
Adding an alpha channel to focus CLIP leads to better performance
Meet Alpha-CLIP: A CLIP model you can focus wherever you want
Contrastive Language-Image Pretraining, or CLIP, is a method used in AI that involves training a system to understand and link images and text. This process is like teaching a computer to connect a picture with the words that describe it. CLIP aligns these image and text 'translations' (embeddings) in a shared virtual space where the computer can compare and relate them. The image part of CLIP translates the visual elements into embeddings that a computer can analyze, capturing meanings or concepts associated with the elements in an image. The text part understands language as related concepts. This approach allows the computer to understand images beyond just labels, encoding rich context for use in a wide range of applications, from computer vision to multimedia and even robotics.
In this post, we'll take a look at a paper that proposes a new implementation of CLIP called Alpha-CLIP. The researchers have built a tool that they claim performs better due to guided attention and can even been swapped in directly into applications that use the base CLIP model. Let's see what they came up with and why their approach works.
Subscribe or follow me on Twitter for more content like this!
Specifying regions of interest
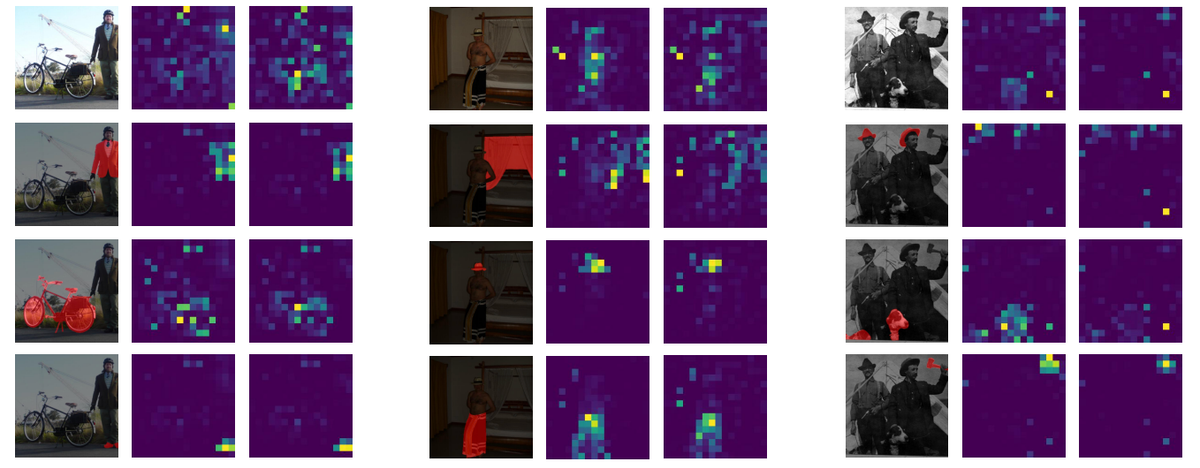
While CLIP is great at understanding entire images, often the most important parts are specific areas or objects within those images, like a single relevant object among many. Focusing on these specific parts or areas (regions of interest) allows for a more detailed understanding. It also makes it possible to control the generation of images by emphasizing certain parts. Being able to direct CLIP's focus to these user-defined regions opens up new capabilities that analyzing the complete scene doesn't offer.
(You may want to check out this article on related research: Researchers discover explicit registers eliminate vision transformer attention spikes)
People can point out these regions of interest by drawing rectangular outlines (bounding boxes) around objects, creating detailed outlines at the pixel level (pixel-level segmentation masks), or simply pointing to the areas needing focus. These indications can be provided manually or via automated perception models like object detectors.

Introducing Alpha-CLIP
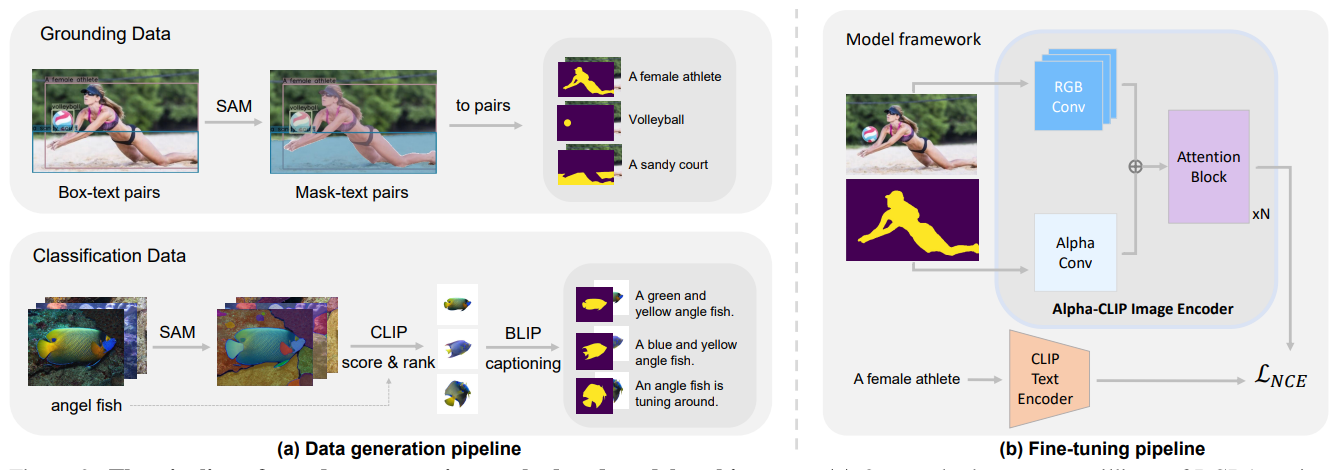
To incorporate region specificity into CLIP, researchers introduced Alpha-CLIP. It adds an extra layer (an alpha channel input) to the image part of CLIP. This layer works like a transparency map, showing the AI which parts of the image are important (foreground) and which are not (background). Alpha-CLIP starts with the original CLIP's ability to understand the entire image and then gets fine-tuned to also focus on these specified areas.
Architectural Details
Alpha-CLIP begins with the standard CLIP and modifies it by adding the capability to process both the regular image input and the new region-focus input (RGB and alpha inputs) in parallel. As the data goes through the layers of the neural network, Alpha-CLIP integrates both the overall image and the specified regions' information. It is trained to minimize the differences (contrastive loss) between the combined image-region embeddings and texts, ensuring the model understands both the entire image and the focused regions.
Performance
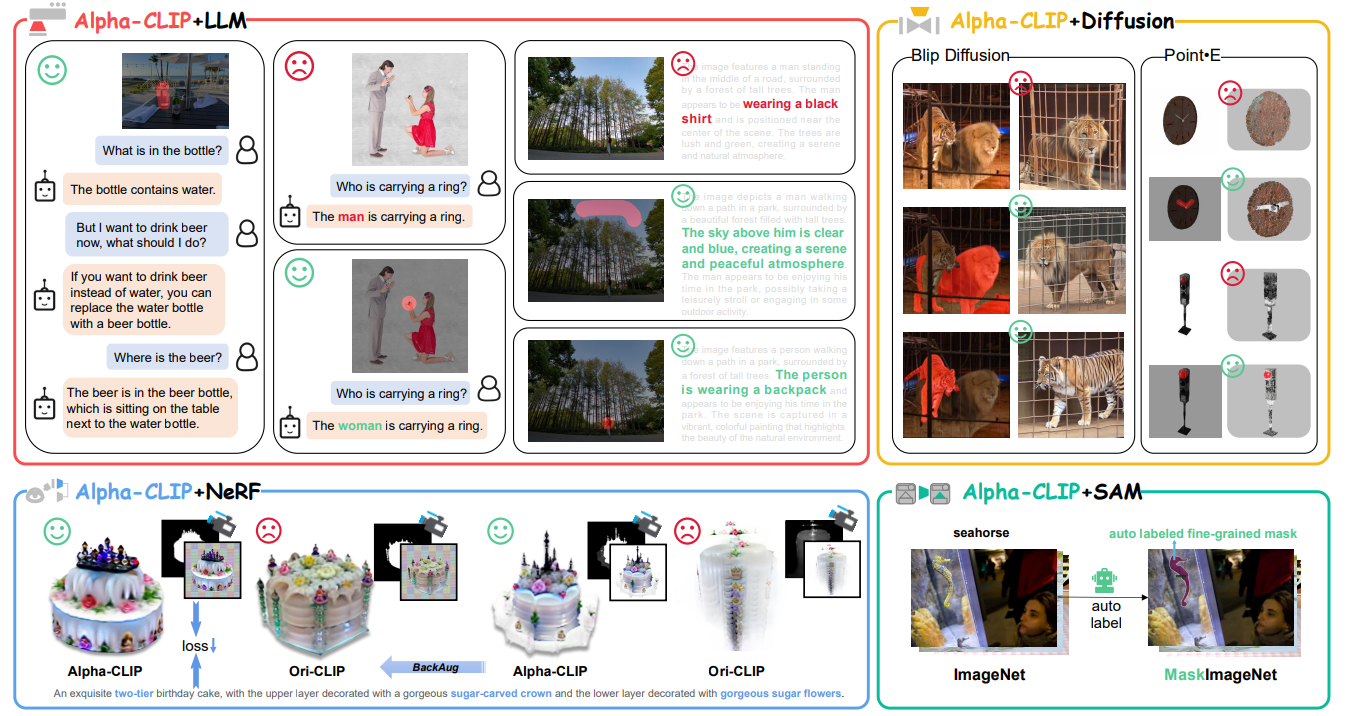
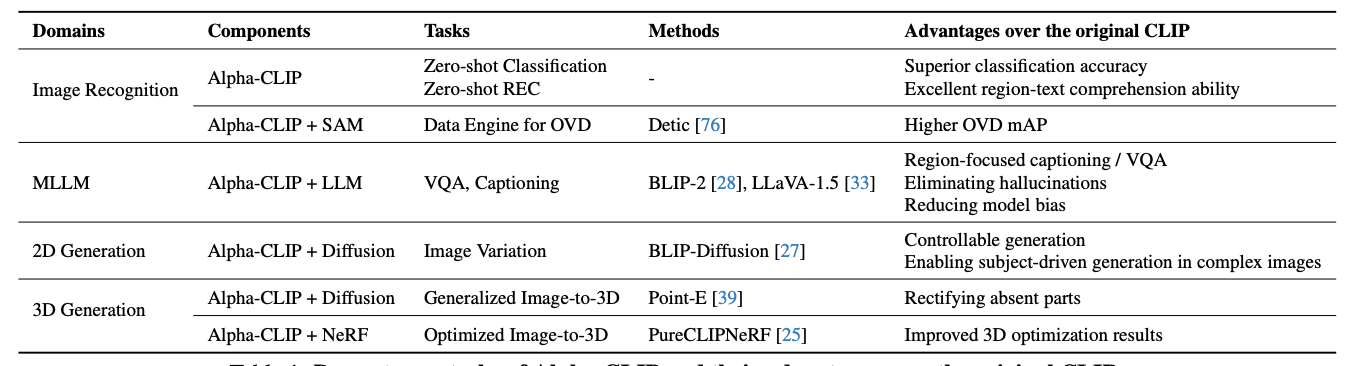
Alpha-CLIP shows improvements over CLIP in various areas. It's better at recognizing and focusing on foreground objects in images, accurately finding objects described in the text, and enabling multimedia models to describe and reason about specific image areas.
It also enhances text-to-image synthesis, allowing for focused creation in user-defined areas, and improves 3D shape and appearance optimization from text prompts, fixing gaps in complex scenes.
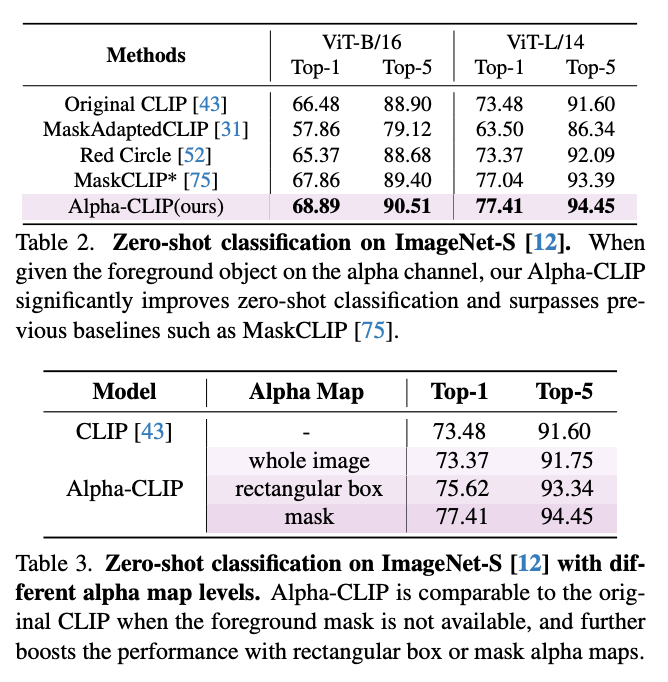
The table below shows some advantages Alpha-CLIP has over the original CLIP model.
Limitations and Future Work
The current version of Alpha-CLIP has some limitations, like handling multiple distinct regions at once and being restricted to binary (on/off) signals during training. Future improvements might involve more nuanced region indication and handling multiple areas simultaneously.
Overall, Alpha-CLIP represents an interesting step forward in augmenting models like CLIP with simple region guidance mechanisms, enabling more focused localization and control without losing the context of the entire image. This work opens new doors for research into focused region understanding in large pre-trained models like CLIP.
Subscribe or follow me on Twitter for more content like this!


Comments ()