
Researchers tried to build an autonomous scientist with AI. How'd it go?
Researchers decided to see if GPT-4 could generate and test hypotheses without human guidance. What happened?
Since the earliest days of artificial intelligence research in the 1950s, a central goal has been to develop AI systems capable of independently conducting scientific research and advancing knowledge, just as human scientists do. Achieving this remains an elusive grand challenge today, but recent work by researchers at The University of Tokyo provides an incremental step towards realizing this vision. Their findings offer both promising progress and reveal significant limitations that underscore how far we still have to go.
By the way, today's article, exploring 'What if you could fully automate the scientific method with AI?', is yours at no cost! Normally, this is the kind of in-depth analysis reserved for our paid subscribers. They get five weekly articles like this, spanning AI and ML research in diverse areas like health, city planning, images, robotics, videos, and agent systems.
If you're not a paid subscriber, you're usually limited to free previews of these posts. But becoming a paid subscriber opens the door to a world of comprehensive, weekly insights into groundbreaking AI and ML topics. Plus, I'm pretty sure you can expense your membership if this is related to your job!
Basically, if you're not a paid subscriber, this is what you're missing out on. So upgrade today!
Ok, back to our regularly scheduled program. In this case, we'll take a look at what the researchers set out to do, and see where their automated research pipeline succeeded and where it came up short. We'll also look at some of the broader implications of this research on a short and a long time horizon. Let's go.
The Promise and Challenge of Autonomous AI Research
Humans uncover new knowledge through a systematic process we call the scientific method. This involves making observations about the world, formulating hypotheses to explain observations, designing rigorous experiments to test hypotheses, analyzing results to refine theories, and iterating to push the boundaries of understanding. Replicating this process in AI systems requires tremendous advances in conceptual reasoning, creative thinking, and complex planning.
If realized, AI with the capability to autonomously formulate hypotheses and devise experiments to verify them could accelerate scientific progress in ways we can only begin to imagine. Freed from human biases and limitations, such artificial researchers could objectively tackle problems in disciplines ranging from quantum physics to medicine, potentially uncovering revolutionary discoveries. The promise of offloading the scientific method entirely to AI is thus immense.
However, developing systems with the capability for truly autonomous research remains a monumental challenge. While AI has achieved superhuman skill at specific, narrowly defined tasks, flexible reasoning and creativity of the kind scientific discovery requires has proven enormously difficult to instill in machines. Prior attempts at automating elements of research have required extensive human guidance and oversight. Realizing AI that can independently tackle a problem end-to-end, from developing hypotheses to analyzing results, without any human input has been elusive.
Testing Language Models on a Simplified Research Problem
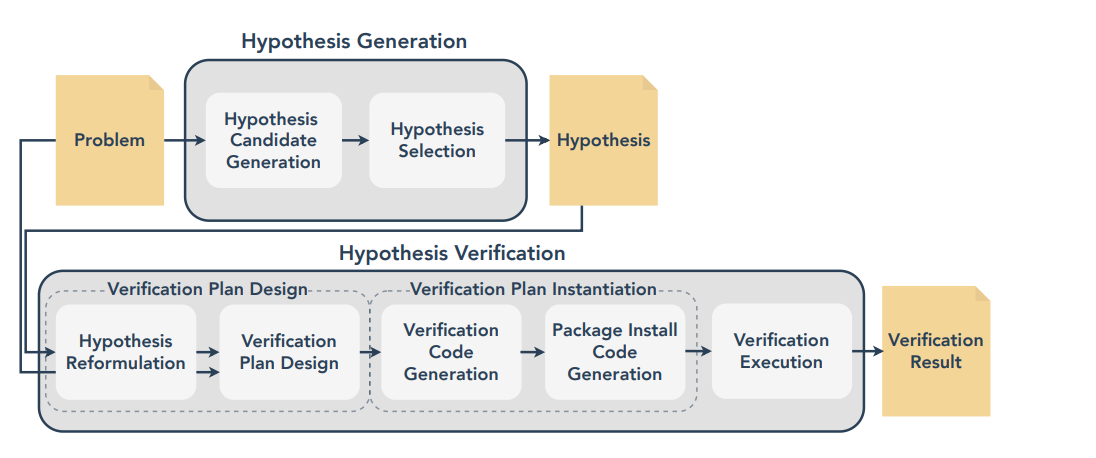
In an effort to incrementally advance towards autonomous artificial researchers, a team from The University of Tokyo conducted an exploratory study investigating whether the powerful large language model GPT-4 could generate novel hypotheses and verify them for a simplified research problem with minimal human guidance.
They presented GPT-4 with a hypothetical research problem related to a tendency of language models to sometimes generate verbose output unrelated to the question when prompted (something most of us who work with ChatGPT are probably familiar with). For example, when asked "What is 1 + 1?", a language model will often respond "The answer is 2" rather than the more succinct "2". The researchers framed this as a problematic inefficiency that should be addressed.

GPT-4 was provided background details on this issue and asked to propose multiple hypotheses aimed at solving the problem. From the generated hypotheses, it selected the one deemed easiest to verify - modifying the prompting strategy to request a one-word answer. The researchers intentionally avoided prescribing instructions on how GPT-4 should generate hypotheses or verify them, providing only general guidelines to assess its capability for autonomous research.
GPT-4's selected hypothesis underwent a process to formalize it and design an experiment for verification. This involved reformulating it into a structured representation and devising a detailed experimental procedure guided by both the hypothesis and problem details. GPT-4 then had to transform this plan into executable code to test the hypothesis by collecting data, analyzing results, and drawing conclusions.
Across 50 trials with different random initializations of GPT-4, the researchers evaluated its success at each stage of hypothesis generation and verification without any human intervention besides providing the initial problem statement.
Promising yet Imperfect Results
Analysis of GPT-4's performance produced several promising yet flawed outcomes:
- Hypothesis generation: In 46 out of 50 trials, GPT-4 produced hypotheses deemed reasonable for the presented problem, suggesting strong capability for autonomous hypothesis formulation. However, the hypotheses lacked originality, limited to minor variations of modifying the prompting strategy.
- Verification planning: The majority of trials yielded verification plans considered suitable - free of major errors and proposing experiments relevant to the hypothesis. Transitioning from hypothesis to high-level experimental design appears achievable. However, sample sizes were small, and statistical rigor lacking compared to human science.
- Implementing verification: Only 13 out of 50 trials (25%) successfully produced valid code to implement the designed experiment and analyze results (and these weren't totally flawless). Autonomously instantiating abstract experimental plans into concrete code remains a major challenge.
- End-to-end success: Those 13 successful trials fully executed the scientific method. This demonstrates the potential for complete autonomy. However, the entire process resembled an oversimplified prototype of "real" science rather than human-level research.
In summary, while GPT-4 achieved some successes, particularly in hypothesis generation and verification planning, the end-to-end results underscore that significant work remains to achieve artificial general intelligence for science. Nonetheless, that a language model with no explicit training in research methods could complete even simplified versions of the full scientific method autonomously is kind of a noteworthy step forward!
Diagnosing Key Limitations
While these results represent progress, the research highlighted the limitations around this approach:
Overly simplified problem - The hypothetical research problem presented to GPT-4 was intentionally designed to be much less complex than real scientific pursuits. It required no mathematical formalism, dataset creation, or model training. Methods tested on toy examples might fail on genuine research problems.
Losing nuance from problem to hypothesis - GPT-4 struggled to retain nuanced semantic details when reformulating the initial problem statement into a concrete, testable hypothesis format. Such deviations in meaning increase the risk of the ensuing research being invalid or irrelevant.
Instantiating abstract plans - Only 25% of trials succeeded in generating code to implement the experimental plans, indicating major gaps in autonomously translating high-level designs into concrete implementations.
Limited autonomy - The researchers themselves devised the problem, evaluated GPT-4's outputs, and handled aspects like API keys. Truly autonomous AI science will require systems that can self-sufficiently formulate and pursue mysteries to unravel.
While impressive relative to prior capabilities, GPT-4's skills remain primitive compared to human researchers. The study thus makes clear that significant advances in reasoning, creativity, and executive function will be essential before artificial intelligence can truly conduct novel science completely independently.
Next Steps Towards Autonomous AI Research
By revealing capabilities as well as limitations of state-of-the-art AI, this research helps chart a path forward. Here's a few future areas we'll need to focus on to make autonomous research real:
- Testing language models on scientific problems requiring real formalization, data, and modeling - not just toy examples
- Enhancing hypothesis generation to produce more varied, creative, and original ideas - not just minor variations
- Improving verification planning with larger sample sizes and rigorous statistical analysis
- Developing techniques to translate high-level plans into code and handle complex programming tasks
- Architecting more integrated systems that can autonomously manage APIs, data, and computation - not rely on human support
- Expanding language models' conceptual understanding and reasoning ability to conduct science akin to human experts
- Shifting focus from evaluating performance on prescribed problems to pursuing open-ended discovery
Through incremental progress across these research directions, scientists might eventually realize artificial intelligence able to push the boundaries of knowledge completely independently. While current systems clearly fall short, this exploratory study provides an initial glimpse of hoped-for capabilities that suggest the possibility, however distant, of artificial researchers conducting science as well as or even better than humans one day.
The Promise and Perils of AI Changing Science
Looking farther ahead, developing AI that can autonomously formulate hypotheses, run experiments, and make discoveries raises profound questions about the ethics and societal impacts of machines rapidly unlocking new knowledge without human oversight:
- How could autonomous AI researchers be prevented from conducting dangerous or unethical experiments?
- If AI begins patenting discoveries, what are the implications for intellectual property and competition?
- Would findings uncovered by AI be trusted or accepted by humans?
- How could we ensure AI science augments human researchers rather than replacing them?
- Who would be accountable if autonomous AI research led to harm?
These complex issues underscore why, despite its incredible potential, we should proceed thoughtfully down the path toward fully autonomous AI research agents.
While realizing AI that can push scientific frontiers by itself remains a distant goal requiring much more work, this research provides a valuable first glimpse into both the possibilities and challenges. The clearer view highlights that advances in reasoning, creativity, and executive function will be critical to achieving artificial general intelligence for science. With diligent and steady progress, this dream that has long captivated the imagination of science fiction writers might eventually transform from fiction into reality.
Don't miss out on the full experience. Become a paid subscriber today and stay ahead in the rapidly evolving world of AI and ML!
Subscribe now for just $9 per month!


Comments ()