
Input prompt, output a playable world
Google built a world model that actually works

How do you get computers to understand and interact with worlds the way humans do?
For decades, creating virtual environments has meant painstakingly coding every detail - the physics, the graphics, the rules of interaction. Game developers spend years building these worlds, writing specific logic for how every object should behave. Want a door to open? You need to program that. Want water to flow? You need to write fluid dynamics code. This manual approach has served us well for traditional games, but it becomes a major bottleneck when we think about training artificial intelligence.

Why? Because AI systems, like humans, learn best through extensive practice in varied environments. Imagine trying to learn physics if you could only experiment in one very specific laboratory setup. Or trying to learn to cook if you only ever had access to one kitchen with one set of ingredients. This is essentially the situation we've been in with AI training environments - limited by how many we can manually create.
This is where world models enter the picture. Instead of hand-coding every environment, what if we could teach AI systems to generate their own training worlds? This has been a tantalizing goal, but previous attempts have run into a fundamental problem: coherence. Generating a single convincing image is one thing. Generating a consistent, interactive world that maintains its properties over time is vastly harder.
What happens when you walk around a room? When you turn away from an object and then back again, you expect it to still be there, with the same properties it had before. This capability, which developmental psychologists call object permanence, emerges in human infants around 8 months of age. It's a foundational part of how we understand the world. Previous AI systems have struggled to maintain this kind of consistency for more than a few frames.

This is what makes Google DeepMind’s new Genie 2 model particularly interesting. It can maintain coherent, interactive 3D environments for up to a minute - orders of magnitude longer than previous systems. But I think the real breakthrough isn't the duration, it's how it achieves this consistency.
The system works through what's called latent world modeling. Rather than trying to remember and reproduce exact visual details, it maintains an abstract internal representation of the world state. When you give it an input image (say, a screenshot of a game environment), it first converts that image into this abstract representation space. Then as you interact with the world - moving around, pressing keys - it updates this internal model and generates new views consistent with both its model and your actions.
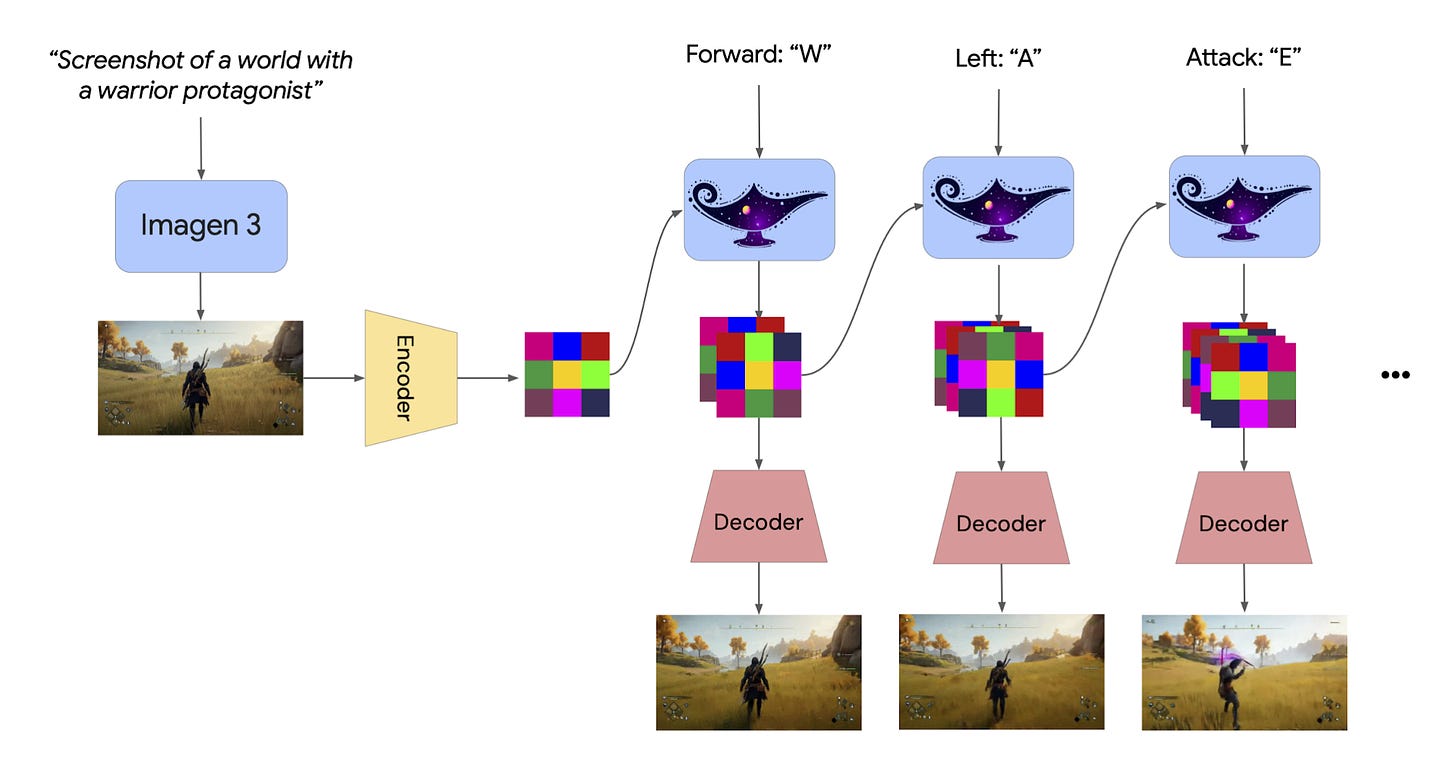
This approach mirrors how our own brains work in some interesting ways. We don't maintain pixel-perfect memories of scenes - instead, we keep high-level models of objects, their properties, and relationships. When we need to recall or imagine a scene, we reconstruct it from this abstract understanding. Genie 2's architecture suggests this might be a fundamental principle for any system that needs to maintain consistent world models.
The implications go far beyond just making prettier game environments. Traditional approaches to AI training use either manually created environments (limited and expensive) or randomized environments (unrealistic and inconsistent). Genie 2 points toward a third way: procedurally generated worlds that maintain meaningful consistency. This could dramatically accelerate how we train AI systems by providing unlimited varied but coherent training environments.
What makes this especially powerful is that the system learns various physical behaviors emergently, without being explicitly programmed for them (as shown in the example videos). It figures out that water should flow downhill, that solid objects shouldn't pass through each other, that light sources cast shadows and smoke rises - all as a natural consequence of trying to maintain consistent world states. This hints at how rich world models might naturally develop physical understanding through the constraint of maintaining coherence.
It's worth examining the limitations too. The system can only maintain consistency for about a minute before coherence starts to break down. This suggests its world model, while sophisticated, still lacks some key aspects of how our brains model reality. Understanding these limitations points to interesting directions for future research: How do our brains maintain consistent world models over much longer time periods? What additional architectural principles might be needed?
But looking ahead, this technology opens up some crazy interesting possibilities. For AI training, it could provide unlimited varied environments for reinforcement learning. For game development, it could enable rapid prototyping and testing (or even... playable games beyond dementia Minecraft). For creative tools, it could allow quick generation of interactive 3D spaces.
But perhaps most importantly, it pushes us to think more deeply about what it means to model and maintain a coherent understanding of the world in AI.
What do you think about Genie 2? Let me know in the comments. I’d love to hear what you have to say.



Comments ()