
Simplifying transformer blocks
Revisiting Transformer Architectures for Potential Efficiency Gains
Transformers have rapidly become integral to many state-of-the-art natural language processing (NLP) systems today. However, they are also notoriously complex neural network architectures that pose scaling challenges. A team of researchers from ETH Zurich recently published a paper methodically investigating opportunities to simplify transformer blocks without reducing performance or training efficiency. Their findings represent an initial step towards cheaper and faster transformers for NLP applications.
In this post, we'll take a look at how the researchers proposed to simplify the transformer architecture and some of the limitations of their approach. Let's go.
The Surging Popularity and Increasing Scrutiny Over Transformer Efficiency
Interest in transformer architectures exploded following pioneering work by Vaswani et al. in 2017 demonstrating their effectiveness on neural machine translation tasks. Since then, transformers have become ubiquitous across NLP, achieving state-of-the-art results on tasks like language modeling, question answering, and text classification.
Their popularity stems from the self-attention mechanism’s ability to directly model complex global dependencies throughout textual data. Attention provides more flexibility to learn relevant long-range relationships compared to recurrence in LSTMs or local reception fields in CNNs.
However, the appetite for data and computing resources to train transformers grows exponentially with model size. State-of-the-art models today like GPT-3 now contain billions of parameters. Training such massive models costs millions of dollars, requiring thousands of GPUs and extremely efficient parallel code to distribute computation.
These computational resource requirements pose challenges to democratizing access to NLP advances for small companies and researchers. As a result, improving efficiency to enable cheaper and lower environmental impact transformer training is an active area of research.
Beyond model scaling, recent work has also demonstrated the potential for simpler optimizers like LAMB and adaptive gradients to reduce training epochs. And closer scrutiny of computational efficiency metrics highlights needs beyond model parameter count alone when assessing model trainability. This context motivates renewed interest in reevaluating architectural choices and whether many intricately connected transformer components individually contribute to - or potentially constrain - efficiency.
The Multi-Headed Self-Attention Mechanism Behind Transformers
Fundamentally, the transformer architecture contains stacked modules, each centered around two key components:
- A multi-headed self-attention mechanism
- A feedforward neural network
The multi-headed self-attention layer is where self-attention arises in transformers. It provides a mechanism for different input tokens to implicitly relate to one another based on an internally learned representation of their relevance throughout a text sequence.
Conceptually, this allows transformers to build a global implicit graph between all tokens in a sequence to reason about their interactions. This gives transformers a more flexible global receptive field over long texts compared to more local perspectives of long short-term memory (LSTM) recurrent networks or small convolution windows in CNNs gain.
Mechanically, self-attention maps a sequence of input token embedding vectors to output vectors through three stages. First, the input embeddings are each independently projected into separate queries, keys, and values through linear transformations. Intuitively, queries capture what each token is interested in, keys represent what's important about each token, and values transform the tokens themselves.
Then, queries and keys interact to derive attention weights between each query-key pair through dot products. These attention weights measure the learned relevance between all queries and keys, and act as mixing coefficients for the next stage.
Finally, the attention weights mix or attend to the value vectors to produce the output token representations. This multi-step process allows arbitrarily relating tokens hundreds of steps apart, which gives rise to the global receptive field. And it happens in parallel multiple times through independent heads to build multiple representation subspaces focused on different relationship facets.
The Standard Transformer Block Architecture
Operationally, transformers interleave query, key, and value transformations with feedforward networks into a stack of repeated blocks:
- Input passes through a normalization layer
- Residual multi-headed self-attention is applied, producing an intermediate representation
- This representation goes through another normalization then feedforward network
- The feedforward output is residually added to the original input
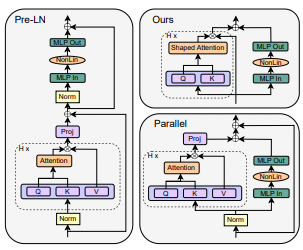
This architecture combines attention and feedforward sub-blocks in a very specific ordered manner. The ordering and layering of these internal components is crucial - adjusting the layout can significantly reduce model stability during training, and balancing them is vital for transformers to learn effectively.
Unfortunately, this sensitivity and intricacy also make reliably modifying or simplifying transformer blocks challenging. While architectural advances like skip connections, residual networks, and normalization layers are well-known to individually aid optimization and generalization, directly characterizing their necessity within transformers has received less focus.
A Methodical Exploration Removing Non-Essential Components
This work aims to methodically analyze whether such less fundamental components like residual connections, attention projections, and normalization layers can be removed from transformers without hindering model quality or training efficiency.
The modifications also critically aim to maintain training efficiency both regarding computational cost and samples required to learn - a priority trade-off that efficiency-centric studies often overlook. For example, techniques like knowledge distillation or quantization can provide operational inference speedups but require extra training steps.
Through iterative experiments on smaller causal language models, guided by principles from signal propagation theory, the authors identify and validate eliminating several components with no observable negatives:
- Residual connections, which aid optimization in deep networks, can be removed by restricting self-attention updates to have a dominant diagonal component at initialization
- Surprisingly, fixing value and projection matrices as the identity rather than extra learned transformations retains performance while reducing parameters and computations
- Switching sub-block ordering from sequential to parallel attention and feedforward enables dropping remaining residual connections
- However, entirely eliminating normalization layers degrades fine-tuning performance, showcasing intricacies in transformer training dynamics beyond what current theory predicts
Significance - A Promising Step Towards Cheaper Transformer Training
The final simplified architecture demonstrates equivalent training efficiency as the standard transformer on English language modeling tasks using default Adam optimization and hyperparameters. This provides an initial proof-of-concept that comparable model quality and optimization efficiency may be possible with notably fewer parameters and matrix multiplications.
However, more extensive validation is still needed to verify computational advantages observed also hold at much larger scales and problems typical of cutting-edge transformers. The findings also reinforce open questions around mismatches between common transformers and optimizers overfit to their complex architectural inductive biases.
Nonetheless, this work puts forth evidence that reliable efficiency improvements are achievable through principled transformer architecture simplification - helping work towards the pressing need for cheaper and lower environmental impact models.
There remains substantial room for future work further validating the specific architectural simplifications put forth across wider datasets and model sizes. And exciting open questions emerge around alternatives to normalization that avoid harming fine-tuning performance. Altogether, this research provides a promising, rigorous first step towards democratized access to capable natural language systems by increasing the efficiency of transformer training through architectural insights.


Comments ()