
FACTOR: Detecting Deepfakes without Seeing Any Examples
As deepfake technology advances rapidly, we need better ways to detect them. Most current methods train on available deepfakes, but fail to generalize to new, unseen ones.
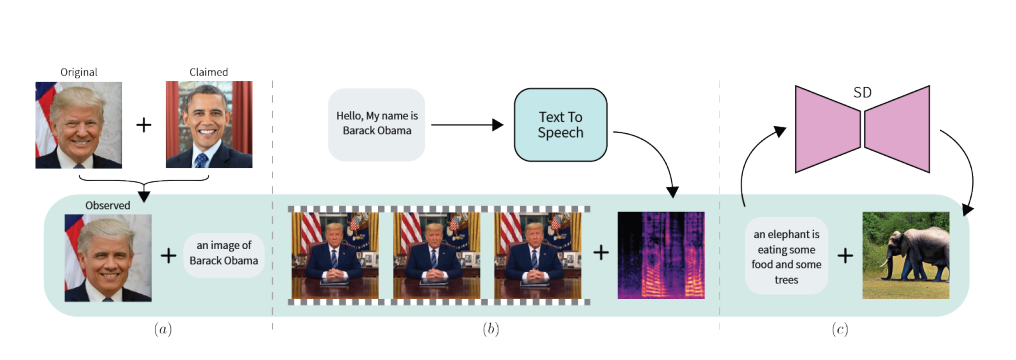
Deepfakes are a growing concern in our digital discourse, with the potential to further undermine trust online. As these AI-generated forgeries become more convincing, detecting them becomes increasingly challenging. Traditional methods falter, trained on datasets of known fakes, they struggle to identify new, unseen manipulations.
A new paper presents a fresh perspective. The authors introduce FACTOR, a detection method that shifts the focus from what's seen to what's claimed. Instead of looking for visual or auditory signals of tampering, FACTOR evaluates the consistency of the media with the real-world facts it represents. It questions if the person depicted is who the media claims they are, or if their words match their known voice or stance.
FACTOR stands out because it doesn't need a catalog of fakes to learn from. It performs a fact-checking operation, similar to methods used to spot fake news. How well does this approach work? What are its limitations? Let's find out.
Subscribe or follow me on Twitter for more content like this!
The Deepfake Detection Problem
Deepfakes leverage deep learning, especially generative adversarial networks (GANs), to manipulate media like images, video, and audio. Common tactics include face-swapping, puppeteering likenesses, and synthesizing speech. While some uses are harmless fun, deepfakes can also enable malicious disinformation campaigns, spoof identities, and violate privacy.
As generative methods advance rapidly, new deepfake techniques continually emerge. Classical detection methods relying on artifacts fail against modern fakes. Current state-of-the-art uses classifiers trained to discriminate real from fake media. But these supervised models only catch deepfakes similar to their training data. They cannot generalize to new, "zero-day" attacks - a major drawback.
Attackers often implicitly or explicitly make false claims alongside fakes, such as about a person's identity, speech, or appearance. This motivates verifying these claimed "facts". If current AI cannot perfectly encode false facts into deepfakes, checking for inconsistencies can reveal fakery.
FACTOR's Deepfake Detection Approach
FACTOR introduces a straightforward and robust strategy for detecting deepfakes by validating the media against its associated facts. Rather than relying on a database of known fakes for training, FACTOR employs readily available feature extraction technologies such as face recognition and audio processing networks to assess whether the media content aligns with the stated facts.
This approach encodes assertions about the media into mathematical statements where 'x' represents the media in question and 'y' stands for verified sources or established truths. FACTOR then evaluates these two entities to determine their congruence, assigning a "truth score" that reflects the degree of similarity in their encodings. A low truth score signals potential deception, as it indicates a discrepancy between the media's presentation and its purported facts.
The paper lays out a clear example: "Fact checking verifies that the claimed facts (e.g. identity is Obama), agree with the observed media (e.g. is the face really Obama’s?), and thus can differentiate between real and fake media."
For practical implementation, FACTOR is training-free, leveraging only real data for encoder training, thus sidestepping the need for a comprehensive catalog of deepfake examples. This simplicity extends to its application; for instance, in detecting face-swapped videos, FACTOR verifies if the person's identity in the media matches the recognized facial features. Similarly, in audio-visual manipulations, it checks whether the audio track aligns with the video segment, ensuring the integrity of the synchronization. The method is even applicable to text-to-image synthesis, where the authenticity of generated images is cross-referenced with the text prompts used to create them.
FACTOR's methodology is particularly effective because it tests the veracity of claims rather than the media's characteristics, thus exploiting the current limitations of AI in perfectly synthesizing factual details. This innovative approach allows FACTOR to identify deepfakes by highlighting inconsistencies without prior exposure to fake data. The approach's simplicity, combined with its effectiveness as demonstrated by its superior performance in benchmarks, underscores its potential as a practical and accessible tool in the ongoing effort to combat digital misinformation.
Experimental Results
In their experiments spanning three datasets—Celeb-DF, DFD, and DFDC—researchers showcased FACTOR's proficiency in detecting manipulated videos using identity-related information. Celeb-DF includes 590 authentic and 5,639 fake videos, derived from 59 identity pairs. The DFD dataset is comprised of 363 real and 3,068 synthetic videos, while the DFDC dataset, the largest and most challenging due to its diversity and new manipulation techniques, contains 1,133 authentic and 4,080 fake videos.
For the evaluation, videos were uniformly sampled down to 32 frames. Each identity's genuine videos were divided into halves for the purposes of training and testing. FACTOR employed the training half as a reference set, bypassing the need to train on deepfakes, unlike baseline models which were trained on these subsets. Assessments were conducted on a frame-by-frame basis, with results averaged across all identities within each dataset. The paper's Appendix A.1 provides comprehensive details on the implementation.
Within the context of zero-day deepfake attacks, FACTOR was tested using the DFDC dataset, which includes both genuine and fake images created by two different deepfake methodologies. It was benchmarked against several advanced detection models that were not exposed to the generation method used for the test deepfakes. Despite this handicap, FACTOR attained near-perfect accuracy, starkly outperforming the supervised baselines that showed limitations in zero-day scenarios.
Simulating a zero-day environment where datasets did not contain specific deepfake attacks, the researchers compared FACTOR against top-tier models trained on sizable external datasets. FACTOR emerged as significantly more effective, underlining its robust generalization ability over supervised methods, which commonly show a lack of adaptability when faced with varying datasets and attack methodologies. By leveraging a fact-checking approach, FACTOR eliminates the stringent requirement for in-depth training on deepfakes, thus enhancing performance and confirming its resilience against a spectrum of deepfake techniques.
Limitations
The limitations of FACTOR stem from its design and the nature of the deepfake detection problem. First, FACTOR's effectiveness is contingent on the presence of falsifiable facts; it cannot detect deepfakes that don't make specific, verifiable claims. For example, a deepfake without any associated identity claim would not be caught by this method.
Additionally, the method's dependency on feature extractors means that it might not work as effectively if the encoders for certain types of facts, especially less common ones, are not available or have not been developed yet.
Another limitation arises in scenarios where attackers create deepfakes without any explicit claims, also known as unconditional deepfakes. Since FACTOR's approach is to verify the truthfulness of claims made by the media, it cannot detect deepfakes that carry no claims.
Lastly, the method may not perform as well against sophisticated attacks that do not present noticeable inconsistencies between the claimed facts and the media. For example, if an attacker expertly overlays a claimed identity onto a video without introducing observable mismatches, FACTOR might not detect the forgery.
These limitations highlight areas for future research and development to enhance the capabilities of deepfake detection methods like FACTOR.
Conclusion
In conclusion, the FACTOR detection method represents a significant stride in the field of deepfake identification. By utilizing a fact-checking approach that compares claimed facts against observable media, FACTOR demonstrates a novel and effective way to discern authenticity in digital content. Its performance on benchmark datasets indicates a high level of accuracy, even when confronted with novel types of deepfakes.
However, FACTOR is not without its constraints. Its reliance on the existence of verifiable claims means it isn't suited to detecting deepfakes that don't make specific assertions. Furthermore, the current state of technology limits its application to facts for which feature extractors are available, and it may not catch deepfakes created without accompanying explicit claims.
Despite these limitations, FACTOR offers a promising framework that could be expanded upon as new advancements in AI and machine learning emerge. The approach capitalizes on the existing limitations of deepfake generation techniques, turning these weaknesses into a defense mechanism. Moving forward, the continued evolution of deepfake technology will undoubtedly necessitate further innovations in detection methods. FACTOR lays the groundwork for such advancements, pointing towards a future where the authenticity of digital content can be verified with greater confidence.
Subscribe or follow me on Twitter for more content like this!


Comments ()