
LongLoRA: A New, More Efficient Way to Fine-Tune LLMs
Meet LongLoRA, an efficient fine-tuning approach that extends the context sizes of pre-trained large language models (LLMs), with limited computation cost.
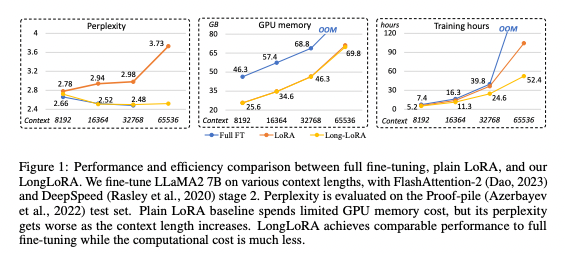
As AI models like ChatGPT get bigger, training them requires more and more computing power. Researchers are looking for ways to train these large AI models without needing Google-scale resources. A new paper explores a new method called LongLoRA that can efficiently train models on much longer texts.
Subscribe or follow me on Twitter for more content like this!
Why this matters
Being able to train on longer texts allows the models to develop deeper understanding and reasoning. This could let them answer questions that require more context, like summarizing a long research paper.
The standard way of training these models on long texts takes a huge amount of computing power. For example, fine-tuning the 70B parameter LLaMA model on 32,000 tokens takes 128 high-end A100 GPUs!
More efficient training means these powerful models can be created and adapted with more reasonable resources. This expands access beyond just the biggest tech companies.
The core ideas
The researchers focus on two main techniques:
- Approximating standard attention: They use an attention pattern that looks locally instead of across the whole text. This "shift short attention" provides a good approximation during training while still allowing the full standard attention for inference.
- Improving low-rank adaptation: Building on a technique called LoRA, they adjust only a small subset of weights rather than all of them. Plus they allow some embedding and normalization layers to also be tuned.
What they accomplished
Using LongLoRA, they could fine-tune a 7B parameter model on texts up to 100,000 tokens long on a single 8-GPU machine. For comparison, previous work took 32 GPUs for only 8,000 tokens.
The efficiency gains were huge - LongLoRA cut the training cost by over 10x for the larger context sizes.
The models performed nearly as well as standard fine-tuning. For example, on a 32,768 token evaluation, the perplexity (a measure of prediction quality) was only 3% higher.
Looking forward
This shows the promise of more efficient training techniques to handle ever-larger models and contexts. There's still more progress needed to match the full quality of standard fine-tuning.
But LongLoRA demonstrates that we can push towards training at a much greater scale, without requiring unreasonable resources. More efficient training will help democratize access to powerful AI systems.
Subscribe or follow me on Twitter for more content like this!


Comments ()