
Meta AI Presents Method for Real-Time Decoding of Images from Brain Activity
Understanding how the human brain represents and processes visual information remains one of the grand challenges of neuroscience. Recent advances in artificial intelligence (AI) and machine learning (ML) have unlocked new possibilities for modeling and decoding neural activity patterns underlying visual perception. In an exciting new study published in Nature, researchers from Meta AI and École Normale Supérieure push the boundaries of real-time visual decoding using magnetoencephalography (MEG).
Subscribe or follow me on Twitter for more content like this!
The Promise and Challenges of Real-Time Decoding
Brain-computer interfaces (BCIs) that can translate perceived or imagined content into text, images or speech hold tremendous potential for helping paralyzed patients communicate and interact with the world. Non-invasive BCIs based on electroencephalography (EEG) have enabled real-time decoding of speech and limited visual concepts. However, reliably decoding complex visual perceptions like natural images requires detecting fine-grained activity patterns across large cortical networks - a major challenge for low-resolution EEG.
 Mike Young
Mike Young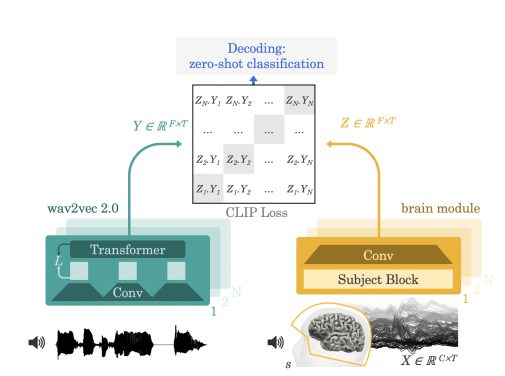
Functional magnetic resonance imaging (fMRI) can decode detailed visual content with high accuracy due to its excellent spatial resolution. But its slow imaging rate (≈0.5 Hz) severely limits real-time applications. MEG offers a middle ground, measuring whole-brain activity at millisecond temporal resolution using magnetic field sensors. Despite previous attempts, robust real-time decoding of natural visual perceptions from MEG remains an open challenge.
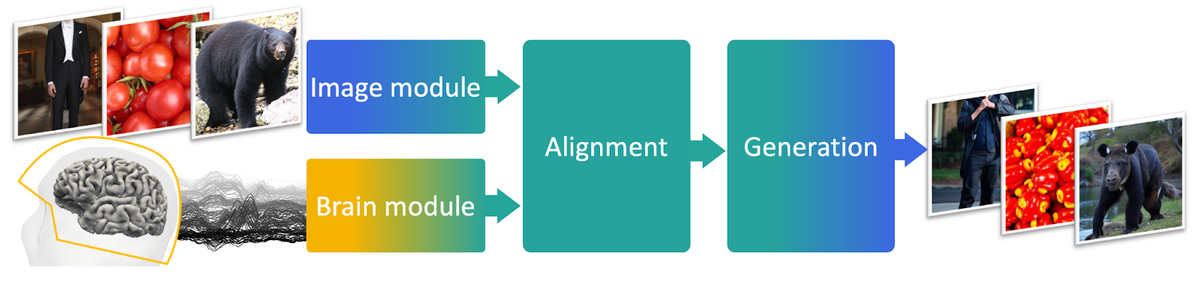
A Three-Module Pipeline for MEG-Based Visual Decoding
In this work, the authors propose a novel three-module pipeline tailored for MEG that aligns neural signals to pretrained visual embeddings and generates images.
The image module extracts visual features from natural images using a variety of convolutional neural network models (CLIP, VGG, DINO, etc.) pre-trained on large image datasets. This provides semantic embedding spaces to link with brain activity patterns.
The brain module is a MEG-specific convolutional network trained to predict these image embeddings from MEG sensor data recorded as participants viewed corresponding images. It is trained using both regression and contrastive objectives.
Finally, the generation module is a pretrained latent diffusion model that generates images conditioned on MEG-predicted embeddings.
Promising Results on MEG-Based Image Retrieval and Generation
The authors systematically evaluated their approach on the THINGS-MEG dataset containing MEG recordings from 4 participants viewing 22,448 natural images.
For image retrieval, their model achieved up to 70% top-5 accuracy in identifying the correct image out of thousands of candidates. This represents a nearly 7-fold improvement over classic linear decoders. Retrieval performance peaked shortly after image onset and offset, leveraging both onset and offset-related neural responses.
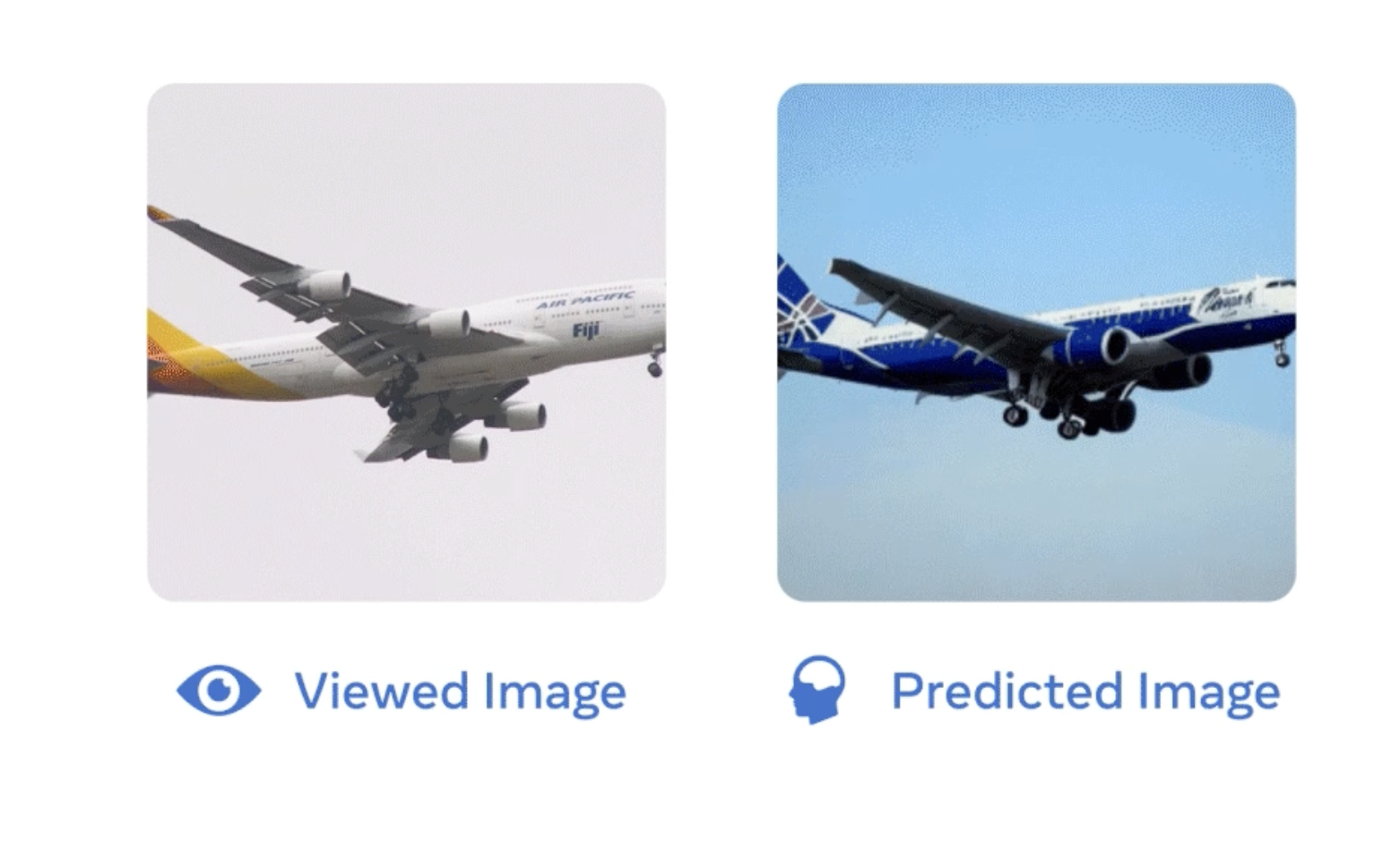
The model was also able to generate imagery matching the semantic category of the original image reasonably well. However, it struggled to reconstruct finer low-level visual details. This aligns with the lower spatial resolution of MEG compared to fMRI.
Interestingly, certain embedding spaces like DINOv2 yielded better decoding performance during later brain responses after stimulus offset. This demonstrates the value of recent self-supervised vision models for decoding higher-level visual features.
Steps Towards Real-Time Visual Decoding
This work provides several important advancements towards real-time decoding of dynamic visual content from non-invasive neural data.
MEG's millisecond resolution offers the potential to track rapid visual processes as they unfold in the brain - critical for real-world applications. The model's ability to leverage both image onset and offset responses is a promising step in this direction.
The use of pretrained convolutional networks greatly enhances MEG decoding over classic computer vision features. Flexible conditioning of generative models enables reconstructing novel natural images beyond fixed training classes.
However, work remains to improve reconstruction of fine visual details from MEG and enable fully real-time decoding. The findings also raise some important ethical considerations around privacy of decoded mental content... (wow, that was a weird sentence to write!).
Overall, this research highlights the growing potential of combining machine learning with non-invasive neuroimaging to unlock real-time visual BCIs.
Critical Assessment of the Study and Results
Unlike a lot of the papers I read, the authors here provide extensive quantitative validation of their approach on a dataset of over 20,000 images, demonstrating sizable improvements in retrieval accuracy over baseline models. Image retrieval metrics are well-suited for objectively evaluating model performance in identifying matching visual input.
The generated images appear reasonably correlated with ground truth images in terms of high-level content. However, both qualitative examples and numerical reconstruction metrics indicate major limitations in reconstructing finer visual details compared to similar fMRI-based approaches.
While they compare retrieval performance for different embedding models, the lack of fully end-to-end training makes it difficult to conclusively determine the most optimal visual encoding space for MEG decoding.
The study could benefit from exploring model performance across semantic categories with diverse visual features. As the authors note, evaluating on held-out categories not seen during training would better indicate real-world generalization.
Finally, the relatively small cohort of four participants limits the ability to reliably assess inter-subject robustness. Testing on larger and more diverse subject pools would strengthen the evidence for robust MEG decoding.
In summary, while promising, I think the results indicate that substantial work remains to achieve true real-time decoding of photorealistic natural imagery from non-invasive neural signals. But this study provides an important leap in that direction using state-of-the-art deep learning and MEG.
Subscribe or follow me on Twitter for more content like this!


Comments ()