
UC Berkeley unveils MemGPT: Applying OS architecture to LLMs for unlimited context
Combining an OS-inspired architecture with an LLM for unbounded context via memory paging
Large language models like GPT-3 have revolutionized AI by achieving impressive performance on natural language tasks. However, they are fundamentally limited by their fixed context window - the maximum number of tokens they can receive as input. This severely restricts their ability to carry out tasks that require long-term reasoning or memory, such as analyzing lengthy documents or having coherent, consistent conversations spanning multiple sessions.
Researchers from UC Berkeley have developed a novel technique called MemGPT (project site is here, repo is here) that gives LLMs the ability to intelligently manage their own limited memory, drawing inspiration from operating systems. MemGPT allows LLMs to selectively page information in and out of their restricted context window, providing the illusion of a much larger capacity. This lets MemGPT tackle tasks involving essentially unbounded contexts using fixed-context LLMs.
Related reading: LLMs can be extended to infinite sequence lengths without fine-tuning
In this blog post, we'll first explain the technical details behind how MemGPT works. We'll then discuss the results the researchers achieved using MemGPT on conversational agents and document analysis. Finally, we'll consider the significance of this work and how it represents an important step towards unlocking the potential of LLMs despite their fundamental constraints. Ready? Let's go!
Subscribe or follow me on Twitter for more content like this!
How MemGPT Works - The Technical Details
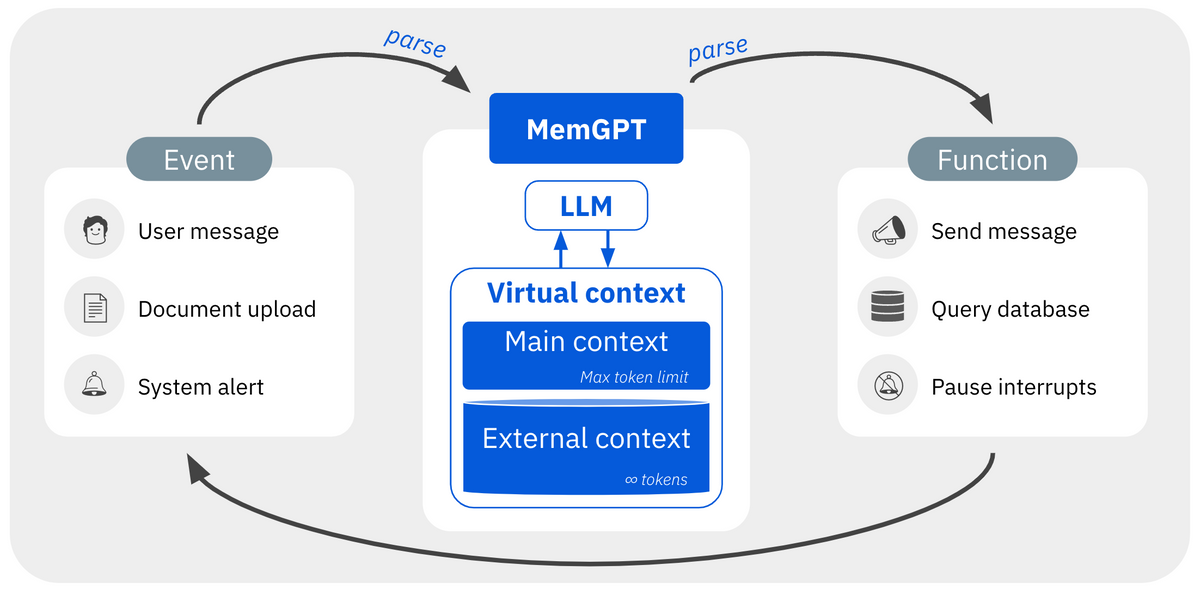
MemGPT is inspired by the hierarchical memory systems used in traditional operating systems (OSes) to provide applications with the appearance of abundant memory resources through virtual memory paging. It implements similar principles to give LLMs the ability to work with contexts far exceeding their limited input capacity.
Hierarchical Memory Architecture
MemGPT delineates LLM memory into two primary components:
- Main Context - This is analogous to an OS's main memory or RAM. It refers to the standard fixed-length context window the LLM takes as input during inference.
- External Context - This serves the role of secondary storage like disk or SSD memory in an OS. It contains out-of-context information that can be selectively copied into main context through explicit function calls.
Memory Management Functions
MemGPT allows the LLM to manage data movement between main and external context through function calls it can generate itself. The LLM learns when to leverage these functions based on its current goals and context.
Control Flow
MemGPT implements an OS-like event loop and interrupt handling:
- Events - User messages, document uploads, etc trigger LLM inference cycles.
- Yielding - If the LLM output doesn't request control, execution pauses until the next event.
- Function Chaining - The LLM can chain multiple functions together before yielding back.
This allows smoothly interleaving LLM processing, memory management, and user interaction.
Results
The researchers evaluated MemGPT on two domains where limited LLM context severely restricts performance: conversational agents and document analysis.
Conversational Agents
MemGPT was tested on the Multi-Session Chat (MSC) dataset consisting of 5 dialog sessions between consistent personas.
It significantly outperformed fixed-context baselines on:
- Consistency - Answering questions requiring inferring information from older sessions
- Engagement - Crafting personalized conversation openers drawing on long-term knowledge
This demonstrates MemGPT can achieve the coherent, long-term conversations needed in agents like virtual companions.
Document Analysis
MemGPT achieved strong results on document analysis tasks like:
- Question Answering - Answering queries based on lengthy Wikipedia documents
- Key-Value Retrieval - Multi-hop lookup over large key-value stores.
It could effectively process through and reason about documents well beyond the size of baseline LLMs' input capacity.
Why This Matters
MemGPT represents an important milestone in overcoming the limited context problem for LLMs. The key insights are:
- Hierarchical memory systems allow virtualizing essentially infinite contexts.
- OS techniques like paging and interrupts enable seamless information flow between memory tiers.
- Self-directed memory management removes need for human involvement.
Rather than blindly scaling model size and compute, MemGPT shows we can unlock LLMs' potential within their fundamental constraints through software and system design.
Limitations and Next Steps
MemGPT currently achieves strong results by relying on proprietary models like GPT-4. Getting similar memory management capabilities working robustly with open-source LLMs is one area for future work.
There are also many exciting directions for extending MemGPT's OS-inspired techniques:
- Exploring different memory tiering architectures and caching policies
- Expanding the function vocabulary for more sophisticated control
- Applying the paradigm to other long-context domains like gameplay and simulation
- Integrating MemGPT with retrieval augmentation methods
- Improving memory management strategies as LLMs grow in sophistication
Overall, MemGPT demonstrates that bringing principles from operating systems to AI unlocks powerful new abilities within existing model limitations. It opens up promising avenues for developing AI systems that are more capable, useful, scalable, and economical.
Thanks for reading!
Subscribe or follow me on Twitter for more content like this!


Comments ()