
LLMs can be extended to infinite sequence lengths without fine-tuning
LLMs trained with a finite attention window can be extended to infinite sequence lengths without any fine-tuning.
In recent years, natural language processing has been revolutionized by the advent of large language models (LLMs). Massive neural networks like GPT-3, PaLM, and BlenderBot have demonstrated remarkable proficiency at various language tasks like conversational AI, summarization, and question-answering. However, a major impediment restricts their practical deployment in real-world streaming applications.
LLMs are pre-trained on texts of finite lengths, usually a few thousand tokens. As a result, their performance deteriorates rapidly when presented with sequence lengths exceeding their training corpus. This limitation renders LLMs incapable of reliably handling long conversations as required in chatbots and other interactive systems. Additionally, their inference process caches all previous tokens' key-value states, consuming extensive memory.
Researchers from MIT, Meta AI, and Carnegie Mellon recently proposed StreamingLLM, an efficient framework to enable infinite-length language modeling in LLMs without expensive fine-tuning. Their method cleverly exploits the LLMs' tendency to use initial tokens as "attention sinks" to anchor the distribution of attention scores. By caching initial tokens alongside recent ones, StreamingLLM restored perplexity and achieved up to 22x faster decoding than prior techniques.
The paper they published says it clearly:
We introduce StreamingLLM, an efficient framework that enables LLMs trained with a finite length attention window to generalize to infinite sequence length without any fine-tuning. We show that StreamingLLM can enable Llama-2, MPT, Falcon, and Pythia to perform stable and efficient language modeling with up to 4 million tokens and more.
This blog post explains the key technical findings of this work and their significance in plain terms. The ability to deploy LLMs for unlimited streaming inputs could expand their applicability across areas like assistive AI, tutoring systems, and long-form document generation. However, cautions remain around transparency, bias mitigation, and responsible use of these increasingly powerful models.
Subscribe or follow me on Twitter for more content like this!
The Challenges of Deploying LLMs for Streaming
Unlike humans who can sustain conversations for hours, LLMs falter beyond short contexts. Two primary issues encumber their streaming application:
Memory Overhead: LLMs based on Transformer architectures cache the key-value states of all previous tokens during inference. This memory footprint balloons with sequence length, eventually exhausting GPU memory.
Performance Decline: More critically, LLMs lose their abilities when context lengths exceed those seen during pre-training. For example, a model trained on 4,000 token texts fails on longer sequences.
Real-world services like chatbots, tutoring systems, and voice assistants often need to maintain prolonged interactions. But LLMs' limited context capacity hampers their deployment in such streaming settings. Prior research attempted to expand the training corpus length or optimize memory usage, but fundamental barriers remained.
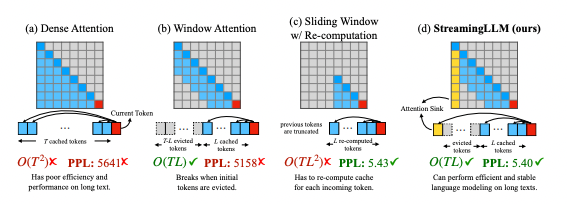
Windowed Attention and Its Limitations
An intuitive technique called windowed attention emerged to mitigate LLMs' memory overhead. Here, only the key-values of the most recent tokens within a fixed cache size are retained. Once this rolling cache becomes full, the earliest states are evicted. This ensures constant memory usage and inference time.
However, an annoying phenomenon occurs - the model's predictive performance drastically deteriorates soon after the starting tokens fade from the cache. But why should removing seemingly unimportant old tokens impact future predictions so severely?
The Curious Case of Attention Sinks
Analyzing this conundrum revealed the LLM's excessive attention towards initial tokens, making them act as "attention sinks." Even if semantically irrelevant, they attract high attention scores across layers and heads.
The reason lies in the softmax normalization of attention distributions. Some minimal attention must be allocated across all context tokens due to the softmax function’s probabilistic nature. The LLM dumps this unnecessary attention into specific tokens - preferentially the initial ones visible to all subsequent positions.
Critically, evicting the key-values of these attention sinks warped the softmax attention distribution. This destabilized the LLM's predictions, explaining windowed attention's failure.
StreamingLLM: Caching Initial Sinks and Recent Tokens
Leveraging this insight, the researchers devised StreamingLLM - a straightforward technique to enable infinite-length modeling in already trained LLMs, without any fine-tuning.
The key innovation is maintaining a small cache containing initial "sink" tokens alongside only the most recent tokens. Specifically, adding just 4 initial tokens proved sufficient to recover the distribution of attention scores back to normal levels. StreamingLLM combines this compact set of anchored sinks with a rolling buffer of recent key-values relevant for predictions.
(There are some interesting parallels to a similar paper in ViT research around registers, which you can read here.)
This simple restoration allowed various LLMs like GPT-3, PaLM and LaMDA to smoothly handle context lengths exceeding 4 million tokens - a 1000x increase over their training corpus! Dumping unnecessary attention into the dedicated sinks prevented distortion, while recent tokens provided relevant semantics.
StreamingLLM achieved up to 22x lower latency than prior approaches while retaining comparable perplexity. So by removing this key bottleneck, we may be able to enable practical streaming deployment of LLMs in interactive AI systems.
Pre-training with a Single Sink Token
Further analysis revealed that LLMs learned to split attention across multiple initial tokens because their training data lacked a consistent starting element. The researchers proposed appending a special "Sink Token" to all examples during pre-training.
Models trained this way coalesced attention into this single dedicated sink. At inference time, providing just this token alongside recent ones sufficiently stabilized predictions - no other initial elements were needed. This method could further optimize future LLM designs for streaming usage.
Conclusion
By identifying initial tokens as attention sinks, StreamingLLM finally enables large language models to fulfill their potential in real-world streaming applications. Chatbots, virtual assistants, and other systems can now leverage LLMs to smoothly sustain long conversations.
However, while this removes a technical barrier, concerns around bias, transparency, and responsible AI remain when deploying such powerful models interacting with humans - infinite context window or not. But used judiciously under the right frameworks, the StreamingLLM approach could open up new beneficial applications of large language models.
Subscribe or follow me on Twitter for more content like this!


Comments ()