
Training on code improves LLM performance on non-coding tasks
Adding code to your training data makes your LLM better at non-coding tasks too
Does including code data in pre-training actually improve language models’ performance on non-coding tasks? One of the top trending papers on AImodels.fyi tackles this question head-on, and the results are actually extremely interesting and not that intuitive.
In this post, I’ll explore the paper and talk about how incorporating code data during different phases of language model pre-training affects performance on natural language reasoning, world knowledge, and generative tasks.
Before we begin, though, a word from our friends at Beeyond AI!
Beeyond AI is the new way to do AI—transforming the way you create, design, write, and work with unparalleled ease and efficiency. What truly sets Beeyond AI apart is its integration of industry-leading AI models from OpenAI, Anthropic, and others, bringing over 50 powerful tools into one single platform.
With built-in intuitive text and design editors, you have full creative control to refine your work without the need for additional tools. And forget about crafting complex prompts—just fill in a few simple details, and Beeyond AI will take care of the rest, delivering top-notch results effortlessly.
For just $10 a month, Beeyond AI is your all-in-one solution to get more done, faster and better.
Ok, now let’s take a look at the paper!
Overview
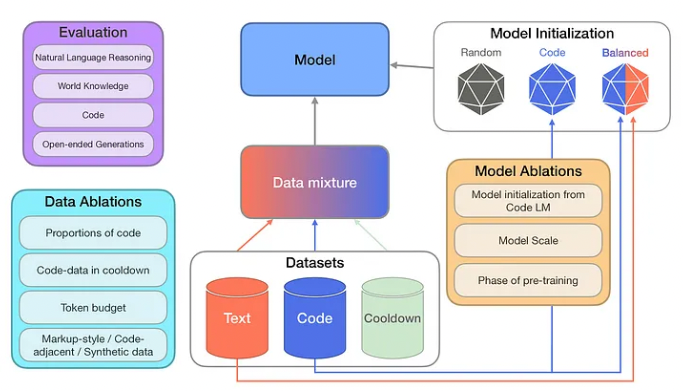
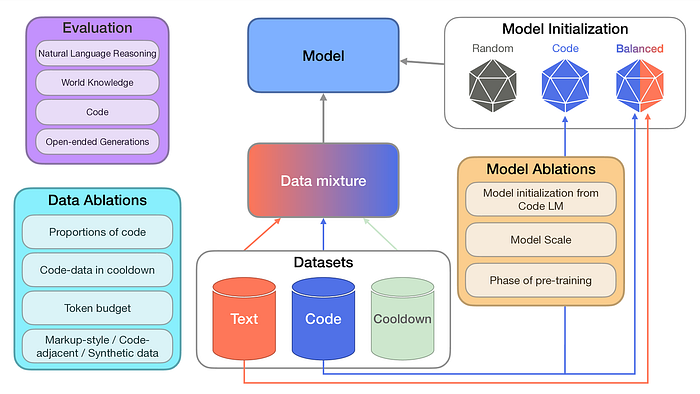
This paper (To code or not to code) presents a systematic investigation into the impact of including code data when pre-training large language models. The researchers conducted extensive ablation studies to examine how code data affects model performance across various non-coding tasks.
I think the study is significant because it provides empirical evidence on a common but understudied practice in language model development. Many state-of-the-art models include code data in pre-training, but its effects haven’t been thoroughly analyzed before.
The researchers evaluated models on benchmarks for natural language reasoning, world knowledge, code generation, and open-ended text generation. They explored factors like the proportion of code data, model initialization strategies, and the impact of high-quality synthetic code.
Their findings have some implications for optimizing pre-training approaches to develop more capable and generalizable language models. I think this shines a spotlight on how code data contributes to models’ reasoning and knowledge capabilities beyond just coding tasks.
Plain English Explanation
So the key idea explored in this research is actually whether exposure to programming code during training can make AI language models better at tasks that don’t involve coding.
By way of analogy, if you’re trying to teach a student general problem-solving skills, you might have them practice math problems, logic puzzles, and writing essays. This study asks: what if we also had them practice computer programming? Would that make them better at the other types of problems too?
The researchers found that, surprisingly, yeah, including code examples during AI training did improve performance on non-coding tasks like answering questions and reasoning about topics. Learning to think in the structured, logical way required for coding helps the AI to approach other types of problems more effectively.
They also found that using high-quality, carefully crafted code examples was especially helpful, even more than just using a lot of lower-quality code found on the internet. This is like how practicing with well-designed math problems might be more beneficial than doing lots of random worksheets. Not that surprising I guess, but helps to have it validated.
Overall, the study suggests that exposure to code helps language models develop better general reasoning and knowledge application skills, not just coding abilities. This insight could help researchers develop more capable AI systems in the future.
Technical Explanation
The researchers conducted a series of ablation studies on decoder-only autoregressive Transformer models ranging from 470M to 2.8B parameters. They systematically varied factors including:
- Model initialization: Comparing random initialization vs. initializing from models pre-trained on different mixtures of code and text data.
- Proportion of code data: Testing pre-training mixtures with 0% to 100% code data.
- Code data quality and properties: Evaluating the impact of high-quality synthetic code, markup languages, and code-adjacent data like GitHub commits.
- Pre-training phases: Examining the effect of code data in initial pre-training, continued pre-training, and final “cooldown” phases.
Key findings include:
- Initializing from a model pre-trained on a balanced mix of code and text, then continuing pre-training primarily on text (the “balanced→text” condition) led to the best overall performance across tasks.
This “balanced→text” approach improved performance relative to text-only pre-training by:
- 8.2% on natural language reasoning
- 4.2% on world knowledge tasks
- 6.6% on generative quality (as measured by win rates against a text-only model)
- 12x on code generation tasks
Including 25% code data in pre-training achieved optimal performance on non-coding tasks. Higher proportions improved coding performance but degraded other capabilities. High-quality synthetic code data, even in small proportions, had an outsized positive impact. Replacing just 10% of web-scraped code with synthetic data improved NL reasoning by 9% and code performance by 44.9%.
Including code data (20% of the mixture) during the final pre-training “cooldown” phase provided additional gains of 3.6% in NL reasoning, 10.1% in world knowledge, and 20% in code performance.
So why does this work? The researchers hypothesize that exposure to code may help models develop more structured reasoning capabilities that transfer to other tasks. However, they note the need for further work to understand the precise mechanisms behind these improvements. Which I think makes sense.
Related reading you might find interesting if you like this study: Poking parts of Sonnet’s brain to make it less annoying
Critical Analysis
There are some limitations to this study, like every study. A few that come to mind:
- Scale limitations: The largest model tested was 2.8B parameters. It’s unclear if the findings generalize to much larger models (100B+) that are becoming common in state-of-the-art systems.
- Task selection: The evaluation focused on specific benchmarks. A broader range of tasks, especially those requiring multi-step reasoning or tool use, could provide a more comprehensive picture of code data’s impact.
- Mechanism understanding: The study demonstrates performance improvements but doesn’t fully explain why code data helps with non-coding tasks. Further analysis of model internals could shed light on the transfer mechanisms.
- Long-term effects: The study doesn’t explore whether the benefits of code data persist after extensive fine-tuning on specific tasks. This could be important for real-world applications.
- Computational cost: The extensive ablations required significant compute resources. This approach may not be feasible for all research groups, potentially limiting reproducibility.
Further research could address these limitations by:
- Scaling up to larger models
- Expanding the task set, especially to more complex reasoning challenges
- Conducting more detailed analyses of model behavior and representations
- Exploring the interaction between code-based pre-training and subsequent fine-tuning
- Investigating potential downsides or risks of including code in pre-training data
Conclusion
Overall, this research demonstrates that including code data in language model pre-training can significantly boost performance across a wide range of tasks, not just those related to coding. My key takeaways are:
- A balanced mix of code and text in initial pre-training, followed by continued pre-training primarily on text, leads to the best overall performance.
- Even small amounts of high-quality synthetic code data can have outsized positive impacts on model capabilities.
- Including code data in the final “cooldown” phase of pre-training provides additional performance gains.
These findings have important implications for the development of more capable and generalizable AI systems. They suggest that carefully curated code data could be a valuable ingredient in creating models with stronger reasoning and knowledge application skills.
I still have some questions. How exactly does exposure to code improve performance on seemingly unrelated tasks? Are there potential downsides to this approach that haven’t been uncovered? How do these findings scale to even larger models?
As our field continues to advance, understanding the impact of training data is just going to become more and more important.
What do you think about all this? Do you buy that exposure to code really make AI systems “smarter” in general? Why do you think it works? I’d love to hear your thoughts in the comments or in the DISCORD!
If you found this analysis interesting, please consider becoming a paid subscriber to support more in-depth explorations of cutting-edge AI research. And don’t forget to share this post with your friends.


Comments ()