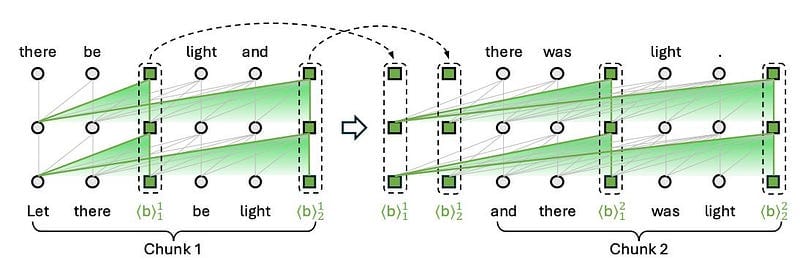
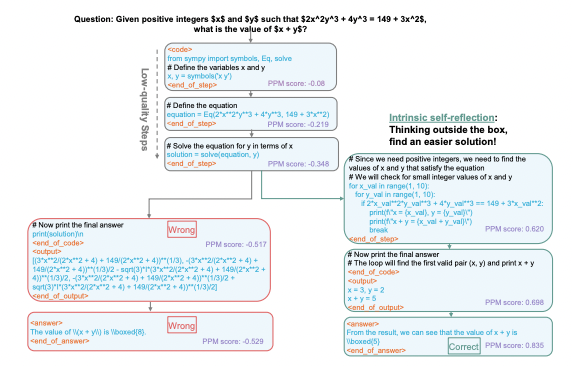
Plain English Papers Long Context Compression with Activation Beacon Getting the most out of each token Partitioning via beacons to get the most out of each token