
The Chosen One: Generating Consistent Characters from Text Descriptions Using AI
Among a large set of images from the same text prompt, some will naturally share common visual features.

Recent breakthroughs in AI-generated imagery via text-to-image models like DALL-E and Stable Diffusion have unlocked new creative possibilities. However, a persistent challenge is maintaining visual coherence of the same character across different generated images. Researchers from Google, Hebrew University of Jerusalem, Tel Aviv University, and Reichman University proposed an automated solution to enable consistent character generation in a paper titled "The Chosen One: Consistent Characters in Text-to-Image Diffusion Models." Let's see what they uncovered and how we can use it in our own work!

Subscribe or follow me on Twitter for more content like this!
The Context
Text-to-image models like DALL-E and Stable Diffusion contain deep neural networks trained on vast datasets to generate realistic images from text captions. They optimize text embeddings and image latents to align the generated image with the text description.
However, these models struggle to maintain consistency across multiple images of the same character, even when given similar text prompts. For instance, asking the model to generate "a white cat" may produce cats with differing fur patterns, colors, poses, etc. in each image.
This inability to preserve identity coherence poses challenges for applications like:
- Illustrating stories or textbooks with recurring characters
- Building unique brand personalities and mascots
- Designing video game assets and virtual characters
- Creating advertising campaigns with memorable spokespersons
Without consistency, characters change appearance unpredictably across images. Creators often resort to manual techniques like depicting the character in multiple poses first or carefully hand-picking the best results.
The Approach
To enable fully automated consistent character generation, the researchers proposed an iterative technique that funnels the model's outputs into a single coherent identity.
Their key insight is that among a large set of images generated from the same text prompt, some will naturally share common visual features. The core of their approach involves identifying and extracting this common identity.
Overview
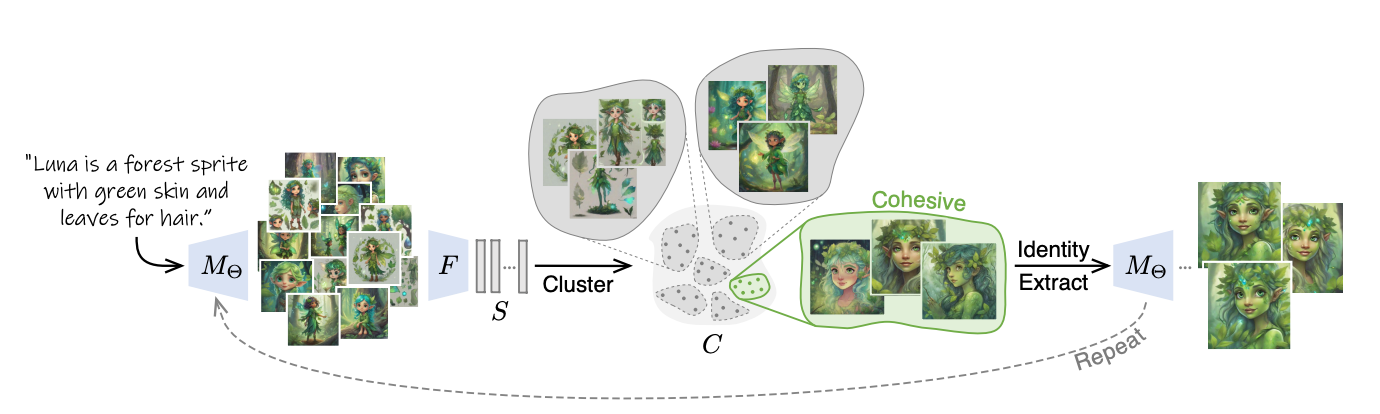
At a high level, their technique follows three repetitive steps:
- Generate many images for the input text prompt
- Cluster the image embeddings and find the most coherent cluster
- Refine the model's text embeddings to capture the identity in that cluster
By iterating this process, the model converges to a consistent representation of the character described in the text.
Image Generation
First, the method leverages a pre-trained text-to-image diffusion model (e.g. Stable Diffusion) to generate a batch of images from the input text prompt. Different random seeds are used so each image varies.
For example, given the prompt "A white cat with green eyes", the model may create 128 images, with cats in different poses and perspectives.
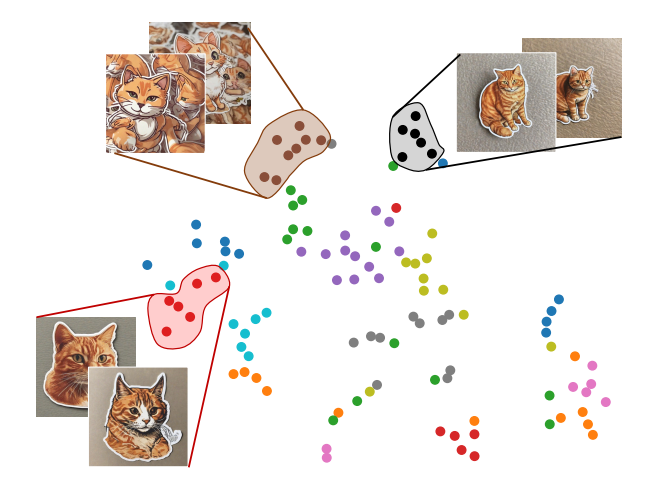
Identity Clustering
Next, each generated image is embedded in a high-dimensional feature space using a pre-trained feature extractor network. This condenses the image into a vector capturing its semantic identity.
These image embeddings are then clustered using K-Means clustering. The most coherent cluster is selected - i.e. the cluster with embeddings closest together. Images in this cluster likely share common visual characteristics.
Identity Extraction
The set of images in the selected cluster is used to refine the text-to-image model to capture their common identity. The researchers employ a technique called textual inversion to optimize new text embeddings specialized for that identity.
Additional model weights are also updated through a method called LoRA (low-rank adaptation) to better encode the specific visual features.
Iterative Refinement
The above steps are repeated, with each iteration generating images using the refined model from the previous loop. The refined model produces outputs more aligned to the emerging identity, funneling generations into visual coherence.
The process terminates once the average similarity between generated images converges, indicating a stable identity has been captured.
The Results
The researchers quantitatively evaluated their approach against other methods on automatically generated prompts spanning diverse character types and artistic styles.
Their technique achieved a better balance between accurately generating the input text prompt while maintaining a consistent identity. Human evaluations further reinforced these results.

Qualitatively, their approach produced coherent characters with greater diversity in poses and contexts compared to baselines. Even providing the same prompt multiple times generated visually distinct identities.
Limitations included occasional ambiguity in non-central characters and minor inconsistencies in secondary attributes.
The Implications
This work represents an important step toward AI creativity tools that can generate open-ended visual content with coherence and expressiveness. Models that maintain identity consistency better align with human creative processes.
Potential applications enabled by this advancement include:
- Automated visualization for storytelling and educational material
- Accessible character design without artistic skill
- Unique brand mascot and identity creation
- Reduced costs for advertising and video game asset creation
- Democratized character illustration for independent creators
However, like any generative technology, risks of misuse exist too. Consistent fake identity generation could empower disinformation campaigns and online scams. Further research into detecting artificial media is still important.
(Related reading: A new model detects deepfakes without needing any examples)
Overall, the method contributes fundamental progress in AI's aptitude for creative endeavors requiring continuity, opening possibilities for both responsible innovations and malicious exploitation. This dual-use nature underscores the need for social awareness as AI generation capabilities advance.
Subscribe or follow me on Twitter for more content like this!


Comments ()