
What's (actually) up with o1
The new o1 UX is bad. The model is weird. I have questions.
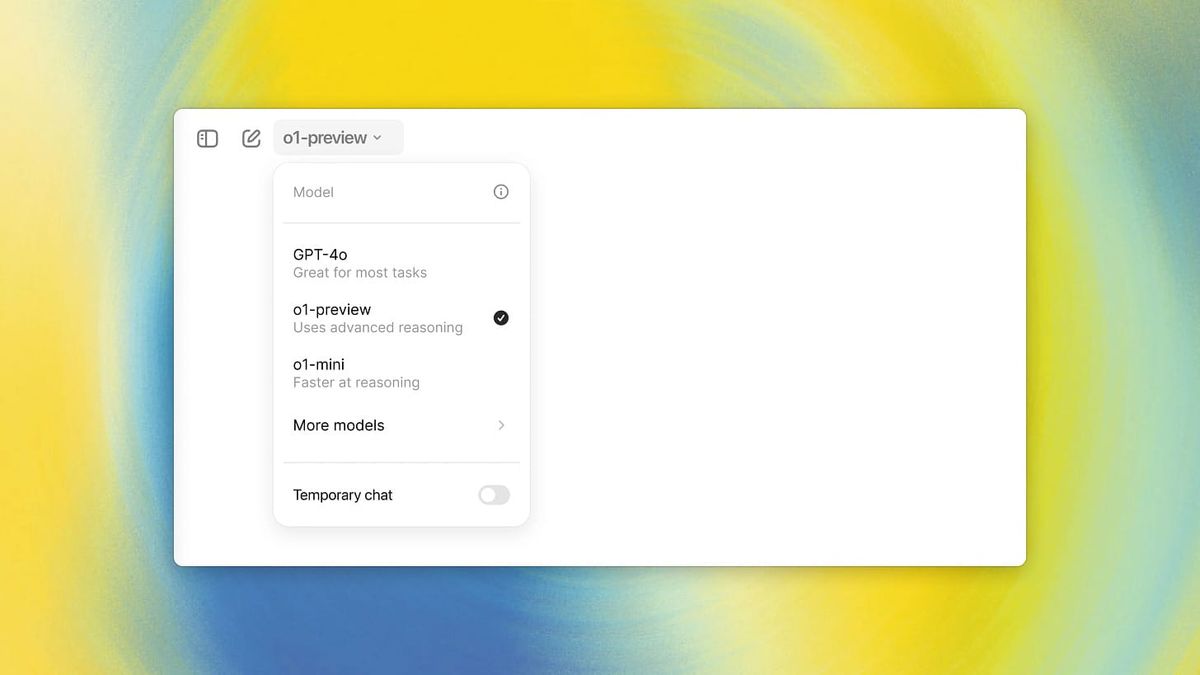
OpenAI’s latest model, o1, has been touted as a huge leap forward. But after around a week of hands-on use and conversations with others in the community, it’s clear that while o1 does some things better, it also stumbles hard—particularly in areas that matter most to me, and, I assume, the rest of you.
On paper, o1 brings some big improvements. It introduces a new reasoning paradigm, generating long chains of thought before delivering a final answer. This approach suggests a model designed for deeper, more thoughtful problem-solving. And with its two versions—o1-preview and the faster, smaller o1-mini—OpenAI aimed to balance performance with accessibility.
But the reality of using o1 is more frustrating than groundbreaking. The model’s coding abilities have improved modestly, but this gain is offset by its sluggish performance. Worse, the overall user experience is mega clunky. Switching models to fine-tune responses or save tokens is a tedious chore, especially in the chat interface. To me, this failure in execution overshadows o1's supposed strengths and raises some questions about OpenAI’s direction.
If you liked this post, check out AImodels.fyi to stay up to date with all the latest AI research.
In fact, I’d call this the second product miss for OpenAI in a row (after voice, which is still not rolled out?), which is great news for competitors like Anthropic, who seem more focused on delivering usable AI with a kickass UX centered around artifacts.
By the way, a lot of info in this post comes from Tibor Blaho - be sure to give him a follow!
First, a quick overview: o1-mini vs. o1-preview
Like I said before, o1 comes in two flavors: o1-preview and o1-mini. The preview version is the early checkpoint of the full model, while o1-mini is the streamlined, faster option expected to be available for free-tier users. In theory, o1-mini should excel in handling STEM and coding tasks. Both versions use the same tokenizer as GPT-4o, ensuring consistency in input token processing.
However, in practice, the improvements in coding abilities with o1-mini are underwhelming. Any gains are largely negated by how slow the model is, especially when generating longer chains of thought. This creates a jarring disconnect between the model's intended strengths and the actual user experience. It literally takes longer to generate the same usable code than 4o, because why o1 can handle more complex problems, it still makes bad mistakes midway through generating results, and then you have to go back around again to get it to correct them. Which leads me to my next point…
Input Token Context and Model Capabilities
One of o1’s touted strengths is its ability to handle larger input contexts. Future updates promise even greater capacities, which would enable the model to manage longer and more open-ended tasks without breaking them into smaller chunks—a limitation present in models like GPT-4o that is quite annoying. This theoretically allows for more seamless and coherent interactions, maintaining context over extended dialogues and complex queries.
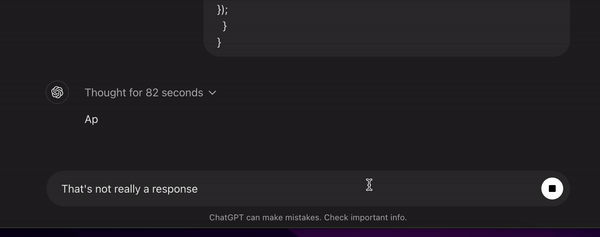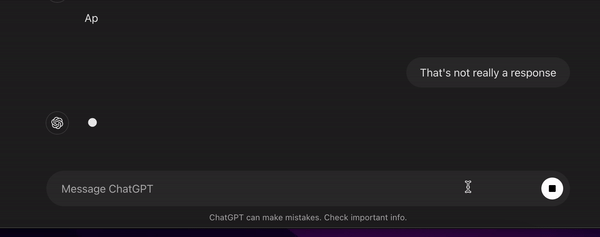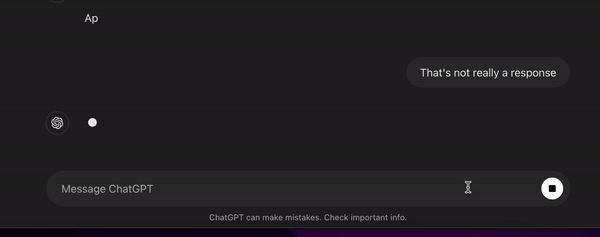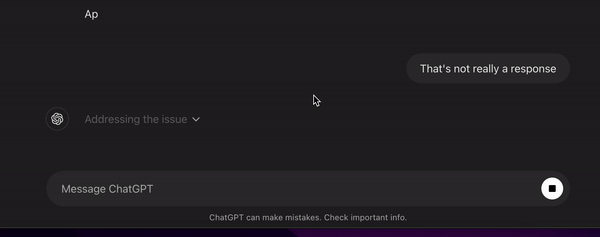
In reality, while the potential is there, the execution falls short. The model often gets bogged down in its own reasoning, leading to delays that frustrate me when expecting quick answers. Moreover, about 40% of the time, o1 gets stuck in thinking mode and never returns a response, making interactions feel unreliable and broken.
Tools, Functionality, and Upcoming Features
Currently, o1-preview lacks integration with external tools such as function calling, code interpreters, or browsing capabilities. These features are slated for future updates and could significantly enhance o1’s versatility. Planned enhancements include:
- Tool Support: Integration of function calling and code interpretation to expand the model’s applicability across various tasks.
- Structured Outputs: Improved formatting and organization of responses to meet specific user requirements.
- System Prompts: Customizable prompts to guide the model’s behavior and output style.
While these additions promise to bolster o1’s functionality, the immediate user experience remains hampered by a chat clunky interface. Switching models to tweak inference or save tokens within the ChatGPT UI is a tedious chore. The interface often reverts back to GPT-4o even when users start a conversation with o1, leading to repeated attempts and heightened frustration. This instability in the UI is catastrophically bad, causing more re-attempts and diminishing the overall usability of the model.
The good side: Chain of Thought (CoT) Reasoning
Ok, it’s not all bad. I actually think the new reasoning mechanism is extremely interesting.
o1’s Chain of Thought (CoT) reasoning mechanism is central to its architecture. During the reasoning process, o1 generates hidden chains of thought that underpin its final responses. These CoT tokens aren’t directly exposed to API users or through interfaces like ChatGPT; instead, they’re summarized to provide concise answers. This summarization, while efficient, doesn’t always faithfully represent the full depth of the underlying reasoning, and also is sometimes weirdly wrong (for example, I gave it some Next.js code and the reasoning summary included comments about Baltimore).
Related reading: Chain of Thoughtlessness
As usual, prompt instructions significantly influence o1’s reasoning process. Carefully crafted prompts can steer the model’s thought patterns, enhancing its problem-solving efficacy. In the AMA, OpenAI said reinforcement learning (RL) techniques have been employed to refine o1’s CoT capabilities, resulting in superior performance compared to GPT-4o.
However, this advanced reasoning comes at a cost. The increased response time during the thinking stage can be a big deterrent, especially when you require quick answers. And as I mentioned, the model sometimes gets stuck in thinking mode and never returns a response—happening about 40% of the time. It acts like it’s done processing, but the answer never comes - it’s often just a blank reply or just a few characters. So you have to burn a bunch more time and tokens to have it try again. Sometimes it never recovers.
API and usage limits
Access to o1 is managed through a tiered API system, with specific usage limits designed to balance demand and resource allocation:
- o1-mini: Allocated a daily rate limit of 50 prompts for ChatGPT Plus users. This restriction is intended to manage load and ensure fair access during the model’s early deployment stages. They reset the preview prompt limit once already though… I’m not sure how long they’ll keep things this restricted but I expect them to open it up soon.
- Future Tiers and Higher Limits: As the model scales, additional access tiers and increased rate limits will be introduced to accommodate a broader user base and more intensive applications (like this here). People have been talking about a $2,000/mo tier which is probably unlikely IMO.
- Prompt Caching: A highly requested feature, prompt caching aims to optimize API performance and reduce redundancy. However, a definitive timeline from OpenAI for its implementation remains unavailable as far as I can tell.
In my opinion, these limitations, particularly the low rate limits in the preview stage, exacerbate the already problematic user experience. Managing prompt and model usage becomes a tedious task, which detracts from the model’s potential benefits.
Pricing, Fine-Tuning, and Scaling
The pricing strategy for o1 models aligns with industry trends, anticipating periodic reductions every one to two years to enhance accessibility. As usage demands grow, batch API pricing will be introduced, catering to enterprises and developers with large-scale applications.
Fine-tuning is a key component of o1’s roadmap (even though I’ve never found it useful in any previous OpenAI model), allowing users to customize the model for specific tasks and domains. While the exact timeline for fine-tuning capabilities is yet to be disclosed, its inclusion will significantly enhance o1’s adaptability and performance in specialized applications.
It does sound like scaling o1 presents some challenges, primarily constrained by the availability of top-tier research and engineering talent. Innovations in scaling paradigms for inference computing hold promise for overcoming these bottlenecks, potentially yielding substantial performance improvements in future model iterations.
Interestingly, inverse scaling, where model performance degrades with increased complexity, remains a minimal concern for o1. Preliminary evaluations indicate that o1-preview performs comparably to GPT-4o in personal writing prompts, suggesting that scaling does not adversely impact its efficacy in nuanced tasks.
Model Development and Research Insights
The development of o1 leverages reinforcement learning to achieve high-level reasoning performance. Beyond numerical computations, o1 exhibits creative thinking, excelling in lateral tasks such as poetry composition. Its ability to engage in philosophical reasoning and generalize across diverse problem spaces, including deciphering ciphers, underscores its advanced cognitive architecture.
Practical applications of o1 are evident in its deployment within tools like a GitHub bot designed to route code reviews to appropriate CODEOWNERS. Internal testing methodologies reveal that o1 can self-assess by quizzing itself on challenging problems, indicating a degree of self-referential problem-solving capability.
Continuous enrichment of o1’s knowledge base seems to be a priority for OpenAI, with plans to incorporate more recent data into o1-mini iterations beyond the current cutoff of October 2023.
How to get the most out of o1: prompt techniques and best practices from OpenAI
Like basically every LLM out there, maximizing o1’s potential requires strategic prompting techniques that align with its advanced reasoning capabilities. Here’s some recommended techniques from the OpenAI AMA, from Tibor’s post.
- Edge Cases and Reasoning Styles: Incorporating edge cases and diverse reasoning styles within prompts can significantly improve o1’s performance, enabling it to navigate complex scenarios with greater accuracy.
- Receptiveness to Reasoning Cues: Unlike earlier models, o1 is more attuned to embedded reasoning cues, allowing for more nuanced and sophisticated responses.
- Contextual Relevance in Retrieval-Augmented Generation (RAG): Providing pertinent context within prompts improves response quality, while irrelevant information can impede the model’s reasoning process.
A lot of these best practices are standard across models. If you’re familiar with LLM prompt engineering, there’s not a ton of new things here (maybe a bit about the sensitivity to reasoning queues).
My take
Honestly, after roughly a week of using o1-preview, my impressions are mixed and lean even towards negative:
- Modest Improvement in Coding Ability: o1-mini shows some enhancement in handling coding tasks, but these gains are largely negated by the model’s sluggish response times and the fact that you sometimes have to re-run a generation because it never completes or completes only partially.
- Terrible UX: The process of switching models to tweak inference or save tokens is painful and disrupts the chat experience. The ChatGPT UI often reverts back to GPT-4o even when users start a conversation with o1, leading to repeated attempts and immense frustration.
In my opinion, o1 marks a product miss for OpenAI. The potential is there, but execution falls short because the overall UX is terrible. Like I mentioned before, I think this shortcoming opens the door wider for competitors like Anthropic, who are currently leading the pack in providing more refined and user-centric AI solutions.
The UX fails to accommodate the paradigm of dynamically adjusting the model’s strength (jumping between 4o, mini, preview, and even out of desperation 4) as needed. This rigidity not only hampers usability but also diminishes the practical advantages that o1 aims to offer. OpenAI is rolling out so many models with so many different naming paradigms, use cases, and tradeoffs that it’s becoming hard to figure out what to use when. This makes me wonder more about their overall product direction.
Despite its flaws, I will say o1 isn’t totally without merits. The model can tackle profound philosophical and math questions and handles intricate tasks with a degree of sophistication that is impressive. Its creative reasoning processes, especially its self-assessment mechanisms, demonstrate some pretty cool advanced problem-solving abilities and cognitive flexibility.
In the end, the true measure of o1’s success will hinge not on its technical prowess, but on OpenAI’s ability to refine the UX and make the model accessible and practical for everyday use. We’ll see what they can come up with.
If you're interested in staying updated with the latest in AI research and getting more nuanced analyses, be sure to check out AIModels.fyi and join the conversation on Twitter and Discord.


Comments ()