
"Flow engineering" doubles code generation accuracy (19% vs 44%)
The authors of a new paper present an approach that "intensifies" code generation.
Code generation is an increasingly important capability in artificial intelligence. It involves training machine learning models to automatically generate computer code based on a natural language description of the desired program's functionality. This has many potential applications, from translating software specifications into functional code to automating backend development to assisting human programmers.
However, high-quality code generation remains challenging for AI systems compared to related language tasks like translation or summarization. Code must precisely match the syntax of the target programming language, handle edge cases and unexpected inputs gracefully, and accurately address the numerous small details specified in the problem description. Even small mistakes that would be harmless in other domains can completely break a program's functionality and cause it to fail compiling or running.
Recently, researchers from CodiumAI proposed a new method called AlphaCodium to substantially improve the code generation capabilities of large language models like GPT-4 (paper here, repo here). Their key insight was that merely tweaking the wording of the prompt has inherent limitations for complex coding problems. Instead, they designed a multi-stage process focused on iteratively generating, running, and debugging code against test cases to enable models to learn from experience.
Subscribe or follow me on Twitter for more content like this!
The Limitations of Prompt Engineering
In natural language tasks, prompt engineering refers to carefully tuning the words and structure of the prompt to guide the model toward producing the desired output. For example, adding the phrase "Write a concise summary:" before the input text results in more focused summaries from the model.
Prompt engineering has proven very effective at steering large language model behavior for text generation. However, for coding problems, the researchers found that even extensive prompt tuning yielded minimal gains. The reasons are instructive. High-quality code generation requires:
- Precisely matching the syntax of the target programming language
- Handling edge cases and unexpected inputs gracefully
- Addressing all the small details and requirements described in the problem statement
- Ensuring the code compiles and runs properly for all valid inputs
These structural requirements go well beyond just text generation. Hard-coding them into the prompt is infeasible for complex problems. The prompt alone lacks the concrete feedback needed for models to learn these coding skills and nuances.
The AlphaCodium Iterative Flow
To address these challenges, the researchers designed an iterative flow tailored to the structure of code generation problems. The key innovation is leveraging the execution of the generated code against test cases to provide direct learning signals.
The AlphaCodium flow has two main phases:
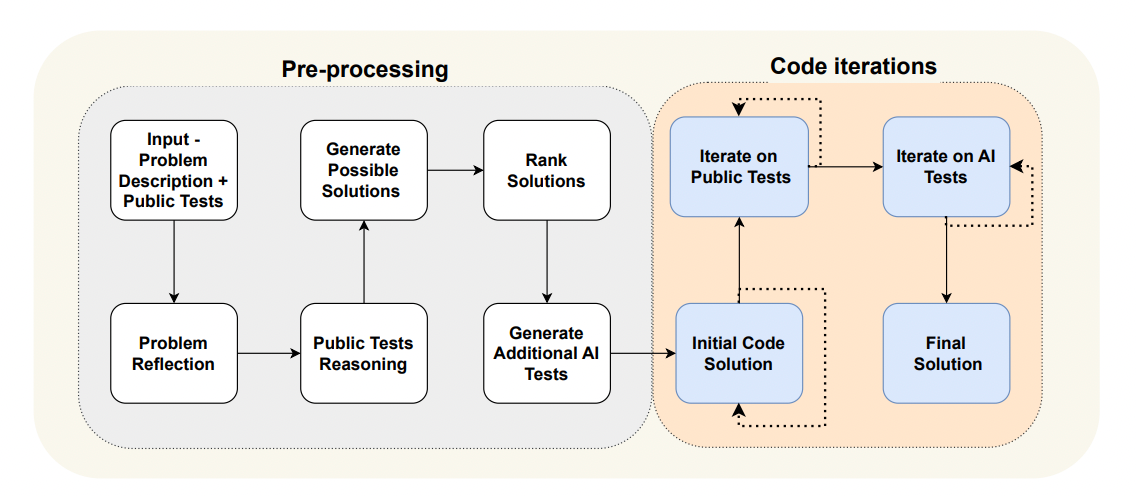
Pre-processing
- The model paraphrases the problem description as bullet points to extract key details
- It explains the expected logic behind each sample input/output
- It provides 2-3 proposed natural language solutions
- It generates additional diverse test cases for coverage
Code Iterations
- The model generates an initial code solution
- It repeatedly runs this code against the public test cases, fixing bugs that arise
- It does the same for the model-generated test cases
- Additional test cases are added to a growing suite of "test anchors" to prevent regressions
By incrementally reasoning about the problem, developing solution hypotheses, expanding test coverage, and repeatedly generating and debugging code, the model learns through experience - exactly the skills needed for high-quality code generation.

The researchers found that structuring the process into modules with clear interfaces and objectives yielded improved results compared to end-to-end models. Each stage focuses on easier sub-tasks first to accumulate knowledge and surface insights that inform downstream stages. Upstream stages like test generation do not need full solutions, just basic reasoning.
Note: you may also be interested in this article on CodePlan by Microsoft, which takes a similar approach. Unfortunately they have still not released the repo for it despite my asking a few times :(
Experimental Results
The researchers evaluated AlphaCodium on the CodeContests benchmark containing hundreds of coding problems sourced from competitive programming competitions.

For the GPT-4 model, AlphaCodium increased code generation accuracy on the validation set from 19% to 44% compared to even a heavily optimized single prompt. The benefits held across model sizes and test sets, with sizable gains over prompt engineering alone.
AlphaCodium also significantly outperformed prior published methods like AlphaCode and CodeChain, while using far fewer computational resources. For example, it matched AlphaCode's accuracy with 10,000x fewer model queries by avoiding unnecessary brute force generation.
These results demonstrate the value of designing AI systems holistically around the task structure, rather than treating them as generic text generators. By incorporating iterative code running and debugging, AlphaCodium better aligns the training process with the end goal of producing robust working code.
I recommend checking out the appendix of the paper for more info about how the results were evaluated - it's extremely well-written and readable.
Broader Implications
While demonstrated on competitive programming problems, the concepts used in AlphaCodium offer broader lessons for advancing code generation by AI:
- Prompt engineering alone has limitations for complex code tasks. Concrete problem-solving experience is crucial.
- Test-based development disciplines can inform model training. Tests provide an unambiguous fitness function.
- Iterative code debugging focuses model improvements on errors that actually occur.
- Test coverage expansion highlights generalizability gaps not visible in the prompt.
- Soft decisions with double validation reduce brittleness and bias.
AlphaCodium provides a promising new paradigm for code generation grounded in software engineering best practices. There are still open research questions around generalizability and computational overhead. But the principles demonstrated here - learning from experience, test-driven development, modular reasoning, and iterative debugging - seem to provide a strong foundation for advancing AI's coding abilities. I'm excited to see where this one goes!
Subscribe or follow me on Twitter for more content like this!


Comments ()