
All LLM improvements are just task contamination?
Current benchmarks are probably overestimating the true capabilities of LLMs
LLMs feel very capable these days, despite their obvious limitations. These models have been celebrated for their ability to engage in what's known as "few-shot" and "zero-shot" learning, where they perform tasks with minimal to no specific training. However, recent investigations suggest that the efficacy of these learning techniques might be overestimated due to a phenomenon known as "task contamination." A new paper has studied task contamination and concluded many LLM "improvements" are just artifacts of task contamination - and that for tasks where there's no possibility of contamination, there's been no improvement in LLMs over time!
That would be a pretty big finding. So let's break it down.
Subscribe or follow me on Twitter for more content like this!
The Promise of Few-Shot Learning
Few-shot learning is one of the most exciting capabilities demonstrated by large language models. It refers to the ability to learn new tasks from just a few examples, sometimes even a single example. For instance, an LLM might be given just 5 labeled text examples for a sentiment analysis task, and be able to classify new text based on those examples alone.
This technique contrasts with traditional machine learning, which requires thousands or millions of training examples to learn concepts. Few-shot learning enables models to acquire new skills and knowledge rapidly from very limited data.
The few-shot prowess of models like GPT-3 has opened up new possibilities for quickly adapting LLMs to new domains and tasks without extensive retraining. Few-shot learning has become a major area of interest and benchmark for measuring progress in LLMs.
What is Task Contamination?
However, the few-shot capabilities reported for many LLMs may be exaggerated due to something called "task contamination."
Task contamination happens when an LLM has already been exposed to labeled training examples for a task during pre-training, even though that task is supposed to be "unseen" by the model during few-shot evaluation. This gives the LLM an unfair advantage, as it is not truly learning the task from scratch.
For example, say researchers want to test how well an LLM can learn a new text classification task from just 10 labeled examples. If that same classification task's training data had already been included in the LLM's pre-training data, then the model isn't really learning the new task from just those 10 examples alone. It is relying on prior knowledge about the task from pre-training.
This makes it impossible to accurately measure few-shot learning capabilities. The model appears to learn rapidly from a few examples, when in reality it had already seen many examples for that task before the few-shot evaluation even began.
How the Study Was Conducted
In the paper, researchers evaluated 12 different LLMs on a variety of natural language processing (NLP) datasets and tasks. The models included proprietary LLMs from the GPT-3 family developed by OpenAI, as well as publicly available models like GPT-J and OPT.
The researchers specifically compared each model's performance on datasets created before versus after that model's pre-training data was collected from the internet. The key idea was that any datasets created after pre-training data collection should be free of contamination, since the model could not have seen them during pre-training.
They evaluated both zero-shot performance, where the model is given no examples, and few-shot performance with 1-16 examples per task. The tasks included text classification, natural language inference, and semantic parsing.
The Findings
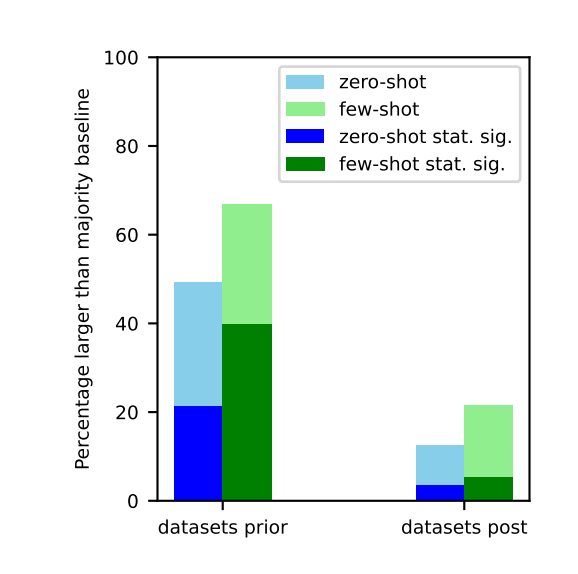
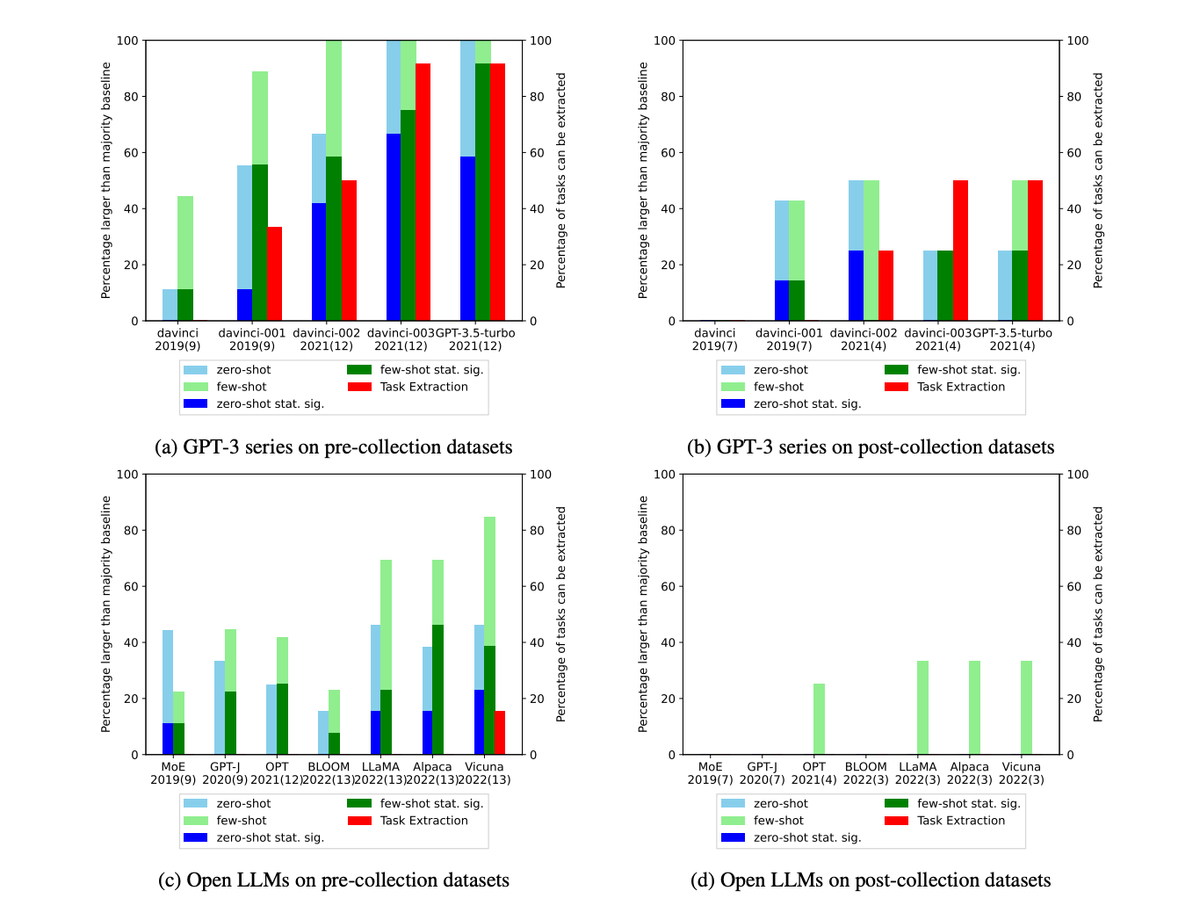
The key findings from the experiments were:
- LLMs were significantly more likely to beat simple majority class baselines on datasets created before their pre-training data was collected. This suggests many of those "pre-collection" tasks were contaminated.
- For classification tasks using post-collection datasets with no possibility of contamination, LLMs rarely exceeded majority class baselines, even on few-shot tests. Their few-shot learning capabilities were much less impressive on truly unseen tasks.
- Later models showed huge jumps in few-shot performance on older tasks, but not on newer uncontaminated tasks. This indicates their few-shot gains likely came from contamination, not fundamental progress in few-shot capabilities.
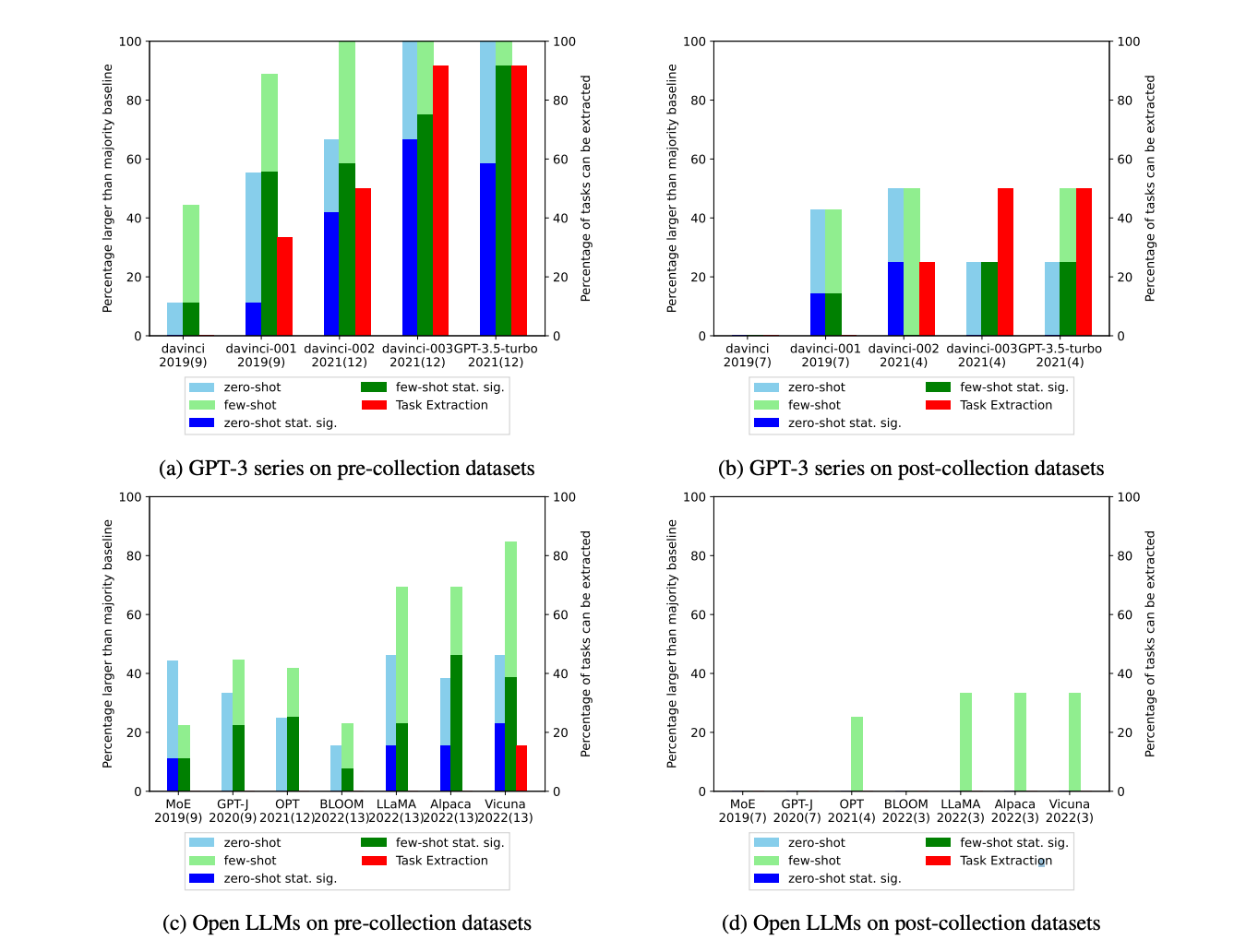
These and other results provide strong evidence that many benchmark few-shot evaluations are overestimating capabilities on truly unseen tasks due to contamination.
Technical Details on Analysis Methods
The researchers utilized four complementary methods to analyze potential contamination:
- Chronological analysis: As described above, they evaluated performance on datasets created before vs after pre-training data collection. The key premise was that performance gains on newer uncontaminated datasets must indicate fundamental LLM progress rather than contamination.
- Training data inspection: For select smaller LLMs, they manually searched pre-training data for examples of the few-shot tasks, providing definitive proof of contamination.
- Task example extraction: They prompted LLMs to generate their own training examples for each task, which models could do if they had seen examples during pre-training.
- Membership inference attack: For text generation tasks, they checked if LLM outputs matched ground truth examples exactly, indicating prior exposure.
Each of these methods provides clues about possible contamination. Together, they make a compelling case that contamination is impacting many few-shot evaluations.
Why This Matters for the Field
These findings suggest that current few-shot benchmarks are overestimating the true capabilities of LLMs on unseen tasks without contamination.
A key promise of few-shot learning is rapid generalization to new concepts from small data. But on uncontaminated tasks, LLMs struggled to significantly beat simple baselines. Their abilities may be less revolutionary than initially thought.
This highlights the need for more rigor in few-shot evaluation. Trustworthy benchmarks should use uncontaminated datasets created after pre-training data collection.
It also emphasizes the challenges of open research with proprietary models like GPT-3. Contamination is extremely difficult to probe without access to full training data. Closed training data enables contamination and reduces reproducibility.
While few-shot learning remains exciting, this study gives reason to be skeptical of some reported performance. Contamination may be artificially inflating estimates of progress. Careful benchmarking on uncontaminated tasks is needed moving forward.
Caveats and Limitations
Contamination is difficult to definitively prove without access to full pre-training data, which is not accessible in closed-source models, as mentioned.
Additionally, while performance gains on contaminated tasks don't represent true few-shot learning, the practice exposure from pre-training may still improve efficiency on related tasks. The benefits from contamination are not zero!
Nevertheless, despite these caveats, these findings strongly suggest that task contamination is a real problem for current few-shot evaluations that must be addressed. Researchers should account for contamination risks in future work to obtain accurate estimates of LLM capabilities on unseen tasks.
Conclusion
This research indicates many current few-shot evaluations likely overestimate the performance of LLMs due to task contamination. Benchmarking on uncontaminated tasks created after pre-training data collection provides a more rigorous test of few-shot abilities. While still promising, few-shot learning for unseen tasks remains an open challenge for future work. Careful evaluation of progress controlling for contamination will be critical moving forward.
Comments ()