
Get ready to lose to Transformers on Lichess
They can hit 2895 Elo … without memorizing patterns
Hello everyone! AI has revolutionized strategy games, but a core question remains: can AI achieve top-level planning without memorizing strategies or using brute-force search?
As a 2k Elo player myself (brag?), I was pretty excited to see someone tried to answer this problem in a unique way for chess!
A top paper on AImodels.fyi today takes a novel approach by training large transformers to play chess without memorization or explicit search. Instead, it uses a benchmark dataset, ChessBench, built from 10 million human chess games.
By analyzing this dataset, the study trains transformers to make strategic moves “intuitively” on unseen chess boards—that is, without relying on memorized game patterns. The findings reveal how far transformers can go in mastering chess through generalization rather than memorization.
So how’s this all work?
Plain English Explanation
Imagine teaching a machine to play chess not by showing it every possible game but by helping it understand the game’s strategies. The machine would need to “think” rather than “remember.” This study attempts just that by using transformers—a type of AI model that usually handles language processing. These models are trained using ChessBench, a dataset with 10 million games, but instead of just copying game moves, they learn to evaluate new board positions and make smart moves. This setup eliminates the need for memorizing past games.
To test the transformers’ ability to plan moves in unfamiliar scenarios, the researchers trained models on this large dataset without any search-based tactics. The surprising outcome? These models learned to play at near-grandmaster levels, performing well even on tricky puzzles without any pre-planned sequences. This setup could revolutionize AI in planning tasks, as the transformer can generalize strategies without needing to remember specific scenarios.
Key Findings
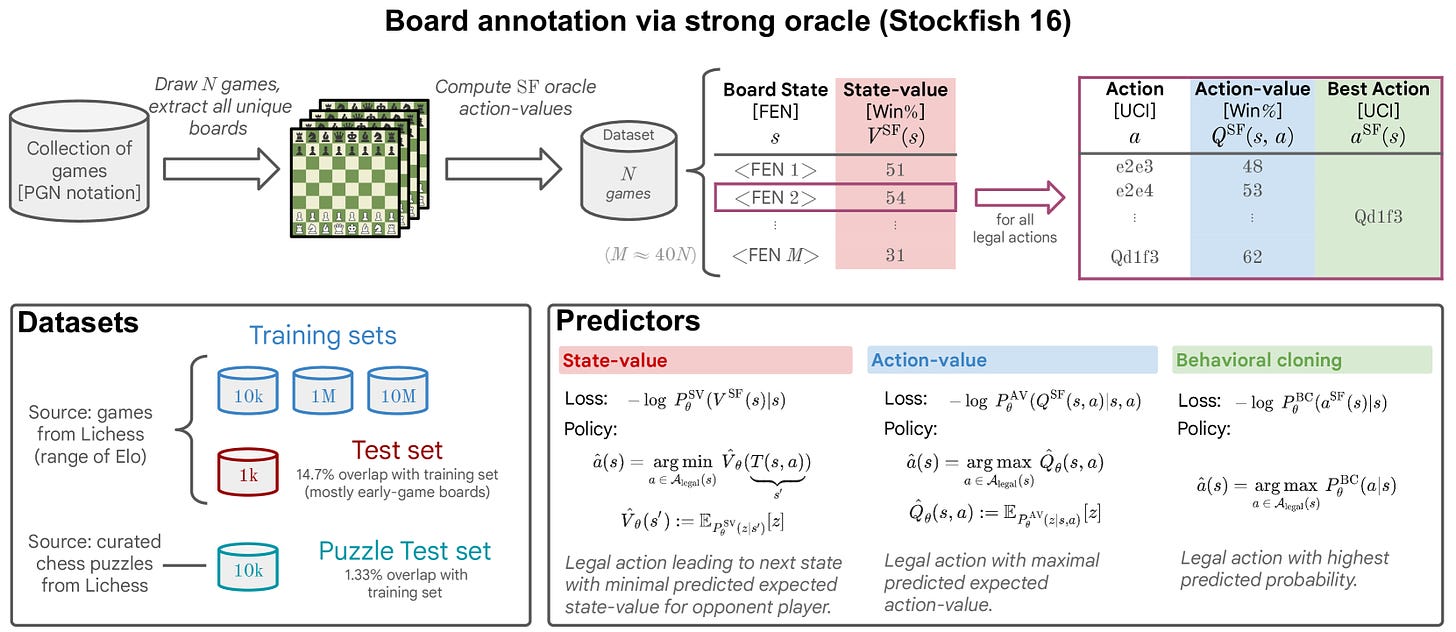
- ChessBench Dataset: ChessBench is a dataset with 10 million chess games annotated by Stockfish, a leading chess engine. This dataset helped train the transformer models on state and action values.
- Transformer Performance: With up to 270 million parameters, the models demonstrated a high level of chess play, achieving an Elo rating close to that of grandmasters (Lichess blitz Elo of 2895).
- No Memorization: The models could handle novel board positions, proving that the transformer learned strategy rather than relying on memorized moves.
- Comparison with AlphaZero and Stockfish: The transformer-based models almost matched AlphaZero and Stockfish without using search during play. This achievement shows that, with the right dataset and architecture, AI can generalize well on complex tasks like chess.
Technical Explanation
Like I said, to develop this AI model, the researchers used ChessBench, a chess dataset of 10 million human games. Each game position is labeled with state-values (likely outcomes) and action-values (recommended moves) provided by Stockfish. Training involved labeling board states as “bins” representing different levels of confidence or likelihood for moves.
The transformer models were trained on this dataset using supervised learning, with up to 270 million parameters. This training allowed the models to predict moves and evaluate the probability of success for each move based on board positions. Three training targets—action-values, state-values, and behavioral cloning—were tested to see which approach best supports chess planning.
Experiment Design and Findings
The AI models were tested with different architectures and compared against well-known chess engines like AlphaZero and Leela Chess Zero. Here’s what the tests involved:
- Action-Value Prediction: The transformer predicts which moves have the best outcome from all possible legal moves.
- State-Value Prediction: The model evaluates potential outcomes from a board state.
- Behavioral Cloning: The model mimics the moves of the top-rated chess engine.
The models performed remarkably well, achieving nearly grandmaster-level ratings, especially when predicting action-values. However, despite the strong performance, the models still fell short of engines like Stockfish when making quick, tactical moves.
Implications
This explosive study suggests that large transformers can handle planning problems without search algorithms. This could streamline AI development in strategic decision-making and could extend beyond games to real-world planning applications where search-based approaches are super impractical.
Critical Analysis
Like all good papers, there are limitations and caveats worth considering when we think about what this means for the field:
- Lack of Perfect Distillation: While transformers achieved some robust results, they couldn’t fully replicate Stockfish’s search-based approach. There is still a notable performance gap when speed and tactical precision are critical.
- Dataset Limitation: Although ChessBench is extensive, it only represents human play. As the transformer model improves, it may face limitations inherent in human-created games, possibly hindering further advancement without engine-derived datasets.
- Generalization Limitations: The transformers’ performance drops significantly when playing non-standard chess games, like Fischer Random Chess. This indicates that generalization to similar but non-identical scenarios remains a challenge.
Despite all these limitations, I still think ChessBench is pretty cool. I also think some future work could explore architectural innovations or more diverse datasets to help close the performance gap with engines like Stockfish.
Final thoughts
The study demonstrates that large-scale transformers can nearly match top chess engines without using search-based algorithms, proving (as many of you have suspected) that transformers can generalize complex strategies. As the technology matures, we might see transformers applied in various complex, real-world scenarios, from logistics to robotics, where generalization and adaptability are crucial.
Want to talk more about this paper? Join the discord!


Comments ()