
Can AI pass the CFA exam? A new study says probably not yet
The CFA exams rigorously test practical finance knowledge and are known for being quite difficult.
The emergence of large language models (LLMs) like ChatGPT and GPT-4 has sparked excitement about their potential capabilities. Their strong performance on various natural language tasks has led many to wonder - could these models have what it takes to pass complex professional exams like the prestigious Chartered Financial Analyst (CFA) Program?
A new study by researchers at Queen's University, Virginia Tech, and J.P. Morgan put ChatGPT and GPT-4 to the test on mock CFA Level I and Level II exams. The results provide an insightful benchmark of where LLMs stand today in handling advanced financial reasoning. Let's see what they found.
Subscribe or follow me on Twitter for more content like this!
Background on the CFA Program
First, some context on the CFA Program itself. It consists of three levels of exams covering topics like financial analysis, portfolio management, accounting, and economics. The exams are known for rigorously testing practical financial knowledge and reasoning skills.
CFA charterholders often pursue careers in investment analysis, portfolio management, and other finance roles. Obtaining the charter involves passing all three exam levels, which typically takes 2-5 years. Each level has pass rates around 40-50%.
The exams utilize multiple-choice questions, item sets with longer vignettes, and essay prompts. Level I has 180 independent questions. Level II has 88 questions grouped into 22 item sets. Level III mixes essays and item set questions.
The Study Methodology
For the study, the researchers tested ChatGPT and GPT-4 on mock exams for Levels I and II. They could not use real past CFA exams due to restrictions by the CFA Institute.
The models were evaluated in zero-shot, few-shot, and chain-of-thought prompting scenarios:
- Zero-Shot: No examples provided, tests inherent reasoning skills.
- Few-Shot: Models are given 2-10 example questions as references.
- Chain-of-Thought: Models explain their reasoning step-by-step for each question.
The models were prompted to return structured answers to multiple choice questions. Their accuracy was scored against the established mock exam solutions.
In total, 7 mock exams were utilized - 5 for Level I and 2 for Level II. The topic distribution mirrored actual CFA exam topic weights.
High-Level Results and Key Takeaways
At a high-level, the study yielded several interesting findings:
- GPT-4 consistently outperformed ChatGPT across settings, aligning with it being a more advanced LLM.
- Both models struggled substantially more on Level II compared to Level I questions.
- Few-shot prompting provided significant accuracy gains over zero-shot for ChatGPT.
- Chain-of-thought prompting yielded marginal gains over zero-shot, and exposed knowledge gaps. In-context examples helped more.
- Based on estimated CFA passing scores, only GPT-4 could potentially pass the exams under few-shot prompting.
These results highlight LLMs' current limitations in handling the nuanced domain knowledge and reasoning required for the CFA exams. However, gains from few-shot prompting indicate their ability to acquire new finance-specific knowledge.
With more rigorous training on finance concepts, the models show promise for continued enhancement on financial reasoning tasks. But passing the CFA exams lies further down the road.
Next, we'll dig deeper into the level-by-level performance analysis and results.
Detailed Level I Performance Analysis
On Level I, GPT-4 achieved 73-75% accuracy across zero-shot, few-shot, and chain-of-thought settings. ChatGPT scored 58-63% across settings. A 5-10 percentage point gain from few-shot prompting displays the value of example questions for ChatGPT.
By topic:
- Highest scores for both models on Derivatives and Ethics questions. These required less math/tables.
- Lowest scores on Portfolio Management and Financial Reporting. More applied questions with tables/details.
- GPT-4 outscored ChatGPT significantly on Quantitative Methods, showcasing weaker math skills for ChatGPT.
Chain-of-thought performance:
- Marginal gains over zero-shot for GPT-4, reduced performance for ChatGPT.
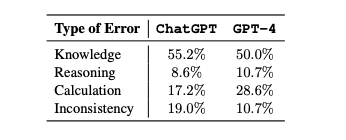
- ChatGPT's main errors were lack of core knowledge and incorrect formulas.
- GPT-4 had fewer knowledge gaps, but made more reasoning errors that led it astray.
Overall, Level I performance highlights knowledge gaps in core finance areas for both models. But GPT-4 demonstrates stronger out-of-the-box capabilities versus ChatGPT.
Level II Performance Analysis
On the more complex Level II questions, GPT-4 scored 57-61% and ChatGPT 46-48% across settings.
Level II saw lower scores overall compared to Level I:
- Longer prompts with case descriptions increased difficulty.
- More specialized questions tested granular concepts.
- More questions required math/table analysis.
For GPT-4, chain-of-thought prompting provided a decent 7% gain over its zero-shot performance. However, few-shot prompting did not help as much as Level I.
ChatGPT saw negligible gains from chain-of-thought prompting. The longer Level II item sets likely require more explicit reasoning guidance via examples.
These Level II results further highlight the challenges posed by intricate finance-specific reasoning, even for powerful models like GPT-4. Targeted training on concepts could help down the line.
Estimating Exam Pass Potential
Based on anonymous crowd-sourced passing score estimates, the researchers proposed passing criteria for each level (these CFA exam administrators actually do not give hard cutoff thresholds for passing):
- Level I: ≥ 70% overall score; ≥ 60% in each topic
- Level II: ≥ 60% overall; ≥ 50% in each topic
Under these thresholds, only GPT-4 with few-shot prompting could potentially pass each exam. But its Level II performance fell right around the estimated passing boundary, so it would be close.
ChatGPT likely needs further training to pass either exam. GPT-4 demonstrates stronger reasoning capabilities but still requires more specialized finance knowledge acquisition.
Neither model appears able to reliably pass the CFA exams today - GPT-4 just barely scraped by. By the way, this consistent difference in performance is indicative of the difference in performance between ChatGPT and "vanilla" GPT-4, which I have written about here.
Limitations and Future Directions
While insightful, we should consider the limitations of the study:
- Use of mock exams rather than real past CFA questions.
- Sole focus on multiple choice questions, not essays.
There are also several promising paths for enhancing LLMs on CFA exams and financial reasoning:
- Retrieval augmentation using finance knowledge bases (although humans would probably do a lot better with this too!)
- Offloading calculations to specialized tools like Wolfram Alpha.
- Combining few-shot examples and chain-of-thought prompting.
- Employing critic models to refine reasoning.
- Continued pretraining on finance corpora.
Conclusion
This rigorous evaluation of ChatGPT and GPT-4 on mock CFA exams showcases their promise alongside current limitations in advanced financial reasoning. While passing the CFA may remain out of reach today for zero-shot prompting, it's possible that with few-shot or chain-of-thought prompting, GPT-4 could narrowly scrape by and barely pass.
Targeted training on finance concepts, formulas, and reasoning techniques could unlock step-wise gains. Studies like this help chart a course toward unlocking LLMs' full potential in finance down the road through principled testing and enhancement. But for now, human financial analysts can know that their CFA accreditations remain just out of reach of language models.
Subscribe or follow me on Twitter for more content like this!


Comments ()