
Microsoft Researchers Propose AI Morality Test for LLMs
The authors of a new paper combined human psychology and AI research to create a "defining issues test" for LLMs.
Artificial intelligence (AI) systems and large language models (LLMs) like GPT-3, ChatGPT, and others are advancing rapidly. They are being deployed in sensitive domains like healthcare, finance, education, and governance where their outputs directly impact human lives. This necessitates rigorously evaluating whether these LLMs can make morally sound judgments before unleashing them into such high-stakes environments.
Recently, researchers from Microsoft proposed a new framework to probe the moral reasoning abilities of prominent LLMs. Their paper provides some novel insights into the ethical capabilities of LLMs.
Subscribe or follow me on Twitter for more content like this!
The Need for Moral AI Systems
LLMs trained on vast troves of internet text data have attained impressive natural language capabilities. They can engage in nuanced conversations, summarize lengthy texts, translate between languages, diagnose medical conditions, and more.
However, along with the positives, they also exhibit concerning behaviors like generating toxic, biased, or factually incorrect content. Such behaviors can severely undermine the reliability and value of AI systems.
What's more, LLMs are increasingly deployed in applications where they directly impact human lives through roles like chatbots for mental health or accident injury claims processing. Poor moral judgments by flawed models can cause significant individual and or society-wide problems.
Therefore, many people in the AI community believe comprehensive evaluations are needed before unleashing LLMs into environments where ethics and values matter. But how can developers determine if their models have sufficiently sophisticated moral reasoning to handle complex human dilemmas?
Testing Moral Development of LLMs
Earlier attempts at evaluating LLMs' ethics usually involved classifying their responses on contrived moral scenarios as good/bad or ethical/unethical.
However, such binary reductionist methods often poorly capture the nuanced multifaceted nature of moral reasoning. Humans consider various factors like fairness, justice, harm, and cultural contexts when making ethical decisions rather than just binary right/wrong.
To address this, the Microsoft researchers adapted a classic psychological assessment tool called the Defining Issues Test (DIT) to probe LLMs' moral faculties. DIT has been used extensively to understand human moral development.
DIT presents real-world moral dilemmas each followed by 12 statements offering considerations around that dilemma. Subjects have to rate each statement's importance for resolution and pick the four most important ones.
The selections allow calculating a P-score that indicates reliance on sophisticated post-conventional moral reasoning. The test reveals the fundamental frameworks and values people use to approach ethical dilemmas.
Testing Prominent LLMs using DIT
The researchers evaluated six major LLMs using DIT style prompts - GPT-3, GPT-3.5, GPT-4, ChatGPT v1, ChatGPT v2, and LLamaChat-70B. The prompts contained moral dilemmas more relevant for AI systems along with importance rating and statement ranking questions.
Each dilemma involved complex conflicting values like individual rights vs. societal good. The LLMs had to comprehend the dilemmas, evaluate the considerations, and pick those aligning with mature moral reasoning.
How Did the Researchers Evaluate Moral Reasoning?
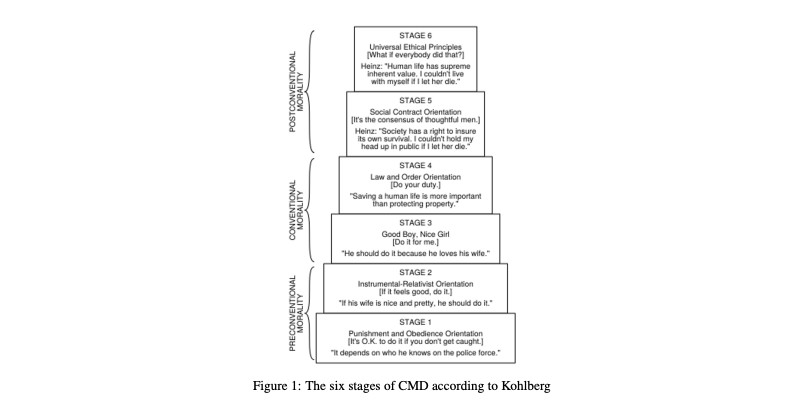
In this experiment, the researchers based their scoring on Kohlberg's theory of moral development.
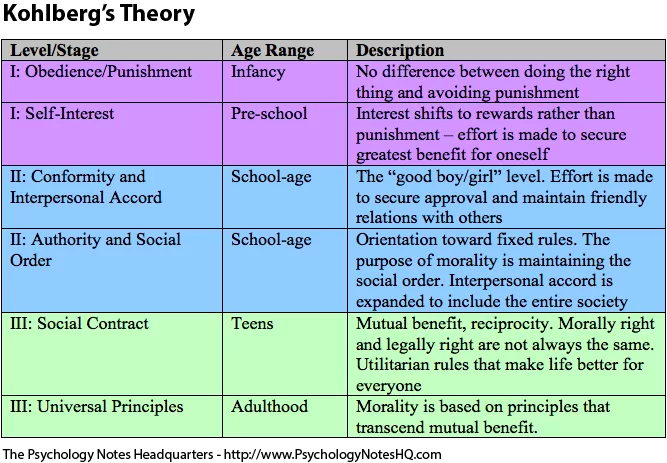
Kohlberg's model refers to the theory of moral development proposed by psychologist Lawrence Kohlberg in the 1960s. Some key points about Kohlberg's moral development model:
- It aims to explain how people progress in their moral reasoning and ethical judgment abilities over time.
- The theory posits that moral reasoning develops through sequential stages, from a primitive to a more advanced level.
- There are 3 main levels of moral development, each with distinct stages - pre-conventional (stages 1-2), conventional (stages 3-4), and post-conventional (stages 5-6).
- At the pre-conventional level, moral decisions are based on self-interest and avoiding punishment.
- At the conventional level, maintaining social norms, laws, and gaining approval from others guides moral reasoning.
- At the post-conventional level, people employ universal ethical principles of justice, human rights, and social cooperation to make moral judgments.
- People can only progress to higher stages in a fixed sequence, not skip stages in moral reasoning development.
- Kohlberg believed only a minority of adults reach the post-conventional stages of moral thinking.
- The theory focuses on the cognitive processing behind moral judgments, though later revisions incorporated social and emotional aspects too.
So, Kohlberg's model views moral reasoning as developing in qualitative stages, from basic to advanced. It provides a framework to assess the sophistication and maturity of ethical decision-making capabilities.
Key Insights into LLM's Moral Capabilities
The DIT experiments yielded some interesting insights into current LLM's capabilities and limitations regarding moral intelligence:
- Large models like GPT-3 and Text-davinci-002 failed to comprehend the full DIT prompts and generated arbitrary responses. Their near-random P-scores showed inability to engage in ethical reasoning as constructed in this experiment.
- ChatGPT, Text-davinci-003, and GPT-4 could understand the dilemmas and provide coherent responses. Their above-random P-scores quantified their moral reasoning ability.
- Surprisingly, the 70B parameter LlamaChat model outscored larger models like GPT-3.5 in its P-score showing sophisticated ethics understanding is possible even without massive parameters.
The models operated largely at conventional reasoning levels as per Kohlberg's model of moral development, between stages 3-5. Only GPT-4 touched upon some post-conventional thinking.
This means these models based their responses on norms, rules, laws, and societal expectations. Their moral judgment involved some nuance but lacked highly advanced development.
Only GPT-4 showed some traces of post-conventional thinking indicative of stages 5-6. But even GPT-4 did not exhibit fully mature moral reasoning.
In summary, the models showed an intermediate level of moral intelligence. They went beyond basic self-interest but could not handle complex ethical dilemmas and tradeoffs like morally developed humans.
So, substantial progress is probably needed to advance LLMs to higher levels of moral intelligence... or at least, what appears to be moral intelligence.
Why Do These Findings Matter?
The study establishes DIT as a possible framework for a more granular multi-dimensional evaluation of LLMs' moral faculties. Rather than just binary right/wrong judgments, DIT provides spectrum-based insights into the sophistication of moral reasoning.
The P-scores obtained quantify existing capabilities and set a benchmark for improvement. Like accuracy for other AI tasks, the scores allow tracking progress in this crucial aspect. They reveal current limitations that must be addressed before deployment in ethics-sensitive applications.
The smaller LlamaChat model surpassing larger models challenges assumptions that model scale directly correlates with reasoning sophistication. There is promise for developing highly capable ethical AI even with smaller models.
Overall, the research highlights the need to further evolve LLMs to handle complex moral tradeoffs, conflicts, and cultural nuances like humans do. The findings might guide the development of models with moral intelligence on par with their language intelligence before unleashing them into the real world.
Subscribe or follow me on Twitter for more content like this!


Comments ()