
Table-GPT: Table-tuned GPT for Diverse Table Tasks
Training AI to be better at working with tabular data.
Tables are ubiquitous across documents, webpages, spreadsheets, databases, and more. They present information in a structured, relational way that is often easier for humans to parse and analyze compared to free-form text. However, despite major advances in natural language processing, today's AI systems still struggle to fully understand tables and effectively reason over tabular data. This limits their ability to extract insights, answer questions, fill in missing values, and perform other critical table-related tasks.
A new pre-training technique called "table-tuning" aims to enhance large language models like GPT-3 to better comprehend tabular data. In a paper from Microsoft Research, Li et al. propose table-tuning as a way to improve AI's skills in working with tables. Their results indicate table-tuning can significantly boost performance on a diverse range of table tasks.
Let's dig into the paper and see how table-tuning works. We'll also take a look at results presented in the paper and assess how they stand up.
Subscribe or follow me on Twitter for more content like this!
The Prevalence and Importance of Tabular Data
Tables are ubiquitous in documents spanning nearly every profession and domain. Financial reports contain tables summarizing expenses, revenue, ROI, and other key metrics. Science and engineering papers use tables to present experimental results and analyses. Government and NGO data frequently come in large tabular datasets. Even simple web pages often contain smaller data tables mixed in with text and other media.
The structured, relational nature of tables makes them ideal for both presenting and analyzing data. Related values are organized clearly into rows and columns, with labels indicating the meaning of each one. This makes trends and outliers visually identifiable. Relationships like monthly sales figures over 5 regions become apparent at a glance. Tables lend themselves naturally to aggregation, filtering, sorting, and other operations useful for deriving insights.
So mastery over tabular data is crucial for automating many knowledge-worker tasks. An AI assistant that could parse financial reports, fill in missing sales numbers, flag unlikely figures, summarize key takeaways, and generate graphs would be invaluable. A scientific research aide that could extract experimental results from papers into tables, cross-reference them, identify similarities and contradictions, and answer related questions could greatly accelerate discovery. Even for fairly mundane business documents, an AI agent able to accurately populate templates from provided data tables could save massive amounts of human time.
The Limitations of Current AI Table Comprehension
Despite impressive advances in domains like natural language, vision, robotics, and games, current AI systems still struggle to fully comprehend and reason over tabular data. This is likely because most models to date have been architected and trained predominantly on free-form, unstructured text corpora. As the researchers rightly point out, the linear nature of language is quite different from the 2-dimensional vertical and horizontal relationships present in tables.
To test this hypothesis, the authors probed standard language models with two simple table analysis tests: identifying the column and row of a missing value, and locating the column that contains a specific value. Even powerful models like GPT-3 failed on 26-74% of these basic tasks. The authors also observed that changing the column order of a table would alter GPT-3's output, even though column position should not affect interpretation. They posit that since word order drastically alters meaning in text corpora, language models learn unwarranted sensitivity to column position.
Overall, the analysis confirms that despite GPT-3's 175 billion parameters and training on massive text corpora, its table comprehension abilities remain mediocre. These shortcomings motivate exploring new pre-training strategies focused specifically on tabular data.
Overview of the Table-Tuning Technique
The core premise of the table-tuning technique is to continue pre-training standard language models like GPT-3 on synthesized table-task data. This provides extended exposure to diverse tables in the context of completing related tasks. The overall process consists of two major phases:
- Task Synthesis: Programmatically generate training data comprising table-task triples of the form (instruction, table, completion). For example, an instruction could be "Summarize this table", the table would contain sample data, and the completion would be a suitable summarizing caption. The researchers synthesized 14 different table task types via this process, using a corpus of 3 million real-world web and database tables.
- Data Augmentation: Further diversify the training data using proven techniques like paraphrasing instructions, permuting table rows/columns, and chaining model responses. This mitigates overfitting and enhances generalization.
Feeding the resulting wide-ranging table-task dataset into continued pre-training yields enhanced models termed Table-GPT. Experiments confirm Table-GPT versions significantly outperform the base GPT-3 and ChatGPT models across diverse table tasks involving comprehension, reasoning, insights, and more.
Details of the Task Synthesis Process
The first phase of generating training data is the synthesis of instruction-table-completion triples for a variety of table tasks. The authors emphasize the need for diversity in task types and actual tables used. Relying solely on existing benchmarks proved insufficient, as most focus on a limited set of complex tasks like entity matching.
Instead, the researchers devised 14 table task types, ranging from simpler skills like missing value identification to advanced capabilities like summarization. For 9 of the tasks, they generated new table cases on-the-fly by programmatically manipulating tables from their 3 million table corpus. For example, to produce a missing value practice case, they would randomly remove a cell from a sample table. For the 5 tasks reliant on human-labeled data, like entity matching, they utilized existing benchmarks.
This synthesis approach allowed mass-production of training cases across diverse tasks using varied real-world tables. The researchers generated 1,000 cases each for 12 of the 14 task types, resulting in 12,000 triple examples.
Data Augmentation Techniques to Improve Generalization
The second phase of table-tuning involved augmenting the generated task triples to further improve diversity and generalization. Four augmentation techniques were employed:
- Instruction Paraphrasing: Use a language model to rephrase the instructions for a task to create variations. For instance, "Summarize this table" could become "Provide a descriptive title for the table below".
- Table Row/Column Permutation: Shuffle, sample, or permute the table's rows and columns. Since table interpretation should not depend strongly on row/column order, this improves robustness.
- Prompt Variation: Create different prompt templates and formats for the same task.
- Completion Augmentation: For complex tasks like entity matching, insert intermediate reasoning steps into the completion. This provides more detailed demonstrations.
Together these augmentations significantly enhanced the diversity of the training data. The final dataset contained over 15,000 unique instruction-table-completion cases spanning a wide range of tasks and real-world tables. This data was used to continue pre-training the base GPT-3 model, yielding the Table-GPT model.
Experimental Results Demonstrate Clear Benefits
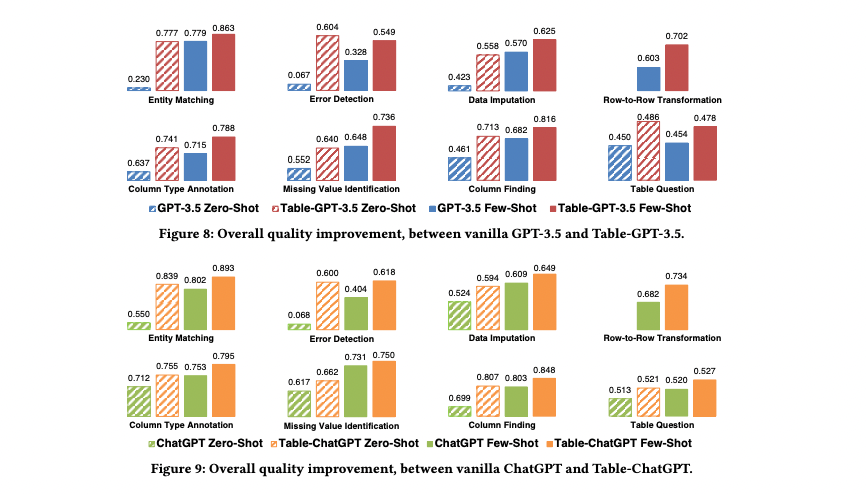
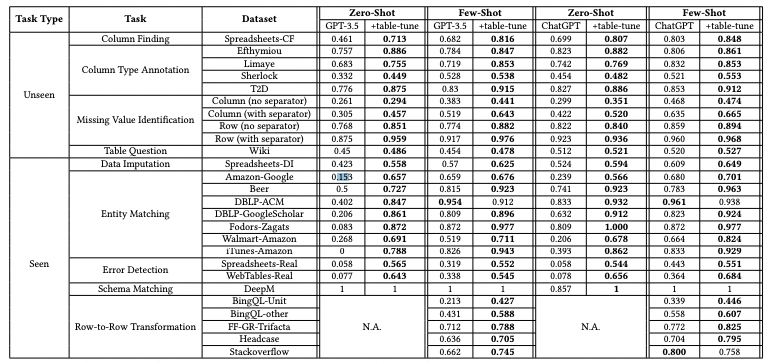
The researchers conducted extensive experiments to validate that table-tuning improves performance on diverse table tasks. They evaluated both zero-shot and few-shot capabilities on held-out test data across 4 completely unseen tasks and 5 seen but distinct test sets. The Table-GPT model showed significant gains over base GPT-3 and ChatGPT models:
- Unseen tasks: On missing value identification, column type identification, question answering, and other new tasks, Table-GPT improved accuracy by, in some cases, more than 25% over base models.
- Seen tasks: For row transformation, entity matching, error detection, and other seen but distinct test sets, Table-GPT again showed gains, outperforming base models in 98% of cases.
- Downstream tuning: When allowed to perform task-specific prompt engineering or fine-tuning, Table-GPT retained its advantage. It achieved higher performance with less downstream tuning.
The consistency of Table-GPT's superior performance confirms table-tuning successfully instills stronger table understanding and reasoning abilities. The fact these gains held even for completely new datasets and tasks indicates improved generalization as well.
However, it is worth noting that the test datasets, while distinct, still centered around a limited set of table processing tasks. Expanding to a wider diversity of datasets and real-world use cases is still needed to further validate generalizability. Nonetheless, these initial results seem promising. Full results below.
Broader Impacts and Next Directions
The table-tuning technique provides a foundation for developing AI systems with more expert-level comprehension of tables. As the authors note, Table-GPT could potentially serve as a "table foundation model" - a base model enhanced specifically for table tasks that are then fine-tuned on downstream applications.
Some promising next steps include expanding the diversity and size of tables used for training, incorporating an even wider range of table skills, and testing performance on additional real-world table analysis use cases. There are likely many other fertile directions for follow-on work as well.
Overall, table-tuning seems a significant step toward advanced AI able to adeptly handle the ubiquitous tabular data so important across domains. With improved comprehension and reasoning abilities, AI systems could better extract insights, answer questions, fill in missing data, identify errors, and conduct automated analysis over tables. This would enable higher-level reasoning and save countless human hours for tasks involving financial data, experimental results, inventory databases, and the many other areas full of valuable tabular information.
Subscribe or follow me on Twitter for more content like this!


Comments ()