
LCMs are a new way to generate high-quality images much faster
LCMs achieve similar quality results to LDMs, but in just 1-4 steps instead of hundreds.

Text-to-image AI is on the brink of a significant leap forward, thanks to a new technique called Latent Consistency Models (LCMs). Traditional methods, like Latent Diffusion Models (LDMs), have been impressive in generating detailed and creative imagery from text prompts. However, their Achilles' heel is speed. Generating a single image with LDMs can take hundreds of steps, which is far too slow for many practical applications.
LCMs change the game by drastically cutting down the number of steps needed to generate images. While LDMs laboriously churn out images in hundreds of steps, LCMs achieve similar quality results in just 1-4 steps. This efficiency is achieved by distilling pre-trained LDMs into a more streamlined form, requiring significantly less computational power and time. We'll review a recent paper that presents the LDM model and see how it works.
The paper also introduces an innovation known as LCM-LoRA, a universal Stable-Diffusion acceleration module. This module can be plugged into various Stable-Diffusion fine-tuned models without any additional training. It's a universally applicable tool that can accelerate diverse image generation tasks, making it a potential staple in AI-driven image creation. We'll also examine this section of the paper.
Ready? Let's go!
Subscribe or follow me on Twitter for more content like this!
Training LCMs Efficiently
One of the big challenges in the world of neural networks is the sheer computing power needed, especially when it comes to training them to solve complex equations. The team behind this paper tackled this issue head-on with a smart approach called distillation.
Here's how they did it: They started by training a standard Latent Diffusion Model (LDM) on a dataset that paired text with images. Once this LDM was up and running, they used it as a sort of teacher to generate new training data. This new data was then used to train the Latent Consistency Model (LCM). The cool part here is that the LCM gets to learn from the LDM's abilities without the need to be trained from scratch on a massive dataset.
The real kicker is how efficient this process is. The researchers managed to train high-quality LCMs in just about 32 hours using only a single GPU. This is a big deal because it's way faster and more practical than previous methods. It means that creating these advanced models is now within reach for more people and projects, not just those with access to supercomputing resources.
Results
This research showcases a major advancement in image generation AI with Latent Consistency Models (LCMs). LCMs are adept at creating high-quality 512x512 images in just four steps, a notable improvement over the hundreds of steps required by older models like Latent Diffusion Models (LDMs). The images boast sharp details and realistic textures, a feat particularly evident in the examples shown below.

These models not only handle smaller images with ease but also excel in generating larger 1024x1024 images. They demonstrate an ability to scale to much larger neural network models than previously possible, showcasing their adaptability. The examples in the paper, such as those from the LCM-LoRA-SD-V1.5 and LCM-LoRA-SSD-1B versions, illustrate the model's broad applicability across various datasets and practical scenarios.
Limitations
The current iteration of LCMs has some limitations. The most significant is the two-stage training process: training an LDM first and then using it to train the LCM. In future research, a more direct training approach for LCMs may be explored, potentially skipping the need for an LDM. The paper primarily addresses unconditional image generation, and more work might be required for conditional generation tasks like text-to-image synthesis.
Key takeaways
Latent Consistency Models represent a significant step forward in rapid, high-quality image generation. The ability of these models to produce results competitive with slower LDMs in just 1-4 steps could revolutionize real-world applications of text-to-image models. While there are some current limitations, especially in the training process and scope of generation tasks, LCMs mark a major advancement towards practical neural network-based image generation. The examples provided underscore the potential of these models.
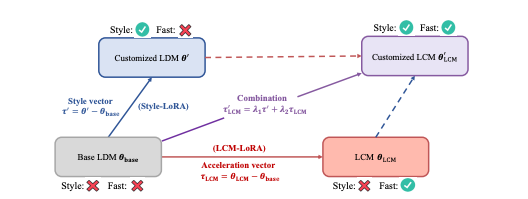
LCM-LoRA as Universal Acceleration Module
As I mentioned in the intro, this paper has two parts. The second part of the paper discusses "LCM-LoRA." This technique allows for fine-tuning pre-trained models with much less memory usage, making it more efficient.
The key innovation here is the integration of LoRA parameters into LCMs, resulting in a hybrid model that combines the strengths of both. This integration is particularly useful for creating images in specific styles or responding to particular tasks. By selecting and combining different sets of LoRA parameters, each fine-tuned for a unique style, the researchers created a versatile model that can generate images with minimal steps and no need for additional training.
In the research, they demonstrate this with examples where they combine LoRA parameters, fine-tuned for specific painting styles, with LCM-LoRA parameters. This combination allows for the creation of 1024x1024 resolution images in distinct styles at various sampling steps (like 2, 4, 8, 16, and 32 steps). They show that these combined parameters can generate high-quality images without further training, emphasizing the efficiency and versatility of the model.
An interesting point here is the use of what they call the “acceleration vector” (τLCM) and the “style vector” (τ′), which are combined using specific mathematical formulas (λ1 and λ2 are adjustable factors in these formulas). This combination results in a model that can swiftly produce images in customized styles.
Figure 3 in the paper (shown below) illustrates the effectiveness of this approach by showing the results of specific style LoRA parameters combined with LCM-LoRA parameters. This demonstrates the model's ability to generate stylistically distinct images quickly and efficiently.
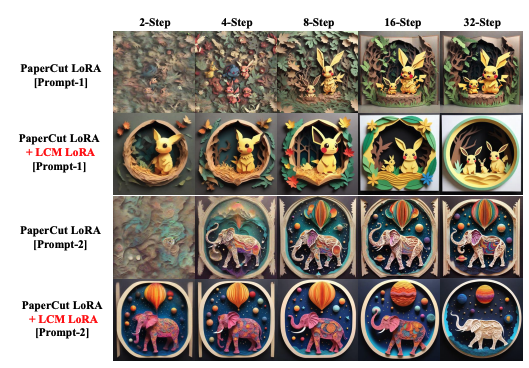
In summary, this section of the paper highlights how the LCM-LoRA model represents a universal, efficient solution for generating high-quality, style-specific images rapidly and with minimal computational resources. The practical applications of this technology are vast, potentially revolutionizing the way images are generated in various fields, from digital art to automated content creation.
Conclusion
We took a look at Latent Consistency Models (LCMs), a new method that dramatically speeds up the process of generating images from text. Unlike traditional Latent Diffusion Models (LDMs) which require hundreds of steps to create a single image, LCMs can produce images of similar quality in just 1-4 steps. This efficiency leap is achieved through a process known as distillation, where a pre-trained LDM is used to train the LCM, thus bypassing the need for extensive computation.
Further, we explored LCM-LoRA, an enhancement that uses Low-Rank Adaptation (LoRA) to fine-tune pre-trained models with reduced memory demands. This integration allows for the creation of images in specific styles with minimal computational steps, without needing additional training.
The key results highlighted include LCMs' ability to create high-quality 512x512 and 1024x1024 images in a fraction of the steps required by LDMs. However, the current limitation is that LCMs rely on a two-step training process, so you still need LDM to start with! Future research may streamline this process.
LCMs, particularly when combined with LoRA as in the propose LCM-LoRA model, are a pretty neat innovation. They offer faster, more efficient creation of high-quality images and I think they hold promise for a wide range of applications in digital content creation.
Thanks for reading!
Subscribe or follow me on Twitter for more content like this!


Comments ()