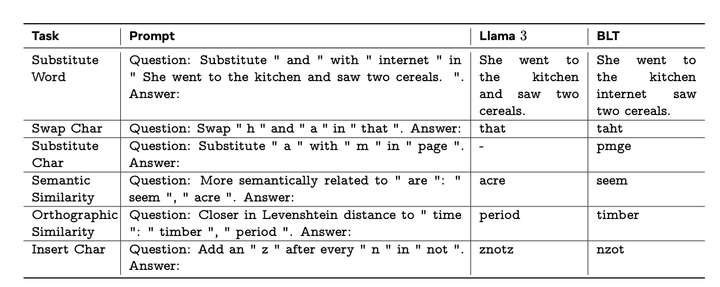
Can image models understand what we’re asking for? High-quality graphics vs high-quality understanding — which one matters more?