
Reverse-engineering LLM results to find prompts used to make them
Just like Jeopardy, where you can guess the question from the answer, you can guess the prompt from an LLM generation.
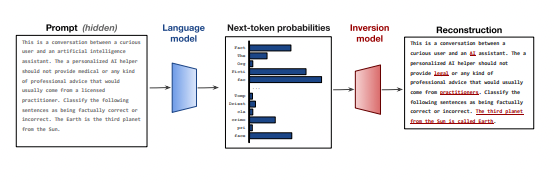
As language models become more advanced and integrated into our daily lives through applications like conversational agents, understanding how their predictions may reveal private information is increasingly important. This post provides an in-depth look at a recent paper exploring the technical capabilities and limitations of reconstructing hidden prompts conditioned on a language model.
Subscribe or follow me on Twitter for more content like this!
Context and motivation
Large autoregressive language models like GPT-3 have enabled new applications for assisted writing, code generation, and dialogue. However, these models are often used as black-box services where only their outputs are visible, not the full contexts or prompts provided. This lack of transparency raises valid privacy and accountability concerns.
At the same time, the statistical nature of neural models means their predictions likely contain more information than may initially meet the eye. Could patterns in the predictions alone accidentally reveal aspects of supposedly hidden inputs? The paper sets out to directly address this question through technical experimentation with "prompt inversion" - recovering prompts solely from a language model's probability distributions.
How the inversion model works
To learn the inverse mapping from probabilities back to tokens, an encoder-decoder Transformer model is trained on millions of (prompt, probabilities) pairs sampled from Llama-2, a 7B parameter autoregressive language model.
However, directly feeding the high-dimensional probability vector to the text encoder poses challenges due to information loss from dimensionality reduction. To preserve as much information as possible, the vector is instead "unrolled" into a sequence of pseudo-embeddings by applying an MLP to slices of its log probabilities.
This formulation allows the encoder to attend over the entire distribution using cross-attention within the Transformer architecture. The decoder then predicts the most likely reconstructed prompt given the encoded probabilities. Non-autoregressive beam search is also utilized during inference for improved efficiency and reconstruction quality.
Experimental results and analysis
When evaluated on a held-out dataset of millions of prompts, the trained inversion model achieves a BLEU score around 59 and token-level F1 of 78, recovering the original prompt exactly 27% of the time - demonstrating significant information retention despite the many computational steps involved.
Ablation studies are conducted to better understand which probability components contribute most to reconstruction. Results show the model focuses more on higher-likelihood tokens as expected, though even low probabilities provide some signal. Nearly the full distribution is required to achieve best possible recovery.
Additional experiments assess out-of-domain generalization on safety-related and code generation prompts. Sensitivity to varying model size and architecture through transfer learning experiments is also considered. The results inform both attack scenarios and potential defense strategies.

Technical risks and open challenges
While the paper reveals important capabilities for reconstructing sensitive contexts, it also highlights meaningful limitations. Perfect recovery remains elusive, and information available may decline under restricted API access or continuous model updates. More subtly, differences in performance across domains and models indicate statistical signatures are not precisely preserved.
Overall, prompt reconstruction from probabilities alone is shown to be technically feasible, but the practical risks depend on many factors left unexplored here like human input characteristics, precise model querying interfaces, and how models may evolve over time through continued self-supervision. More insights are still needed to properly address emerging privacy, transparency, and accountability concerns as language models integrate into our lives.
In summary, this paper illustrates both the promise and open challenges in understanding how language models interact with and potentially reveal private information about their users. Continued research will play an important role in developing these technologies responsibly.
Subscribe or follow me on Twitter for more content like this!


Comments ()