
Researchers discover explicit registers eliminate vision transformer attention spikes
When visualizing the inner workings of vision transformers (ViTs), researchers noticed weird spikes of attention on random background patches. Here's how they fixed them.
Transformers have become the model architecture of choice for many vision tasks. Vision Transformers (ViTs) are especially popular. They apply the transformer directly to sequences of image patches. ViTs now match or exceed CNNs on benchmarks like image classification.
However, researchers from Meta and INRIA have identified some strange artifacts in the inner workings of ViTs. In this post, we'll do a deep dive into a new paper investigating the cause of these artifacts. And we'll see how researchers used a simple trick (not to sound too clickbait-y) to get models to focus on the subjects of images and not the boring background patches that tend to confuse them. Let's go.
Subscribe or follow me on Twitter for more content like this!
The Mysterious Attention Spikes
Much prior work has praised vision transformers for producing smooth, interpretable attention maps. These let us peek into which parts of the image the model is focusing on.
Oddly, many ViT variants show spikes of high attention on random, uninformative background patches. Why are these models focusing so much on boring, unimportant background elements instead of the mains subjects of these images?
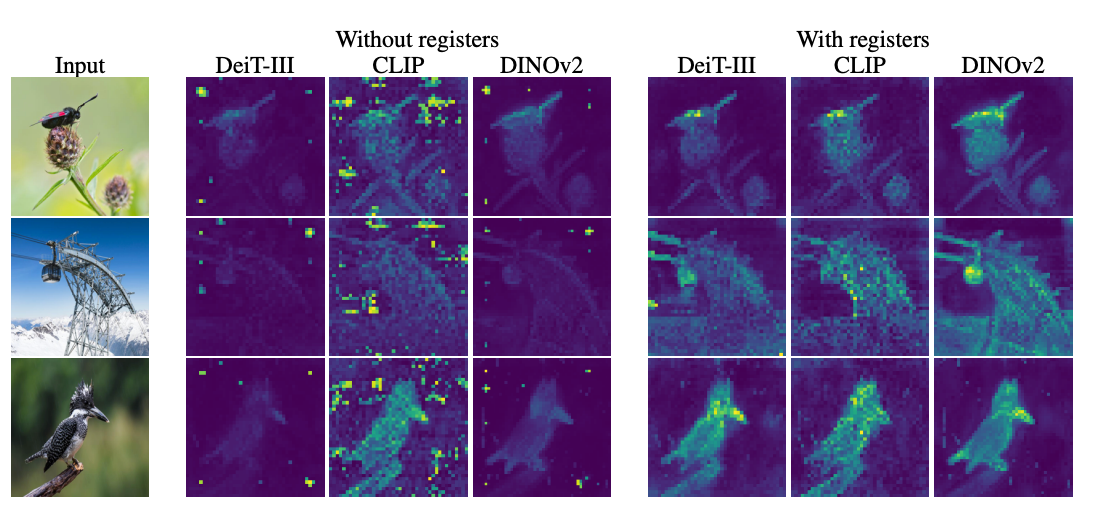
By visualizing attention maps across models and creating images like the one above, the researchers definitively show this happens in supervised versions like DeiT and CLIP, along with newer self-supervised models like DINOv2.
Clearly, something is causing models to inexplicably focus on background noise. But what?
Tracing the Cause: High-Norm Outlier Tokens
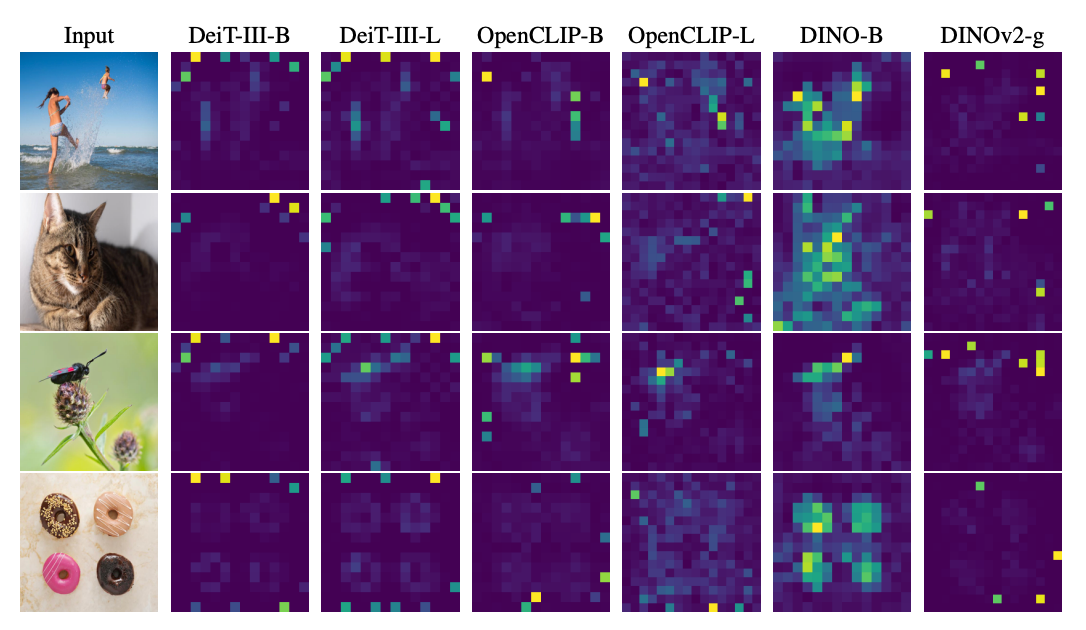
By numerically probing the output embeddings, the authors identified the root cause. A small fraction (around 2%) of patch tokens have abnormally high L2 norms, making them extreme outliers.
In the context of neural networks, the weights and biases of the neurons can be represented as vectors. The L2 norm (also known as the Euclidean norm) of a vector is a measure of its magnitude and is computed as the square root of the sum of the squares of its elements.
When we say a vector (e.g., weights of a neuron or layer) has an "abnormally high L2 norm", it means that the magnitude or length of that vector is unusually large compared to what is expected or typical in the given context.
High L2 norms in neural networks can be indicative of a few issues:
- Overfitting: If the model is fitting too closely to the training data and capturing noise, the weights might become very large. Regularization techniques like L2 regularization penalize large weights to mitigate this.
- Numerical Instability: Very large or very small weights can cause numerical issues, leading to model instability.
- Poor Generalization: High L2 norms can also indicate that the model might not generalize well to new, unseen data.
What does this mean in plain English? Imagine you're trying to balance a see-saw, and you have weights (or bags of sand) of various sizes to place on either side. Each bag's size represents how much influence or importance it has in balancing the see-saw. Now, if one of those bags is abnormally large (has a high "L2 norm"), it means that the bag is having too much influence on the balance.
In the context of a neural network, if one part of it has an abnormally high influence (high L2 norm), it might overshadow other important parts, which can lead to wrong decisions or over-dependence on specific features. This isn't ideal, and we often try to adjust the machine to ensure that no single part has too much undue influence.
These high-norm tokens correspond directly to the spikes in the attention maps. So the models are selectively highlighting these patches for unknown reasons.
Additional experiments reveal:
- The outliers only appear during training of sufficiently large models.
- They emerge about halfway through training.
- They occur on patches highly similar to their neighbors, suggesting redundancy.
Furthermore, while the outliers retain less information about their original patch, they are more predictive of the full image category.
This evidence points to an intriguing theory...
The Recycling Hypothesis
The authors hypothesize that as models train on large datasets like ImageNet-22K, they learn to identify low-information patches whose values can be discarded without losing image semantics.
The model then recycles those patch embeddings to store temporary global information about the full image, discarding irrelevant local details. This allows efficient internal feature processing.
However, this recycling causes undesirable side effects:
- Loss of original patch details, hurting dense tasks like segmentation
- Spiky attention maps that are hard to interpret
- Incompatibility with object discovery methods
So while this behavior emerges naturally, it has negative consequences.
Fixing ViTs with Explicit Registers
To alleviate the recycled patches, the researchers propose giving models dedicated storage by adding "register" tokens to the sequence.
This provides temporary scratch space for internal computations, preventing the hijacking of random patch embeddings.
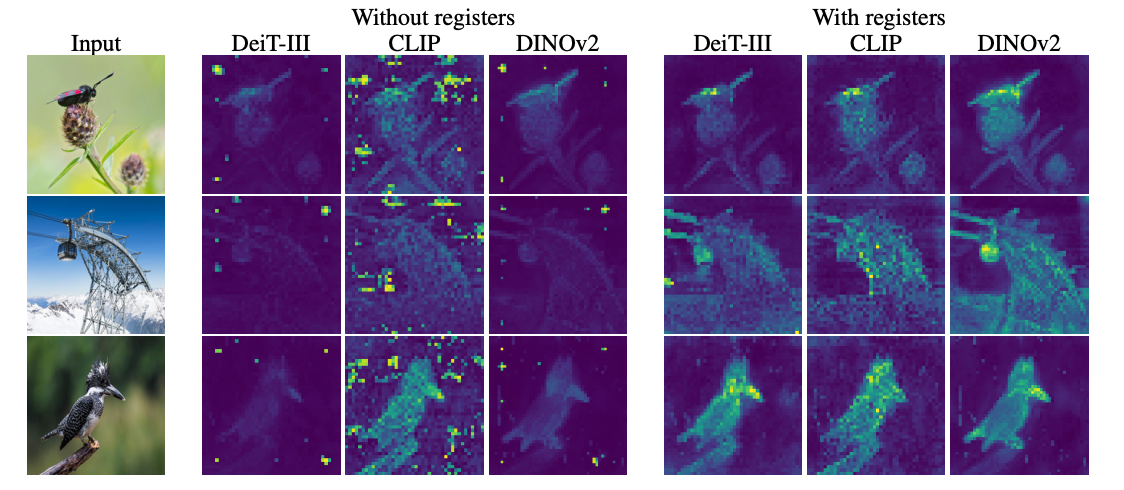
Remarkably, this simple tweak works very well. Models trained with registers show:
- Smoother, more semantically meaningful attention maps
- Minor performance boosts on various benchmarks
- Greatly improved object discovery abilities
The registers give the recycling mechanism a proper home, eliminating its nasty side effects. Just a small architectural change unlocks noticeable gains.
Key Takeaways
This intriguing study provides several valuable insights:
- Vision transformers develop unforeseen behaviors like recycling patches for storage
- Adding registers gives temporary scratch space, preventing unintended side effects
- This simple fix improves attention maps and downstream performance
- There are likely other undiscovered model artifacts to investigate
Peeking inside neural network black boxes reveals much about their inner workings, guiding incremental improvements. More work like this will steadily advance transformer capabilities.
The rapid pace of progress in vision transformers shows no signs of slowing down. We live in exciting times!
Subscribe or follow me on Twitter for more content like this!


Comments ()