
How Sibylline built a cybersecurity offering while handling foundational LLM quirks
In this guest post, learn how the Sibylline team built a cybersecurity product using AI while overcoming LLM quirks

When working with the foundation LLMs, there are 2 main challenges that need some consideration; the first is handling the knowledge cut-off of the base model, and the second is hallucinations.
The GPT-4 cut-off window is September 2021. This means from a cyber security perspective, it’s missing several years worth of evolving trends, such as the sudden prevalence of supply chain attacks, the growth of the IoT sector, and the continued (albeit entirely predictable) rise in ransomware.
Hallucinations are caused by the LLM incorrectly stringing together a sequence of text that is incorrect, nonsensical, or not real. This can have interesting implications in a cyber security-specific AI model, particularly for the use cases we needed it to perform.
Our model was designed for 2 main use cases;
- Providing a single portal for our clients to ask cyber security-related questions to it, getting answers of a sufficient quality that they didn’t feel the need to ask our team
- Powering Safemail AI - our “zero config needed” email security product (try it out for free!)
The early knowledge cut-off meant that the model would struggle to reason about more recent changes in threats, leading it to downplay certain controls or risks, and hallucinations can cause it to incorrectly flag false positives as issues. This is particularly an issue for network-based alerts and indicators, due to their high entropy.
Foundation models are not exactly trained on a lot of technical alert telemetry, but we have been collecting this kind of data for 3 years and using it with some of the earliest foundation models to create primitive chatbots.
With this experience in hand, we fine-tuned GPT-4 with the latest version of this dataset. The most valuable part of the dataset is the hundreds of reports that actually reason about what actions need to be taken when certain events occur, and this is the most valuable feature that we needed from an LLM to make this solution work.
We can create plenty of information about a specific threat or piece of malware with very mature tools, but can we reason about their outputs?
Tuning a model is insufficient to handle the evolving nature of threats. We’d need to train a new model every day to keep it current with the ever-changing landscape to be effective.
To solve this, we employ functions to inject relevant data at runtime for the model to reason about.
We leverage a combination of commercial, open source, and internal sources of cyber threat intelligence (CTI) and make all of it available to the LLM as a function call, depending on what the LLM needs to know about.
Are users asking about specific IP addresses? Links they might have clicked in an email or attachments they’ve downloaded?
Each of these key CTI indicators has functions that return the output of mature cyber security tools that a typical analyst would go and run and then make decisions about. Now, you can simply use a solution like Delphi’s LLM-informed approach as your first line of interrogation and alerting to reason about those outputs.
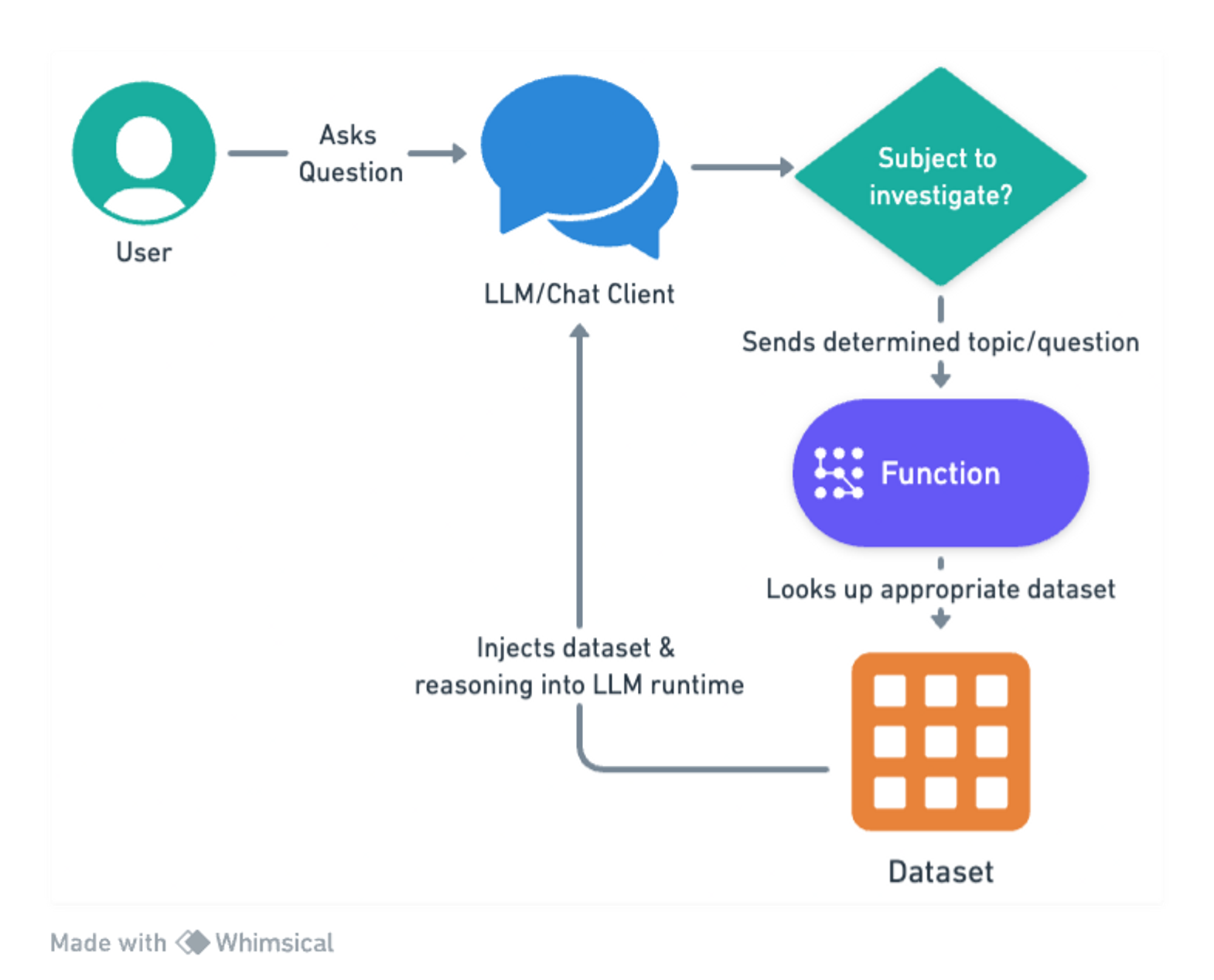
Because these are function calls, the data is always fresh and valid, since it is being read directly from the database. Incidentally, injecting this kind of information is very useful for defeating hallucinations as well. Returning accurate data for questions prevents the LLM from coming up with nonsense as it tries to guess what it might be.
You do need careful prompting for this to be effective. In our initial tests, returning semantically relevant data to the users' questions led the LLM to simply regurgitate the content back to the user rather than reason about it, which is not much better than performing a simple semantic search. We identified this as a prompting issue declaring that this information was “definitely relevant” rather than “potentially of use to you”. We were then able to resolve the issue with this framing and a few more iterations of prompting in that area.
Stick it all together, and you land up with a well-tuned LLM, that is able to reason about complex cybersecurity issues, and has the tools on hand it needs to answer specific questions about the latest threats.
You can check out Delphi’s ‘zero configs’ approach at Safemail.ai
Subscribe or follow me on Twitter for more content like this!



Comments ()