
They found a new NeRF technique to turn videos into controllable 3D models

Creating realistic, animated 3D models from video footage has been a longstanding challenge in the field of computer graphics due to the complexity of human movement and the subtleties of appearance under varying conditions. Traditionally, this process has relied on costly and labor-intensive techniques such as multi-camera setups and detailed manual modeling, making it inaccessible for casual or low-budget applications.
To attack this problem, a team from the Fraunhofer Heinrich Hertz Institute has introduced a new technique for animating 3D human models by using Neural Radiance Fields (NeRFs). Their method may bypass the need for expensive equipment and extensive manual labor by reconstructing these models directly from standard RGB video footage.
This technique represents a step towards simplifying the creation of animated 3D models, potentially making it more accessible and less resource-intensive. In the following sections, we'll delve into the specifics of this method, analyze the effectiveness of the generated animations, and discuss what this advancement might mean for practitioners and hobbyists alike. Stay with me as we unpack the layers of this new approach!
Subscribe or follow me on Twitter for more content like this!
The quest for high-fidelity digital humans
Creating lifelike digital versions of people is useful for movies, video games, and virtual meetings. But making these digital people look real is tough. They have to look right from every angle, in every light, and in every pose, or they just seem fake.
Right now, making these digital doubles takes a lot of work. It involves scanning a real person with special cameras and equipment, which is too expensive for most people to use.
There is another way to do it by using regular video. However, videos are flat, and we lose the depth needed to make things look three-dimensional. We need smart tools that can figure out how deep or far away things are in a video to make a flat image look like a real, 3D person.
Lately, we've gotten better at this with new technology that can guess the shape of a person from a single camera angle. But there's still a lot to improve. Often, these digital people don't look quite right—they might be a bit distorted or not move naturally. The real goal is to make them not only look real but also move in new ways that weren't in the original video.
NeRFs for Novel View Synthesis
Neural radiance fields, known as NeRFs, are a recent technology for creating realistic 3D images from various viewpoints. They work by using algorithms to predict how light interacts with a scene, making new images that look real, even from angles we haven't seen.
NeRFs have been successful in making still images look like real-life scenes. However, using them to create images of people moving and changing poses is a tougher problem. This is because people and their movements are complex, and the NeRF needs to understand this complexity to create a clear picture.
The traditional approach to training NeRFs for moving subjects can result in blurry images. To solve this, researchers have come up with a new method. They use a computer-generated model of a human body, which helps guide the NeRF. This allows the NeRF to create clear and precise images of people in different poses, by understanding the shape and form of the human body as it moves. This method is a significant step in making NeRFs work well for dynamic, real-world content like human movement.
Technical Approach: Surface-Aligned NeRF
The research presents a technique termed Surface-Aligned Neural Radiance Fields (UVH-NeRF), which outlines a process for generating detailed 3D human images from video footage. Here's a breakdown of the method:
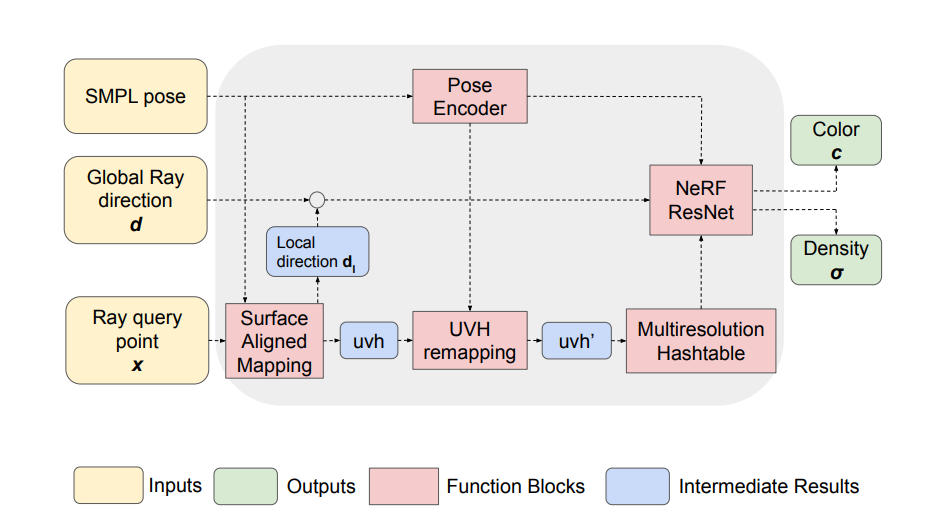
- Adjusting a 3D Human Model to Video: The first step involves aligning a 3D human body model to the subject in the video. This establishes a base for the subsequent steps by providing a 3D structure that mirrors the person's shape and movements throughout the video sequence.
- Adapting NeRF to Human Geometry: The method modifies the traditional NeRF space by:
- Projecting Points onto the Model's Surface: It locates points on the 3D model's surface corresponding to positions in the video. The points are used to map textures from 2D images onto the model.
- Calculating Distances from the Model's Surface: For each point in space, the technique computes its distance to the model’s surface, which helps in determining the point's position relative to the model (inside, on, or outside).
- Incorporating Joint Movements: It uses skeletal joint data to animate the model, which helps in rendering the person in varied poses.
- Refining Spatial Understanding with Neural Networks: A neural network is taught to fine-tune this spatial transformation, ensuring that the NeRF's representation of space is accurate and aligns with the human model.
Further details include:
- Maintaining a Consistent Structure: The technique uses the SMPL model to maintain a uniform structure that accurately reflects the person's pose across different frames.
- Transforming NeRF's Perspective: The approach alters NeRF's perception of space to mimic the human body's form. It remains stable regardless of the person’s movements.
- Creating Pose-accurate Renderings: By integrating skeletal data into the NeRF, the system can generate images that are anatomically correct for any given pose.
- Correcting for Discrepancies: The neural remapping module adjusts for any minor inaccuracies in the model or the transformation, ensuring alignment and coherence.
The culmination of these steps allows the NeRF to learn and animate a human model in a variety of poses and perspectives, thereby creating a versatile and dynamic 3D representation of a person. This advancement holds significant promise for applications in digital media, virtual reality, and other fields requiring high-fidelity human avatars.
Results

When you look at the images where the AI's guesswork is on the left, and the real deal is on the right, it's pretty wild how close they get. The AI-generated figures strike the right poses, and even the clothes seem to fold and wrinkle just like they should. It's like the AI has a good eye for how fabric moves when people do their thing.
But let's be real, it's not perfect. If you squint, you'll see the little things that are off. The AI struggles a bit with the fiddly bits — fingers can get blurry, and facial features might not be spot-on. It's the same kind of stuff that makes a wax figure look eerie, but for a computer spitting out these images from just a few frames, that's still pretty impressive.
This tech is going places. Think VR and AR, where you want to have people looking as real as possible without having to wear those funny suits with ping pong balls.
:no_upscale()/cdn.vox-cdn.com/uploads/chorus_asset/file/23055487/YOTR_alamy_P0XBWG.jpg)
Sure, it's got a bit more baking to do before it's top-notch, but even as it is, it's a pretty solid step towards having digital people milling around in all sorts of virtual spaces.
Conclusion
The key innovation of the research from this paper is the successful application of Neural Radiance Fields to animate 3D human models using only standard RGB video footage. This approach significantly simplifies the traditional, resource-intensive process of creating digital humans, which typically requires elaborate camera setups and manual labor. By demonstrating that NeRFs can be adapted for dynamic content like human movement from relatively accessible video, the paper introduces a practical methodology that could be scaled for wider use across various domains.
This advancement suggests that future developments in the field could lead to more cost-effective and efficient production of digital human models, potentially benefiting industries such as gaming, virtual reality, and film. While the current method has its limitations, particularly with complex movements and longer sequences, it establishes a foundation for further research and improvement.
In essence, this work is a step towards making the digitization of human models more accessible, opening possibilities for its application beyond professional studios to individual creators and smaller production teams.
Subscribe or follow me on Twitter for more content like this!


Comments ()