
Enabling Language Models to Implicitly Learn Self-Improvement
Rather than manually distilling criteria into prompts, implicit information in preference data can be leveraged.
Recent years have seen remarkable advances in natural language processing capabilities thanks to the rise of large language models (LLMs) like GPT-3, PaLM, and Anthropic's Claude. These foundation models can generate human-like text across a diverse range of applications, from conversational assistants to summarizing complex information. However, as impressive as their abilities are, there is always still room for improvement when it comes to the quality and alignment of their text generation.
Typically, enhancing LLMs requires extensive human effort and expense to collect more high-quality and diverse training data. This process needs to be repeated continuously as expectations and use cases evolve. Detailed human annotation and oversight do not scale well, especially for specialized domains that require expert knowledge. So, researchers have been intensely exploring ways for LLMs to self-improve the quality of their own responses without direct human intervention.
A new paper by researchers from the University of Illinois and Google examines how to do just that. Let's see what they found!
Subscribe or follow me on Twitter for more content like this!
The Promise and Pitfalls of Prompting for Self-Improvement
Most methods proposed thus far involve techniques like prompting, where instructions or rubrics are provided to the LLM to critique and refine its initial responses. For example, the LLM may be asked to re-generate a response that corrects factual inaccuracies or provides more helpful information to the user. Prompting leverages the innate instruction following capacities of LLMs. You're probably pretty familiar with it if you've interacted with ChatGPT!
However, manually creating effective prompts for self-improvement is challenging even for humans. Defining comprehensive goals like making responses more "helpful" or metrics such as "likelihood of containing false information" can be difficult. Humans struggle to think of all possible aspects that should be covered by prompts. As a result, the LLM's efforts end up being restricted by the limitations of the rubrics provided.
Recent work has shown that just using a simple prompt like "Which summary is better?" yields much more disagreement with human judgments than a detailed prompt that asks "Which summary summarizes the most important points without including unimportant details?". Yet that level of engineering prompts specific to each scenario is impractical for real-world usage... it's simply too labor intensive to inspect prompts like this at a large scale.
Key Points
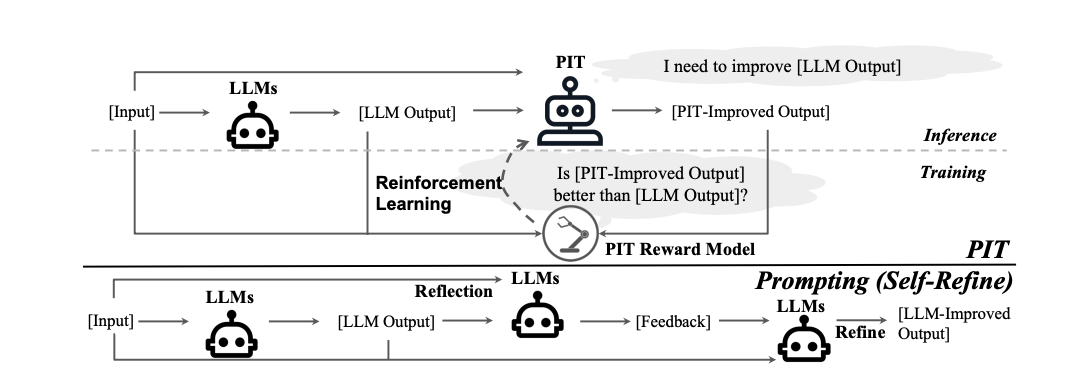
In today's paper, researchers propose PIT, a novel approach for LLMs to implicitly learn self-improvement from human preference data instead of prompts. How does PIT achieve this?
- It reformulates reinforcement learning from human feedback (RLHF) objective to maximize response quality gap conditioned on reference response
- It employs curriculum reinforcement learning, starting with easy-to-improve references then switching to the LLM's own samples
- The researchers then experimented on real and synthetic datasets to show PIT significantly outperforms prompting methods
The key insight from the research is that the preference data used to train the LLM already provides implicit guidance on what constitutes an improvement in quality. Rather than manually distilling criteria into prompts, this implicit information can be leveraged.
Technical Details on the PIT Approach
At a high level, the standard RLHF objective optimizes an LLM policy to maximize the expected quality of generated responses. PIT reformulates this to maximize the gap in quality between the original response and an improved response conditioned on having the original as a reference point.
The key is the training data that indicates human preferences between good and bad responses already provides implicit guidance on the dimension of improvement. This allows training a reward model to judge quality gaps without hand-engineering criteria into prompts.
In addition, PIT employs curriculum reinforcement learning with two key stages:
- Initialize by improving easy references like human-labeled bad responses
- Switch to improving samples drawn from the LLM itself
The second stage is crucial but highly challenging on its own. Starting with easier, less perfect references helps bridge the gap.
Through this approach, PIT is able to learn nuanced objectives like making responses more helpful, harmless, or relevant without prompts explicitly defining those criteria.
Experimental Results
Comprehensive experiments validate PIT's capabilities on two real-world dialog datasets, as well as one synthetic instruction-following dataset.
- Across conditions, PIT improved response quality by 7-34% compared to the original LLM samples as measured by third-party evaluator models. Further human evaluations reveal it also significantly outperforms the prompting method Self-Refine.
- Analysis of the impact of sampling temperature during generation finds lower temperatures around 0.4-0.6 work best for PIT, restricting diversity to focus improvement. In contrast, prompting methods need higher diversity to avoid just re-generating the original response.
- Ablation studies confirm the importance of the full curriculum reinforcement learning procedure. Removing either the first stage of easy examples or second stage of improving the LLM's own samples substantially degrades performance.
Overall the results strongly demonstrate PIT's capabilities for self-improvement and advantages over prompting approaches.
Why This Matters for the Future of LLMs
This work represents an important advance in enabling LLMs to refine themselves without direct human oversight. Prompting-based methods have proven effective but require extensive effort to engineer comprehensive rubrics, which is impractical to scale across diverse domains (especially domains that don't see many resources thrown their way).
PIT provides a way forward to learn nuanced goals like improving helpfulness, harmlessness, and accuracy by tapping into the implicit guidance within training data. No additional annotation or human involvement is needed beyond the usual preference data.
The techniques open the door to LLMs that continuously align better with human values as they learn from experience. Autonomous self-improvement will be critical as these models increase in capabilities and are deployed in sensitive real-world applications.
Reducing reliance on human intervention also facilitates expanding access to LLMs. Rather than being bottlenecked by annotation, they can learn to adapt to niche domains or under-served use cases that lack resources for oversight.
Of course, work remains to enhance PIT and address limitations. But overall it demonstrates tapping implicit information is a promising direction to imbue LLMs with more robust self-monitoring and refinement abilities.
Subscribe or follow me on Twitter for more content like this!


Comments ()