentiment
- Audio noise from environmental sounds can distract from vocal tone
- Conflicting signs like smiling while saying something negative
Prior multimodal sentiment analysis methods do not explicitly account for such irrelevant or conflicting information. As a result, incorporating poorly filtered data from non-text modalities often hurts performance compared to just using text, as consistently shown across multiple benchmark datasets. Effectively handling irrelevant and conflicting signals is thus crucial to realizing the promise of multimodality.
Adaptive Hyper-Modality: Guiding Relevant Fusion
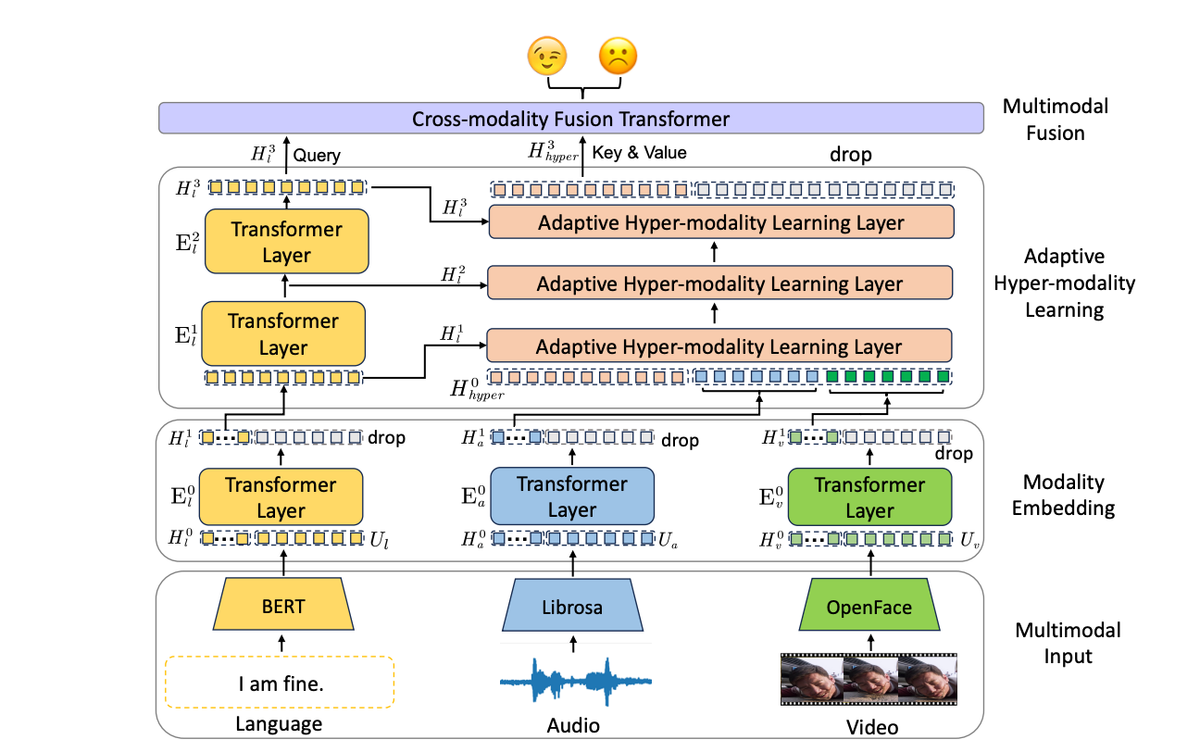
Recent research from Harbin Institute of Technology and Shenzhen Institute of Artificial Intelligence introduces ALMT, a novel framework to address these challenges. ALMT extracts multimodal features through a specialized pipeline that filters signals under guidance from the dominant text modality.
The ALMT Pipeline
The ALMT pipeline has three key stages:
- Modality Encoding: Apply Transformer encoders to each input modality separately. This distills the information into a unified embedding space while reducing redundancy.
- Adaptive Hyper-Modality Learning: Guide the filtering of audio and visual features using different scales of text features. Creates a hyper-modality containing mostly complementary signals.
- Multimodal Fusion: Fuse text and hyper-modality features using the text as queries for a cross-modality Transformer. Allows implicit reasoning of relationships between modalities.
Adaptive Hyper-Modality Learning
The most innovative component of ALMT is the Adaptive Hyper-Modality Learning module. This is responsible for creating the filtered hyper-modality representation under guidance from textual signals.
Multi-scale text feature vectors are first generated using Transformer layers. These guide the filtering of audio and visual features through an attention mechanism. The text features act as queries while the audio and visual features are keys and values. This surfaces the parts of audio and visual inputs that are relevant to the textual context.
Weighted combinations of these relevant audio and visual signals are aggregated iteratively into the hyper-modality representation. By adaptively focusing on complementary subsets guided by text, this hyper-modality contains much less distracting information.
Significance for Multimodal Fusion
The text-guided hyper-modality is a key enabler for effective fusion in the final stage. Using the text features as queries grounds the hyper-modality in the dominant sentiment signals. The hyper-modality in turn provides a filtered source of complementary information.
This prevents irrelevant or conflicting audio-visual data from polluting the joint representations used for sentiment prediction. The approach is intuitive yet powerful for robust multimodal understanding.
Empirical Advances Across Diverse Datasets
Extensive experiments demonstrate the effectiveness of ALMT for filtering multimodal signals on diverse sentiment analysis datasets:
- MOSI: YouTube movie reviews with 2,199 samples. ALMT achieves state-of-the-art on various metrics including 6% higher 7-class accuracy.
- MOSEI: 22,856 YouTube clips covering sentiment-rich scenarios. ALMT improves multi-class accuracy by 3-5% over previous methods.
- CH-SIMS: Chinese dataset with over 2,000 video samples. ALMT surpasses prior work by 1.4% in binary accuracy.
The significant gains across datasets with distinct characteristics showcase ALMT's ability to extract relevant multimodal signals. Using text guidance to filter audio and visual data results in robust hyper-modality representations.
Analyses also confirm the validity of the approach. Performance drops drastically without the Adaptive Hyper-Modality Learning, validating it's needed. Attention visualizations in the papers' figures show the module focuses on complementary video regions rather than irrelevant cues. ALMT also converges faster and more stably during training.
Key Takeaways and Limitations
My highlights from the paper:
- Naive combination of modalities can be worse than text-only modeling due to irrelevant/conflicting signals.
- Filtering under guidance from the dominant text modality extracts useful complementary information. Less is sometimes more.
- Hyper-modality representation learning is a promising technique for robust multimodal understanding.
Of course, the work has limitations that provide opportunities for future work. ALMT relies heavily on large Transformer architectures that require abundant data to train properly. Performance gains are smaller on sparse regression metrics that need more data. Collecting larger multimodal sentiment datasets could help unlock ALMT's full potential.
Subscribe or follow me on Twitter for more content like this!


Comments ()