
Meta unveils Emu Video: Text-to-Video Generation through Image Conditioning
The new approach uses "explicit image conditioning" for higher quality videos

Generating diverse, convincing videos from text prompts alone remains an exceptionally challenging open problem in artificial intelligence research. Directly translating text descriptions into realistic, temporally coherent video sequences requires modeling intricate spatiotemporal dynamics that continue to confound current systems.

In a new paper, researchers from Meta introduce an innovative text-to-video generation approach called Emu Video that they claim sets a new state-of-the-art standard. By factorizing the problem into explicit image generation followed by video generation conditioned on both text and image, the authors claim Emu Video produces substantially higher quality and more controllable results. Let's see what they built and how their approach holds up.
Subscribe or follow me on Twitter for more content like this!
The Text-to-Video Challenge
Applications like automated visual content creation, conversational assistants, and bringing language to life as video require automatic text-to-video generation systems. However, modeling the complex world dynamics and physics required for plausible video synthesis poses a formidable challenge for AI.
Videos demand exponentially more complex scene understanding and reasoning compared to static images. Beyond just recognizing objects depicted in the text prompt, generating coherent video requires inferring how objects interact, move, deform, occlusion relationships, and other changes over time-based on the textual description.
This requires the model to have a strong grasp of real-world semantics, cause and effect, object permanence, and temporal context to produce videos that align with human sensibilities.
Directly predicting a sequence of video frames from only text input is exceptionally difficult due to the high dimensionality and multi-modality of the video space. Without sufficiently strong conditioning signals to constrain the output, existing text-to-video systems struggle to generate consistent, realistic results at high resolution (e.g. 1024x1024 pixels) that faithfully reflect the input textual descriptions.
They often produce blurry outputs that lack fine details, exhibit temporal jittering or instability across frames, fail to fully capture the semantics of the text prompt, and collapse to mean, average outputs that do not match the specificity of the description.
Emu Video: Factorized Text-to-Video Generation
To address these challenges, the key insight behind Emu Video is to factorize the problem into two steps:
- Generate a high-quality image conditioned only on the text prompt
- Generate the full video conditioned on both the synthesized image and original text prompt
This image factorization strengthens the overall conditioning signal, providing vital missing information to guide the video generation process. The generated image acts as a starting point that the model can then imagine moving and evolving over time based on the text description.
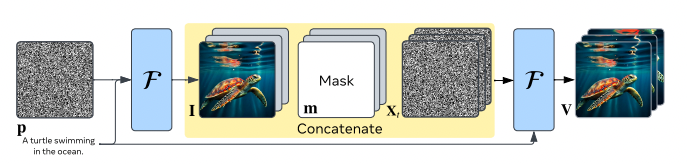
Intuitively, giving the model a plausible still image makes the problem much simpler compared to hallucinating everything from scratch. The model only needs to focus on inferring the motions and transformations to apply to the image to match the text, rather than having to identify the correct visual concepts and their relations.
This factorized generation approach allows training high-resolution text-to-video models efficiently without needing a complex cascade of multiple models. A single model can perform both steps.
Technical Details
Under the hood, Emu Video utilizes diffusion models, a type of deep probabilistic generative model powered by neural networks. The researchers initialize Emu Video using a state-of-the-art text-to-image model pre-trained on large datasets of image-text pairs to retain high visual quality and diversity.
The video generation model is trained using a two-step generation process mimicking the factorization idea:
- Sample training videos, extract frames as conditioning images
- Condition on frames and text to predict future video frames
At inference time, the same process is used but with a synthesized image from the text-to-image model:
- Generate high-quality image from text prompt
- Condition video model on image + text to generate video frames
The model architecture uses a U-Net with an embedded CLIP text encoder and adds 1D temporal convolutions and attention layers after each spatial component to model time dependencies.
Two key innovations in Emu Video's training scheme enable directly generating high-resolution 512px videos without needing a complex multi-model cascade:
Zero Terminal SNR Noise Schedule: This minor change to the noise schedule for diffusion models corrects for train-test discrepancy and substantially improves video stability. By setting the final signal-to-noise ratio to 0 during training, the model learns greater robustness when sampling from pure noise at test time.
Multi-Stage Training: The model is first trained on lower resolution 256px videos which is 3.5x faster computationally. It is then fine-tuned on higher resolution 512px videos using the insights from the first stage. This curriculum-based approach leads to better final results.
Results: New State-of-the-Art Text-to-Video Generation
In rigorous human evaluation studies, Emu Video substantially outperforms prior state-of-the-art methods for text-to-video generation, including recent publications and commercial solutions. The authors reported:
"In human evaluations, our generated videos are strongly preferred in quality compared to all prior work– 81% vs. Google’s Imagen Video, 90% vs. Nvidia’s PYOCO, and 96% vs. Meta’s Make-A-Video. Our model outperforms commercial solutions such as RunwayML’s Gen2 and Pika Labs. Finally, our factorizing approach naturally lends itself to animating images based on a user’s text prompt, where our generations are preferred 96% over prior work."
The improved conditioning enables Emu Video to produce much higher visual quality results with finer details, better motion smoothness, fewer artifacts, and greater temporal consistency across frames. The generated videos better reflect the semantic content of the text prompts in both the spatial layout and temporal dynamics.
The evaluations cover a diverse range of natural and imaginary prompts. Emu Video's factorized approach generalizes well across categories without needing condition-specific tuning.
The gains are especially pronounced on imaginary text prompts that describe fantastical scenes and characters. By explicitly generating an image first, Emu Video produces more creative, stylistically consistent videos that retain the visual diversity of the foundation text-to-image model.
Conclusion
Emu Video's image factorization approach represents an important advance in text-to-video generation, producing substantially higher quality and more controllable results. By generating an intermediate image representation, the model gains a stronger conditioning signal that greatly benefits video generation performance.
These insights make significant contributions towards progress on this challenging conditional sequence generation problem. With rigorous research continuing to push the boundaries, the future looks bright for translating language into realistic and creative videos.
By the way: you may want to check out this article on Emu Edit, a similar project that was also announced by Meta, focused on editing images.
Subscribe or follow me on Twitter for more content like this!


Comments ()