
Prompting with unified diffs makes GPT-4 write much better code
A developer for an open-source paired-programming tool discovered the trick
Artificial intelligence has shown increasing potential to aid software developers, with large language models like GPT-3 and GPT-4 demonstrating an ability to generate and edit code. AI coding assistants could significantly boost programmer productivity.
However, as we all know, these AI systems also exhibit frustrating “lazy coding” behaviors, where instead of writing full code they insert placeholder comments like “...add logic here...” This tendency toward lazy coding makes AI systems fall short of their full potential, especially on more complex coding tasks. The problem is so significant that it is a frequent top reddit post on subreddits like r/ChatGPT.
In this blog post, we'll take a look at an interesting finding I discovered on a blog for an AI-based paired programming tool called Aider. The creator, Paul Gauthier, found that unified diffs make GPT-4 Turbo less lazy, helping it generate better code and reducing the number of responses that skip over important logic. Let's see what he found and think about how we can take advantage of this finding in our own workflows!
Subscribe or follow me on Twitter for more content like this!
What is Aider?
Aider is an open-source command line tool that lets developers “pair program” with large language models like GPT-3.5 and GPT-4. Aider allows the AI system to directly edit code files in the user’s local git repository via conversational chat.
The developer behind Aider encountered the lazy coding problem described in the introduction when testing the tool on refactoring tasks. This motivated him to find better interfaces to coax diligent coding from the AI.

Benchmarking Lazy Coding
To systematically quantify lazy coding behaviors, Aider's developer created a benchmark suite of 89 Python refactoring tasks designed to provoke the AI into resorting to placeholder comments instead of writing complete code changes.
The benchmark measures how often the AI uses lazy comments like “...include original method body...” as a metric for coding laziness.
The baseline performance for the evaluated GPT models was quite poor:
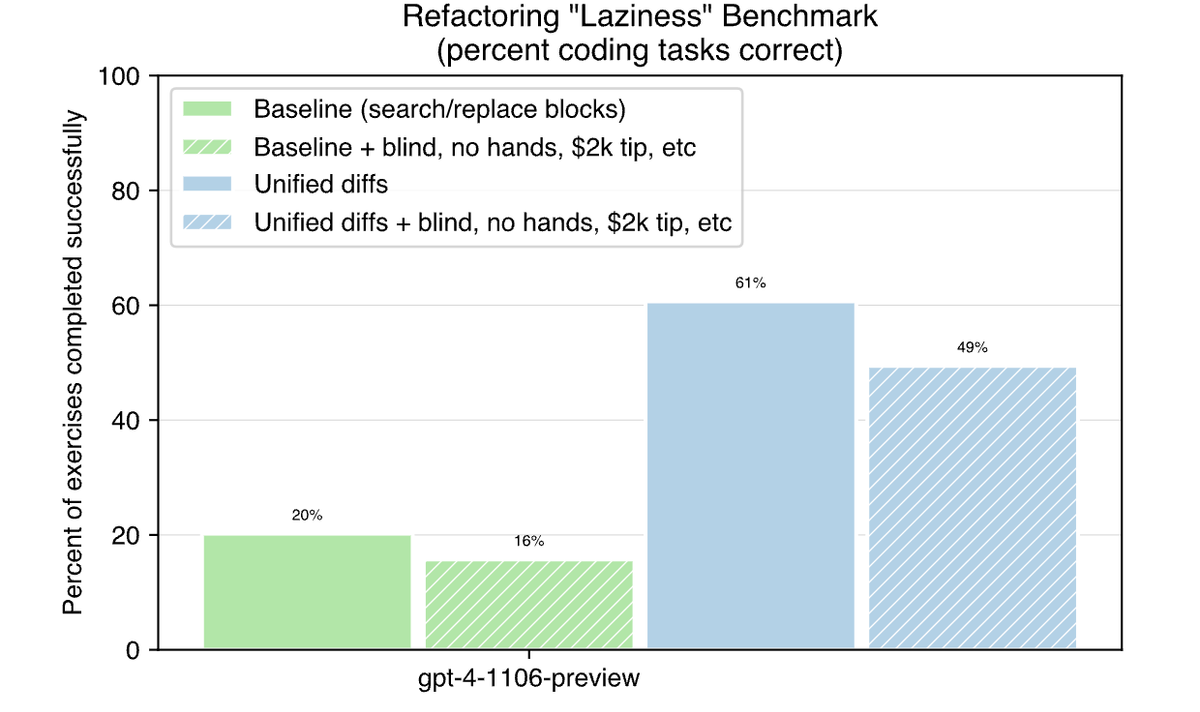
This new laziness benchmark produced the following results with gpt-4-1106-preview:GPT-4 Turbo only scored 20% as a baseline using aider’s existing “SEARCH/REPLACE block” edit format. It outputs “lazy comments” on 12 of the tasks.
Aider’s new unified diff edit format raised the score to 61%. Using this format reduced laziness by 3X, with GPT-4 Turbo only using lazy comments on 4 of the tasks.
It’s worse to add a prompt that says the user is blind, has no hands, will tip $2000 and fears truncated code trauma. Widely circulated “emotional appeal” folk remedies produced worse benchmark scores for both the baseline SEARCH/REPLACE and new unified diff editing formats. [Note that this contradicts another article I wrote covering a stress-based gaslighting approach]
The older gpt-4-0613 also did better on the laziness benchmark using unified diffs:The June GPT-4’s baseline was 26% using aider’s existing “SEARCH/REPLACE block” edit format.
There's also an important caveat on the benchmark's upper limit:
The benchmark was designed to use large files, and 28% of them are too large to fit in June GPT-4’s 8k context window. This puts a hard ceiling of 72% on how well the June model could possibly score.
So, now that a baseline has been established (and isn't too impressive), what was the change for this experiment, and how did it fare?
Unified Diffs - A Familiar Format That Reduces Laziness
Unified diffs are a way of showing differences between two sets of files or text, typically code. They are a standard format output by tools like git diff. They consist of a few key parts: file names, a hunk identifier (with line numbers), and the set of lines with changes prefixed by + (addition) or - (deletion).
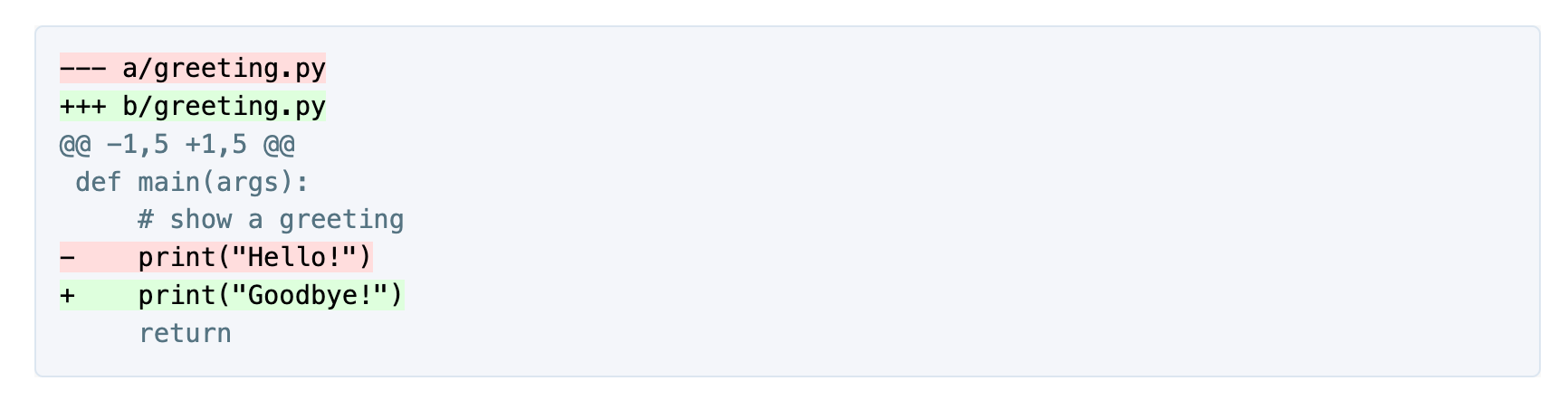
git diff"Unified diffs change the way GPT engages with coding tasks.
"With unified diffs, GPT acts more like it’s writing textual data intended to be read by a program, not talking to a person. Diffs are usually consumed by the patch program, which is fairly rigid. This seems to encourage rigor, making GPT less likely to leave informal editing instructions in comments or be lazy about writing all the needed code."
Instead of providing the AI with a traditional code-editing prompt (like "change this function to say goodbye instead of hello"), the system uses a unified diff as the prompt. This diff represents the desired change. The LLM, trained on a wide array of texts including code and diffs, understands this format and interprets it as instructions for changing code.
When GPT-4 receives the diff, it doesn't "see" code and comments like a human but patterns and structures it has been trained to recognize and generate text for. It recognizes the unified diff pattern and understands that it's being asked to modify code according to the changes specified in the diff format.
GPT-4 then processes this diff and generates the new version of the code accordingly. It replaces, adds, or deletes lines in the original. The adoption of unified diffs in Aider had significantly less "laziness" and more rigor.
The implementation probably worked for a few reasons. Aider's blog suggests the following:
- Familiarity: Unified diffs are a common sight in code versioning, making them a familiar format for GPT due to its extensive exposure in training data. This familiarity reduces the learning curve and increases the efficiency of code editing.
- Simplicity: The format avoids complex syntax or the need for escaping characters. This simplicity ensures the AI can focus on the actual code changes without getting bogged down by formatting issues.
- High-Level Edits: Instead of making minimal changes to individual lines of code, unified diffs encourage GPT to approach edits as new versions of substantial code blocks. This encourages more comprehensive and thoughtful revisions.
- Flexibility: The format allows for a degree of interpretation in GPT's instructions, accommodating the nuances of coding that may not fit neatly into a rigid structure.
Results
In the pursuit of reducing "lazy" coding tendencies in AI, the older GPT-4 model (gpt-4-0613) was put to the test using Aider's refined approach. Initially, the June GPT-4 version showed a baseline performance of 26% when tasked with coding challenges using the "SEARCH/REPLACE block" edit format. However, upon integrating the unified diff edit format, a remarkable improvement was observed. The performance score rose to 59%, indicating a significant reduction in the instances where the AI resorted to lazy coding.
However, we have to note the inherent limitations imposed by the size of the files used in the benchmark. About 28% of the tasks involved files too large for the June GPT-4's 8k context window, effectively capping the maximum possible score at 72%. Despite these constraints, the shift to unified diffs represents a considerable enhancement in coding efficiency, pushing the AI's performance closer to this upper limit.
Conclusion
The shift to unified diffs has proven to be more than just an alternative formatting choice. It fundamentally changes how the AI approaches coding tasks, treating them more like structured data meant for machine interpretation rather than informal, human-readable text. This structural rigor inherent in unified diffs seems to drive the AI towards more disciplined and thorough coding, a marked improvement over other methods and formats explored.
The success with unified diffs suggests a broader implication for AI coding tools. As these tools continue to evolve, there's a clear advantage in leveraging structured, well-understood formats like unified diffs that align well with the AI's learning and operational mechanisms. Fine-tuning models to excel within these formats could further enhance AI's coding abilities, making it a more reliable and efficient partner in coding tasks.
Subscribe or follow me on Twitter for more content like this!


Comments ()