
Diffusion might be a better way to model probability in PPLs
DMVI uses diffusion models to approximate the probability distributions for faster, more accurate automated inference.
Probabilistic programming languages (PPLs), such as Stan, Pyro, and Edward, are specialized tools for modeling uncertainty in data. They allow users to build models that take into account the randomness present in real-world scenarios. Unlike traditional programming languages that do not natively incorporate probability models, PPLs have built-in features to describe randomness and uncertainty directly in their code. They automate complex statistical calculations, which makes them appealing for use in fields where uncertainty is a critical factor, from predicting stock market trends to understanding genetic variations.
The effectiveness of PPLs largely depends on their ability to perform what is called inference, which is the process of making predictions or drawing conclusions from data. Current inference methods in PPLs, like Markov chain Monte Carlo (MCMC) and variational inference, can be slow or inaccurate with complex data. MCMC methods are known for their precision but can take a very long time to compute, especially with large data sets. Variational inference methods are faster but can sometimes be too simplistic to capture the complexity of certain data, leading to less reliable predictions.
To overcome these issues, a new paper introduces the idea of employing diffusion models in PPLs (which have also been eyed for use in robot obstacle avoidance and anomaly detection, as I've written about previously). Diffusion models are a type of model that represents how data can change or 'diffuse' over time.
The authors propose an approach called Diffusion Model Variational Inference, or DMVI, that uses diffusion to approximate the probability distributions used in PPLs. They claim that DMVI can achieve generally greater accuracy on several benchmark models.
This post will take a look into how DMVI works and why its technique seems well-suited for probabilistic programming. Let's learn more!
Subscribe or follow me on Twitter for more content like this!
The Promise (and Limitations) of Probabilistic Programming
Probabilistic programming languages make it easier to build and work with models that deal with uncertainty — the kind of uncertainty you see in how particles move, how biological proteins fold, or how stock prices change. In the past, you needed a lot of statistical knowledge to build these models, but these programming languages help lower that barrier.
They simplify the process by removing the need to get into the nitty-gritty details of calculations. Instead, you just set up your model in a straightforward way, and the programming language picks the best calculation method for you. It then uses the data you have to make predictions. This makes it a lot easier for anyone to use complex modeling without getting bogged down in the difficult parts of the process.
Despite their transformative potential, current PPLs have some issues with their inferential algorithms:
- Markov chain Monte Carlo (MCMC) techniques, specifically Hamiltonian Monte Carlo (HMC), are recognized for their accuracy in approximating posterior distributions. However, they are computationally intensive and tend to scale poorly with large datasets or high-dimensional models, resulting in prohibitive run times.
- Variational Inference (VI) methods offer a speed advantage by transforming the inference into an optimization problem. Nevertheless, these methods can sacrifice flexibility and precision, particularly with complex models.
Improving the algorithms that make predictions based on data is key to making probabilistic programming languages more useful and easier for more people to use. This will help spread the use of advanced probability-based modeling in many different areas.
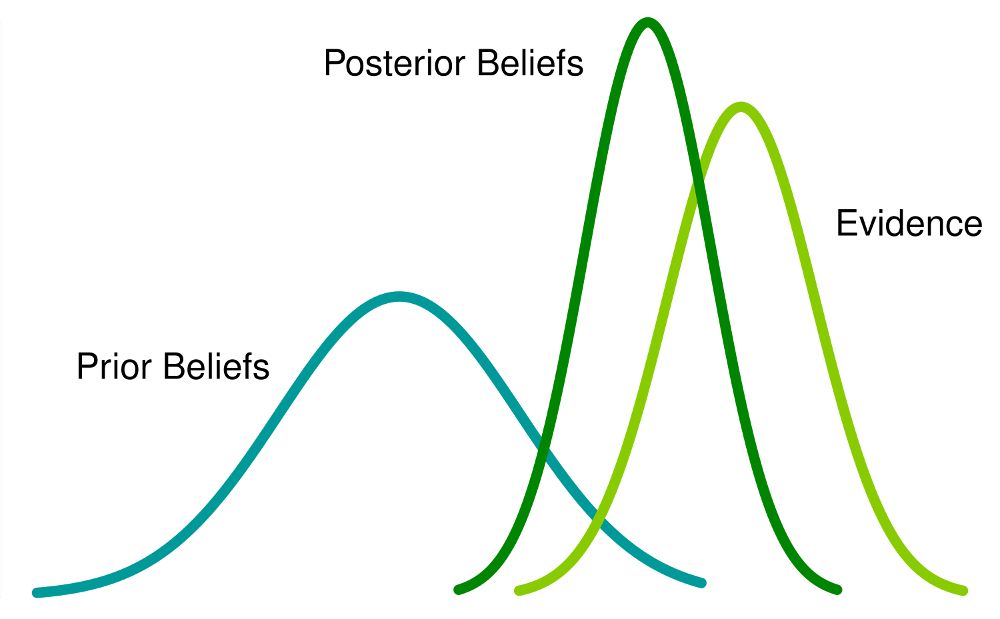
Aside: what is a posterior distribution?
A posterior distribution is a mathematical function that encapsulates what we know about an uncertain parameter after we've observed some data. In other words, it combines our prior knowledge about the parameter (before seeing the data) with the new information from the data itself to give us an updated belief about the parameter's likely values.
Here's a plain English breakdown:
- "Posterior" means "coming after," so this is about what we know after we've seen the data.
- "Distribution" in this context means a set of all possible values that a parameter could take, along with a probability for each value that tells us how likely that value is.
For example, if you're trying to guess the average height of trees in a forest, your prior might be a guess based on other forests. Once you measure a few trees, the posterior distribution would be your updated guess, which is more informed because it's based on actual data from the forest in question.
How DMVI Works
Diffusion Model Variational Inference (DMVI) is a new technique designed to make probabilistic programming languages (PPLs) better at predicting outcomes by using the latest diffusion models. Variational inference is typically about guessing the most probable outcomes based on given data. This process involves tweaking a guess distribution until it closely matches the real outcome distribution, and it's usually achieved by optimizing a mathematical function known as the marginal likelihood.
DMVI innovates by using what's called a diffusion probabilistic model to shape this guess distribution. This model starts with random noise and gradually transforms it to resemble the data, a process that can be driven by a neural network.
In practice, DMVI does several things:
- It sets up the guess distribution using a process that's essentially running a diffusion model in reverse.
- It introduces a new way to improve the calculation of the marginal likelihood, key to fitting the model to the data.
- It adjusts the score model parameters to get a better fit for the data.
- After training, it uses the refined model to make predictions.
One of the main benefits of DMVI is that it doesn't require a specific type of neural network to work. This gives DMVI a flexible edge, allowing it to train more adaptable models that can predict outcomes more accurately within the framework of variational inference.
Early Results Look Promising
The authors tested DMVI on a set of common Bayesian statistical models and compared its performance to existing VI methods like NFVI and ADVI. The early results look quite promising: "We evaluate DMVI on a set of common Bayesian models and show that its posterior inferences are in general more accurate than those of contemporary methods used in PPLs while having a similar computational cost and requiring less manual tuning."
These initial findings suggest DMVI may soon be a go-to technique for enabling accurate and flexible automated inference in real-world PPL applications.
Of course, more extensive testing is still needed to validate the approach. But it demonstrates how framing inference as a diffusion modeling problem can potentially overcome some of the limitations of both MCMC and variational methods.
The Future of Probabilistic Programming
Probabilistic programming has enormous potential to make probabilistic modeling more accessible and turbocharge applications like computational biology, finance, cosmology, and more. But realizing this potential depends in part on having effective algorithms for inference.
Diffusion model variational inference offers a novel way to bring the strengths of diffusion models into the inference process. If the promising early results hold up, DMVI could become a core part of the PPL toolkit alongside MCMC and variational methods.
This research direction shows the continued creativity being applied to improving automated inference. As I mentioned before, it's part of a trend I've seen where researchers are applying diffusion ML approaches to problems beyond just image and audio generation, like robot obstacle avoidance and anomaly detection.
As probabilistic programming matures, we may see increasingly sophisticated combinations of techniques adapted from areas like deep learning and simulation-based inference. This could take PPLs to new levels of usability and expand their practical applications dramatically.
I don't use PPLs much in my daily work, but if you do, this might be something to keep an eye on!
Subscribe or follow me on Twitter for more content like this!


Comments ()