
Meta can now secretly watermark deepfake audio
Researchers have found a way to imperceptibly watermark fake audio
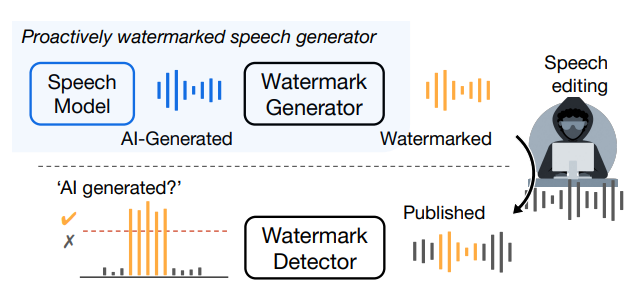
The rapid advancement of AI voice synthesis technologies has enabled the creation of extremely realistic fake human speech. However, this also opens up concerning possibilities of voice cloning, deepfakes, and other forms of audio manipulation (this recent fake Biden robocall being the first example that comes to mind).
Robust new detection methods are needed to find and segregate audio deepfakes from real recordings. In this post, we'll take a look at a novel technique from Facebook Research called AudioSeal (github, paper) that tackles this problem by imperceptibly watermarking AI-generated speech. We'll see how it works and also take a look at some applications and limitations. Let's go!
Subscribe or follow me on Twitter for more content like this!
The Evolving Threat Landscape of Deepfake Audio
We have seen dramatic improvements in the quality of AI voice synthesis, to the point where machine-generated speech is often indistinguishable from real humans. Models like Tortoise TTS, Bark, and AudioLDM and startups like ElevenLabs can clone a person's voice with just a few samples. The samples can be extracted from online videos or recordings without consent.
This has enabled convincing voice spoofing attacks and audio deepfakes. Potential misuses include fraud (e.g. fake calls impersonating someone), spreading false information by synthesizing speeches, or generating non-consensual intimate audio.
Regulators worldwide are scrambling to get ahead of these risks. New legislation like the proposed EU AI Act seek to reduce the risk of AI misuse, and companies are increasingly focusing on ways to get ahead of these issues. From all this, you should be able to see why there's so much interest in robust detection techniques.
Limits of Passive Audio Forensics
The traditional approach to detecting fake audio involved passive analysis - training classifiers to identify statistical differences between real and synthesized speech. These methods exploit model-specific artifacts and lack of richness in current AI voices.
However, passive detection is prone to fail in the future as synthesis systems become more advanced and natural. Any artifacts discernible today could disappear in next-generation models. Passive classifiers trained on current samples are also likely to perform poorly on out-of-domain future audio.
This underscores the need to complement passive forensic analysis with active watermarking techniques that directly embed signals within AI-generated audio.
Introducing AudioSeal
To address the limitations of passive detection, researchers from Meta and INRIA recently developed AudioSeal - the first audio watermarking system specialized for localizing synthesized speech within audio clips.
Instead of training classifiers on model outputs, AudioSeal actively marks generated voices. AudioSeal's design ensures its detection capabilities remain effective against both natural and synthetic speech, adapting to advancements in synthesis technology.
At a high level, AudioSeal has two key components:
- Generator: Imperceptibly embeds a watermark signal into audio produced by a speech synthesis model.
- Detector: Analyzes an audio clip and precisely pinpoints which regions contain the watermark, and by extension identifies the AI-generated portions.
But what makes AudioSeal stand out is its innovations enabling precise localized detection (finding exactly which parts of a clip have been faked) and high robustness:
- Sample-level precision: The detector outputs watermark presence probabilities at each individual time step, rather than just flagging whole files. This enables isolating even small edited regions within audio.
- Robust perceptual loss: A custom loudness-based loss function minimizes the chance of the watermark being audible or noticeable.
- Resilient by design: Severe audio distortions are used during training to maximize out-of-the-box robustness.
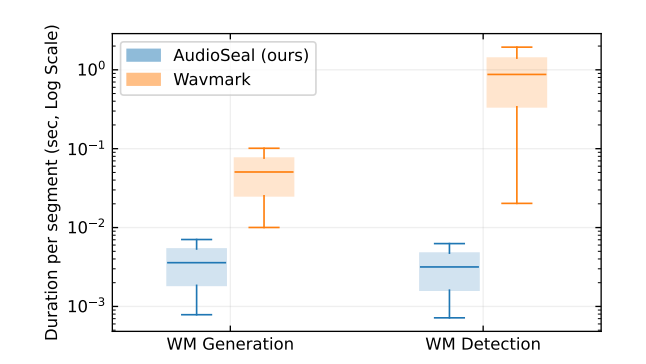
- Efficient detection: Featuring a fast, single-pass detector, AudioSeal significantly outpaces existing models in detection speed, achieving rapid identification with up to two orders of magnitude faster performance.
Next we'll explore the technical details of how AudioSeal operates and achieves these capabilities.
Inside the AudioSeal Watermarking Pipeline
AudioSeal leverages recent advancements in neural audio synthesis and compression to create optimized watermarking models. As I mentioned above, the pipeline comprises two jointly trained networks - the generator which watermarks audio, and the detector which finds watermarked regions.
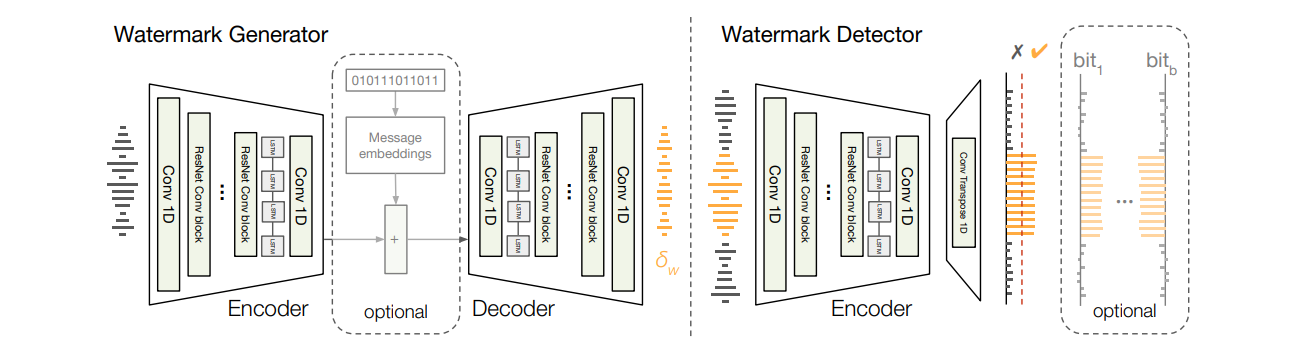
Watermark Synthesis with the Generator
The generator takes as input a pristine audio clip. It passes this through an encoder containing convolutions and an LSTM to produce a latent representation.
This latent code is then fed into the decoder, which uses transposed convolutions to predict a watermark audio waveform of the same length as the original clip.
The watermark is synthesized to follow the envelope of the audio, making it inaudible. Finally, the watermark is added to the original clip to produce the watermarked output.
Precise Localization with the Detector
The detector network analyzing an audio clip mirrors the encoder architecture. It outputs a probability between 0 and 1 at each time step, indicating local watermark presence. This enables precisely pinpointing watermarked regions within the audio down to the sample level.
Joint Training for Robustness
The really key innovation presented in the paper is training the generator and detector jointly rather than separately. The objectives are two-fold:
- Imperceptibility: Minimize perceptual difference between original and watermarked audio via custom losses.
- Localization: Maximize detector accuracy in identifying watermarked regions, especially when mixed with other audio.
Joint training forces the watermark to be robust and located accurately. The detector learns to identify the watermark even if regions are masked or distorted.
Additionally, aggressive audio augmentation during training improves out-of-the-box robustness to compression, noise, filtering, and other modifications.
Benefits over Prior Watermarking Methods
AudioSeal provides significant improvements over previous audio watermarking techniques:
- Generalizability: Trained once then works for any models or languages, rather than needing retraining.
- Localization: Pinpoints manipulations in an audio clip down to the sample-level, unlike prior methods only detecting in 1 second blocks.
- Robustness: Outperformed other watermarking against 15 types of audio distortions. Its architecture is robust against various audio editing techniques, maintaining watermark integrity even with significant alterations.
- Efficiency: Up to 100x faster detection by avoiding brute-force watermark synchronization searches. Enables live and large-scale screening.
- Capacity: Extensible to embedding model identity messages with minimal accuracy impact. Allows attributing clips.
These capabilities make AudioSeal well-suited for practical deployment across platforms to identify AI-generated voices.
Limitations and Safeguards
Despite its promising capabilities, some care is still needed to responsibly apply AudioSeal and audio watermarking generally:
- The technique relies on keeping the detector confidential and robust to different attacks. Otherwise, bad actors could ID and remove watermarks.
- There are ethical risks associated with watermarking, like mass surveillance. The cure could be worse than the disease.
- For wider adoption, standardizing watermarking across different vendors may be needed to avoid arms races.
- Users should be notified if their voice is watermarked, and consent properly obtained. But this could conflict with bullet point number one!
Conclusion
AudioSeal is a novel technique to address the growing challenge of detecting AI-generated audio. By imperceptively watermarking synthetic speech, AudioSeal provides localized detection that stays robust even as synthesis models continue their rapid evolution.
AudioSeal represents an important step, but is unlikely to be a full solution. As the threat landscape changes, better solutions will need to continually co-evolve to identify manipulation risks and foster trust in voice interfaces. Maintaining authenticity and ethical practices around synthetic media remains both a technical challenge and societal one as AI capabilities grow more powerful.
Subscribe or follow me on Twitter for more content like this!


Comments ()