
MemGPT Is Now Letta - What Changed and Why It Matters
Combining an OS-inspired architecture with an LLM for unbounded context via memory paging
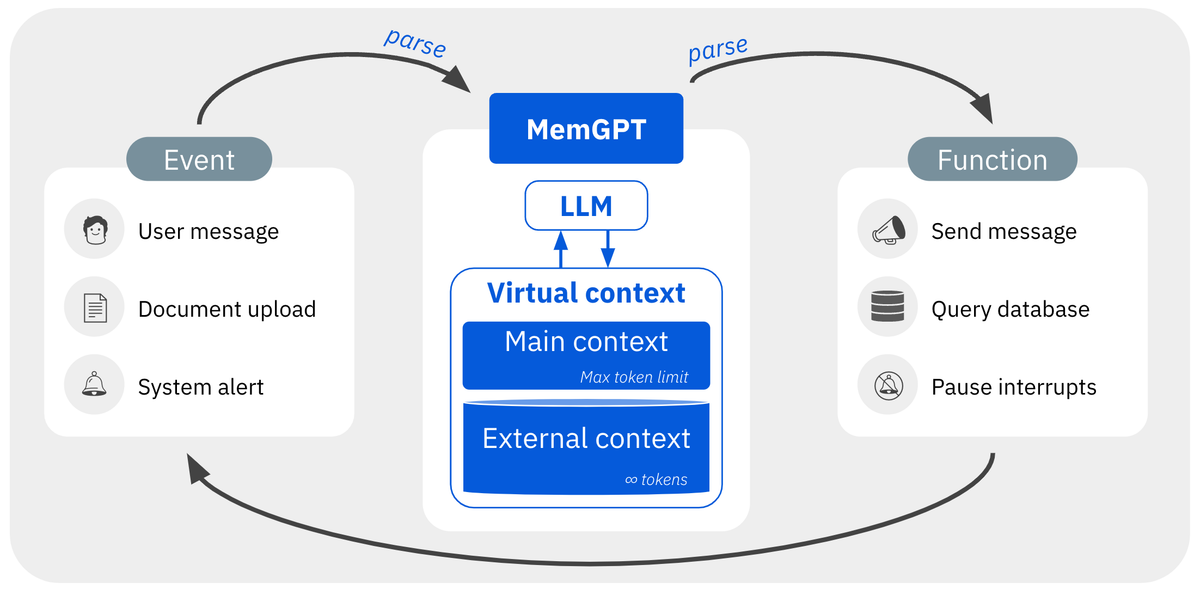
MemGPT did not disappear. It evolved into Letta.
That is the short version. MemGPT is the original research paper and design pattern for managing long-term memory in LLM agents. Letta is the open-source framework and company that grew out of that work. The distinction matters because the project is no longer just a paper implementation. It is now a broader platform for building stateful agents with persistent memory, tools, and external data sources.
When UC Berkeley researchers published the MemGPT paper in October 2023, they framed long-context limitations as a systems problem, not just a model problem. Their proposal was to treat context more like working memory: keep a small active set in the prompt, move less relevant information into external memory, and let the model decide what to store or retrieve through interrupts and memory tools.
On the paper’s Deep Memory Retrieval benchmark, GPT-4 Turbo with MemGPT reached 93.4% accuracy, versus 35.3% for a recursive summarization baseline. That result helped make memory management feel like a concrete engineering problem rather than a vague hope that “bigger context” would solve everything.
MemGPT Became Letta
MemGPT did not stay a research prototype for long. In Letta’s rebrand post, the team explained that the repository had expanded well beyond the original paper. It now supported custom tools, data sources, memory classes, and persistent agents that could be deployed as stateful services.
That created a naming problem. By 2024, “MemGPT” could refer to at least three different things at once:
- the original research paper
- a general pattern for memory-enabled agents
- the open-source framework itself
The team’s fix was simple: keep MemGPT as the name of the original pattern, and rename the framework Letta.
What Letta Is Now
The current open-source project lives at letta-ai/letta, which still describes itself as “Letta (formerly MemGPT)”. But the scope is much broader than the original paper.
Letta now presents itself as a platform for building stateful agents with persistent memory. Its current product surface includes:
- the Letta API
- an Agent Development Environment
- memory blocks and persistent agent state
- support for tools and data sources
- shared memory
- AgentFile, which packages portable agent state
- Letta Code, a coding agent built around persistent memory
That is a bigger claim than the original MemGPT paper made. The paper introduced a memory-management pattern. Letta is trying to turn that pattern into a developer platform.
Why the Rebrand Matters
The rebrand was not just cosmetic. It marked a real shift in what the project had become.
The original MemGPT work was mainly about how an agent should manage memory. Letta is about how developers should build, inspect, deploy, and maintain agents that use memory over time.
That difference matters because memory is not just about storing more tokens somewhere. In real applications, an agent has to decide:
- what should stay in active context
- what should move into long-term storage
- what has gone stale
- what should be shared across agents
- what should persist across sessions
Those are platform problems, not just prompt-design problems. Letta’s current docs are built around exactly those concerns.
Memory Is Now a Product Category
MemGPT helped make agent memory legible. Since then, memory has turned into its own tooling category.
For example:
- LangChain launched LangMem, a memory SDK for agents
- Zep positions itself as a memory layer built around a temporal knowledge graph
- Mem0 focuses on long-term memory for production LLM applications
That shift matters because it changes how MemGPT should be read today. In 2023, the idea of explicit memory management felt novel. In 2026, it is part of a competitive product landscape.
The Benchmark Story Got Messier
MemGPT’s reported 93.4% score on the Deep Memory Retrieval benchmark was part of what made the paper stand out. But later work made that story less tidy.
A follow-up analysis from Zep argued that the benchmark is small and overly retrieval-focused. The paper also reported that a full-conversation GPT-4 Turbo baseline reached 94.4% on the same benchmark, slightly above MemGPT’s published number.
That does not erase MemGPT’s contribution. The original paper still mattered because it made memory evaluation concrete and pushed the field toward more explicit designs. But it does mean the original result should not be read as the final word on whether memory systems are universally better than larger context windows.
The question has shifted. It is no longer just whether a memory system can beat summarization. It is whether memory still adds value when frontier models already have much larger context windows.
What Still Holds Up
That bigger-context question is exactly why MemGPT’s core idea still matters.
Larger windows help, but they do not solve:
- persistence across sessions
- selective retention
- stale or conflicting memories
- tool-use state
- multi-agent sharing
- lifecycle management for long-running agents
The operating-system analogy from MemGPT still holds up surprisingly well: treat the prompt like RAM, treat external storage like disk, and give the agent a way to move information between them intentionally.
That is still a useful way to think about stateful agents, even if the surrounding market and benchmarks have changed.
Should You Use “MemGPT” or “Letta” Today?
If you are talking about the research idea, say MemGPT.
If you are talking about the current framework, open-source project, or company, say Letta.
That is the cleanest way to avoid confusion. It also matches how the team now describes the project in the rebrand post, GitHub repository, and docs.
The Bottom Line
MemGPT is the paper and the original memory-management pattern.
Letta is the framework and company that grew out of it.
The idea survived. The product got much bigger. The market filled in with competitors. And the benchmark story turned out to be less definitive than the early summaries made it sound.
The repository is still open source, by the way.


Comments ()