

Latest

Meta traded its biggest community asset for a commerce engine
Muse Spark is competitive. The open-source bet that got Meta here is over.
Introduction to Stable Diffusion Img2Img: Shaping the Future of Image Generation
Ever gazed at a Van Gogh painting and wished you could recreate that magic with pixels? Or have you marveled at the surrealist landscapes of a sci-fi movie and yearned to bring such visions to life from scratch? If so, welcome aboard! Today, we are delving into the transformative
Netflix's VOID shows video editing has finally learned the laws of physics
By treating object removal as a causal simulation rather than a pixel-patching job, VOID eliminates "ghost" physics from edited scenes
Turning sound to sight with the Audio-To-Waveform AI Model
Turn spoken audio or music into a waveform using a simple AI model

Simplifying transformer blocks
Revisiting Transformer Architectures for Potential Efficiency Gains

Transforming Spaces with Artificial Intelligence
How sites like Arlington Avenue use AI-Powered Interior Design

From AI Models to AI Products: Turning Intelligence into Impact
A guest post from Praneet Brar

SmolDocling: An Ultra-Compact VLM for Document Understanding

What's the best AI model to handle $1 million in freelance software engineering?
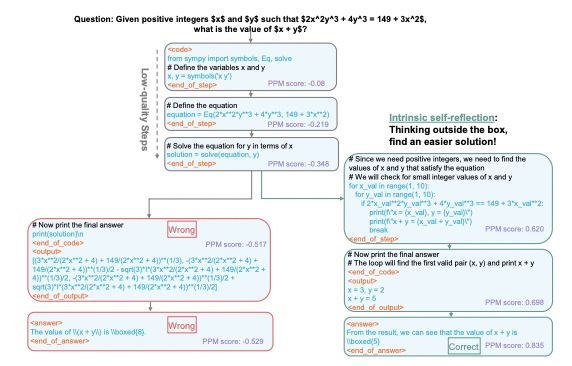
Creating artificial doubt significantly improves AI math accuracy

Step-by-step reasoning can fix madman logic in vision AI
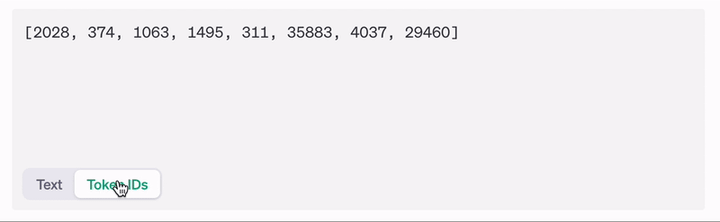
All LLMs use tokenization. Are we doing it totally wrong?
Slashing model size by 85% while redefining how we build adaptable, efficient LLMs

Can image models understand what we’re asking for?
High-quality graphics vs high-quality understanding — which one matters more?