
Researchers taught GPT-4V to use an iPhone and buy things on the Amazon app
It's still early, but a GPT-4V agent can navigate smartphone GUIs using a combination of image processing and text-based reasoning.

In the dynamic world of smartphone technology, there's an increasing demand for AI that can navigate and interact with the complex interfaces of mobile apps. This goes beyond simple automation to require an AI that understands GUIs and performs tasks akin to a human. A new paper presents MM-Navigator, a GPT-4V agent built to meet this challenge. Its creators aim to connect AI abilities with the sophisticated workings of smartphone applications.
This post will focus on MM-Navigator's technical capabilities, particularly its use of GPT-4V. We'll explore how it interprets screens, decides on actions, and accurately interacts with mobile apps. We'll address the development challenges and the creative solutions needed for an AI to effectively navigate the diverse and changing world of smartphone interfaces. Looking closely at GPT-4V's key features, the innovative methods for screen understanding and action decision-making, and the strategies for accurate, context-sensitive app interactions, we'll highlight how MM-Navigator significantly narrows the gap between AI potential and the complexities of smartphone app functionality.
The Promise of AI Assistants
For many years, scientists have pursued the goal of AI assistants that can interact with computing devices like a human and follow natural language instructions. With the widespread adoption of smartphones, virtual assistants like Apple's Siri have become more common, but their capabilities are still limited. An intelligent assistant who could carry out complex multistep tasks like booking a vacation or helping an impaired user would be incredibly valuable. It requires major advances in how AI models understand and act within complicated app interfaces.
Technical Context
Recent progress in AI has been driven by LLMs like GPT-4. However, to control a real-world device like a smartphone, the AI system needs to go beyond just processing text. It must also be able to interpret complex visual interfaces displayed on the screen, and then perform precise physical actions like tapping specific buttons or scrolling through menus.
Earlier attempts at this task converted the smartphone screenshots into text descriptions and then fed that text into a language model. However, this approach loses a lot of important layout and visual relationship information that is crucial for identifying the correct interface elements to interact with.
But now, GPT-4V has emerged! It's capable of ingesting and reasoning about both images and text together. This development has opened the door to AI systems that can directly process real smartphone interface screenshots, understand the components, and determine intelligent actions, without having to simplify the inputs down to text only.
However, significant challenges remain in applying large multimodal models (LMMs... not to be confused with LLMs) to device control tasks. The model needs the ability to intelligently generate a logical sequence of actions, conditioned on both the visual inputs from the screen and the provided text instructions. Then it must be able to precisely execute each action by tapping or clicking at specific screen regions corresponding to buttons or menus. The complexity of reasoning about intricate interfaces and producing finely localized actions makes this an extremely difficult problem. MM-Navigator attempts to solve this.
How MM-Navigator Works
The MM-Navigator system developed in this research is composed of the GPT-4V model paired with novel prompting techniques to enable precise control of screen locations.
At a high level, GPT-4V takes both the text instruction provided by the user and an image of the current smartphone screen as inputs. Then it produces text output describing the next action to take.
To allow tapping precise regions of the screen, the researchers first add numbered markers to each interactive element recognized in the screen image, like buttons and icons. GPT-4V can reference these numeric tags in the action text it generates, indexing specific on-screen locations.
Feeding the complete history of all past images and actions would be computationally prohibitive. So instead, at each step, the prompt provides a natural language summarization of the key past events and context. This self-summarization provides an efficient approximation of the interaction history.
The output text from GPT-4V contains both a high-level natural language description of the action like "tap the send button", along with the numeric tag like "[Action: Tap, Location: (12)]". This dual output allows for both human-readable descriptions and precise coordinates to physically perform the tapping or scrolling action on the actual smartphone interface.
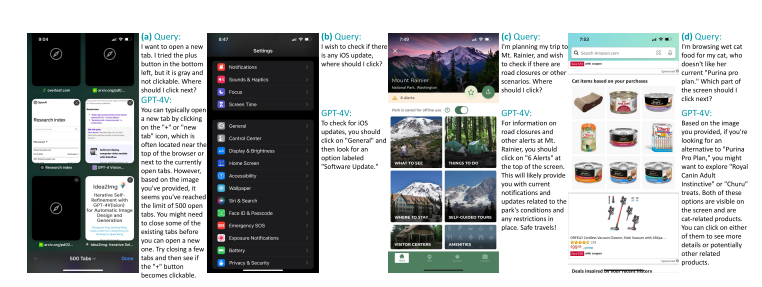
Experimental Results
To evaluate the MM-Navigator system, the researchers tested it on two datasets: one containing iOS screens and instructions that they collected themselves, and a publicly available dataset of Android device screens and actions.
On the iOS screens with single-action instructions, human evaluation found that the natural language descriptions of the intended actions were reasonable 91% of the time. The actual on-screen locations selected by the numeric tags were correct 75% of the time, indicating good but imperfect visual grounding abilities. Additional results are in the table below.
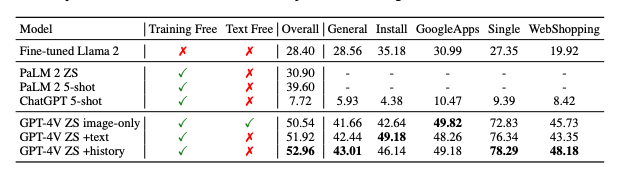
MM-Navigator's proficiency in handling multi-step scenarios is exemplified by its ability to assist in tasks like product purchasing. In the paper, the example that stuck out to me was one where they made the agent purchase a milk frother on Amazon! The system successfully navigates through various apps and interfaces to accomplish this, and even stays within a budget of $50-100. The image below is taken from the paper and shows how it works in detail.
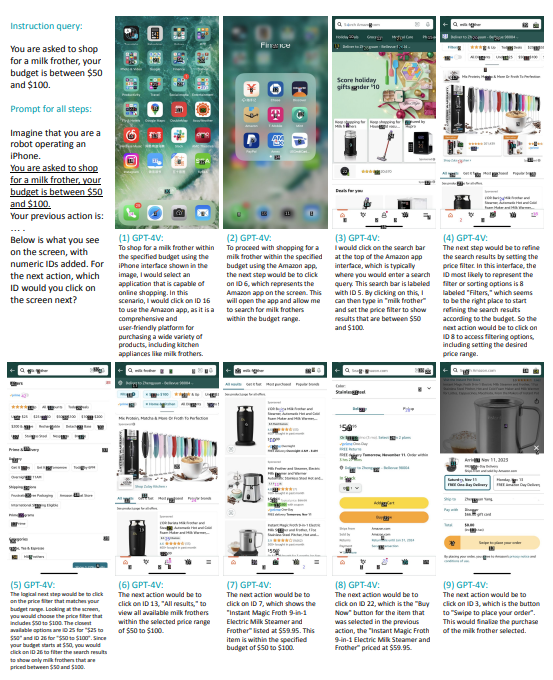
In these kinds of scenarios, MM-Navigator interprets both the user's textual instructions and the visual elements on the smartphone screen. It then determines the sequence of actions needed to complete the purchase. This might involve searching for the product in a shopping app, applying filters for price and product specifications, selecting the appropriate item, and guiding the user through the checkout process.
This showcases MM-Navigator's ability to handle complex, sequential tasks that require understanding and interacting with multiple interfaces. It demonstrates the system's potential not just in executing single, isolated actions, but in managing a series of interconnected steps that mirror the way humans use smartphone apps to accomplish practical tasks.
Limitations
There were, however, lots of error situations. In the "Error Analysis" section of the paper, the authors examine the types of errors made by GPT-4V in predicting user actions within graphical user interfaces (GUIs). They identify two primary categories of errors: false negatives and true negatives.
False negatives
These errors often stem from issues with the dataset or the annotation process. In some cases, GPT-4V's predictions are correct but are marked as incorrect due to inaccuracies in Set-of-Mark annotation parsing or because the dataset annotations are imperfect. This situation frequently arises when target regions in GUIs are over-segmented or when there are multiple valid actions, but the annotations only recognize one as correct.
True Negatives
These errors are attributed to the limitations of GPT-4V's zero-shot testing approach. Without examples to guide its understanding of user action patterns, the model tends to prefer clicking over scrolling, leading to decisions that don't align with typical human actions. For example, GPT-4V might try to find an option among visible tabs instead of scrolling down for more options. It might also click on elements that are not interactive or interpret instructions too literally, resulting in inappropriate actions.
The paper also discusses future considerations, emphasizing the need for more dynamic interaction environments to better simulate real-world scenarios. This includes developing GUI navigation datasets for a variety of devices and exploring methods for automatic evaluation of task success rates. The authors also suggest investigating error correction strategies for novel settings and the possibility of using model distillation to create more efficient GUI navigation models. This analysis underscores the complexities involved in developing AI models for GUI navigation and highlights the importance of both accurate dataset annotation and adaptable model testing.
Conclusion
MM-Navigator, powered by the GPT-4V model, represents an interesting leap forward in AI's ability to navigate and interact with smartphone interfaces. It combines the advanced capabilities of large multimodal models with innovative techniques to interpret and act within mobile apps.
While it demonstrates high accuracy in understanding user instructions and executing tasks, challenges remain, particularly in handling diverse and dynamic interface elements and in ensuring accurate decision-making that aligns with human behaviors.
The system's development and testing highlight the complexity of creating AI models capable of such sophisticated interactions and underline the importance of accurate dataset annotation and adaptable testing methodologies. I could see this technology having all kinds of uses if it's developed further - automating QA testing, helping people with disabilities, or even just completing tasks for us on our phones when we're busy with other work. Looks interesting!
Subscribe or follow me on Twitter for more content like this!


Comments ()