
Researchers discover in-context learning creates task vectors in LLMs
The researchers show that ICL could be broken down into two distinct steps occurring within the neural network.
In-context learning (ICL) has emerged as an intriguing capability of large language models such as GPT-4 and Llama. With just a few examples or demonstrations, these models can learn new tasks or concepts and apply them to new inputs. For instance, given two examples mapping countries to their capitals, the model can infer and output the capital for a new country it has not seen before.
This ability to quickly learn and adapt from limited data makes ICL highly promising. However, how exactly ICL works internally within the large neural network models has remained unclear. Uncovering the mechanisms underlying this phenomenon is key to understanding, controlling, and advancing this powerful AI technique.
Now, new research from scientists at Tel Aviv University and Google DeepMind reveals valuable insights into the workings of in-context learning in LLMs. Their findings provide evidence that ICL operates by creating a "task vector" that captures the essence of the examples provided. This post explains the key points from their paper.
Subscribe now for just $5 to receive a weekly summary of the top AI and machine learning papers, delivered directly to your inbox.
The Core Idea
The researchers found that in-context learning works in a simple way inside the AI model.
It happens in two main steps:
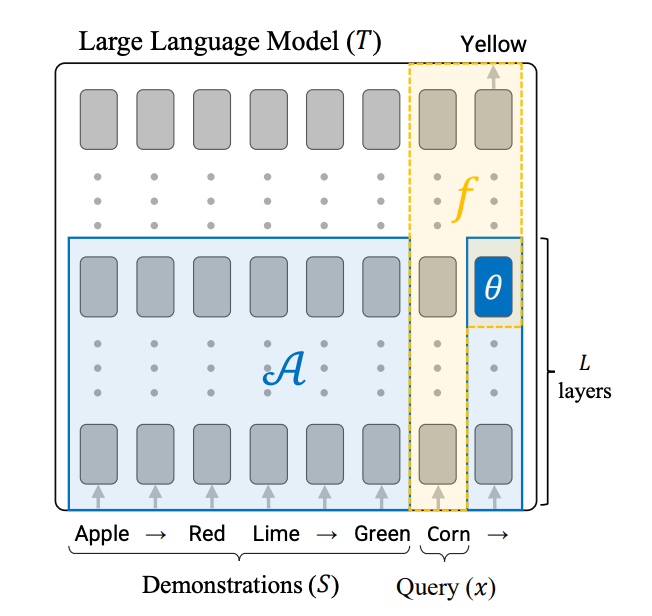
- A "learning" part of the model looks at the examples and creates a task vector. This is a set of numbers that captures the core idea from the examples. Importantly, this vector does not depend on any specific new example the model will be asked about later.
- An "application" part then takes this task vector and a new example. It uses them to generate the output. This part does not directly refer back to the original examples.
Putting it together, the overall process can be basically represented as:
Output = Apply(new example, Learn(examples))
"Learn" makes the task vector from the examples. "Apply" uses the new example and vector to generate the output.
So the key point is that in-context learning compresses the examples into a meaningful task vector. This vector contains the core information about the concept the examples show. The model then uses this vector to guide how it handles new examples, without needing the original examples anymore.
The researchers tested if this theory held up across many different models and task types.
Experiments and Results
The researchers did thorough experiments using 18 diverse tasks. These included things like mapping countries to capital cities and translating French phrases into English.
They tested major public AI models including GPT-J, Pythia, and LLaMA. These ranged from 2.8 to 30+ billion parameters in size.
The results supported the proposed view of how in-context learning works:
- They could isolate the "learning" and "application" parts in the models, while keeping 80-90% accuracy compared to normal in-context learning. This shows the separation captures the essence well.
- The extracted task vectors were consistent for a task, but different across tasks. Visualizations showed clear clustering by task. This means the vectors encode meaningful information about each task.
- Injecting a task vector from one task made the model ignore examples for a different task, and follow the injected vector instead. This strongly shows the vector guides the model's behavior.
- Task vectors produced relevant words for the task, even if those words weren't in the examples. For instance, the vector for French-to-English translation gave high probabilities for words like "translate" and "English". This indicates the vectors represent semantic information about the task.
Together, these findings provide good evidence that in-context learning works by distilling examples into a task vector. This vector captures important information about the task. The model then uses this vector to handle new examples properly.
Why It Matters
These results are an important step towards demystifying how in-context learning works under the hood in large language models. ICL has been opaque, seeming almost magical in its few-shot capability. This research begins unpacking what the models have actually learned to do. This reminds me of a few other papers I've recently summarized, specifically one around explicit registers that eliminate vision transformer attention spikes and one around emergent "truth" vectors in LLMs.
The findings suggest ICL does not purely memorize specific demonstrations, but rather extracts a meaningful semantic representation of the overall task. This opens some new possibilities for efficiently adapting LLMs to new tasks with limited data, without prohibitively large sets of examples.
The results also relate ICL to more standard machine learning techniques like neural embedding learning. This helps connect this technique to established theory and paradigms.
Overall, uncovering this underlying structure inherent to how LLMs perform ICL makes the capability more interpretable, controllable, and robust. It provides a foundation for further research and controlled improvements to what may become a core technique for unlocking AI's potential.
Limitations and Open Questions
However, there are still some questions remaining about ICL in LLMs. This study focused on relatively simple tasks with single token outputs. More complex ICL cases likely involve more intricate representations. And the specific mechanisms used to construct and apply the task vectors remain to be elucidated.
Overall, I think these findings represent a significant advance in opening the black box of in-context learning in LLMs. With continued research building on these results, we might be able to fully engineer the benefits of ICL to further enhance our LLMs. Will be watching this space carefully!
Subscribe now for just $5 to receive a weekly summary of the top AI and machine learning papers, delivered directly to your inbox.


Comments ()