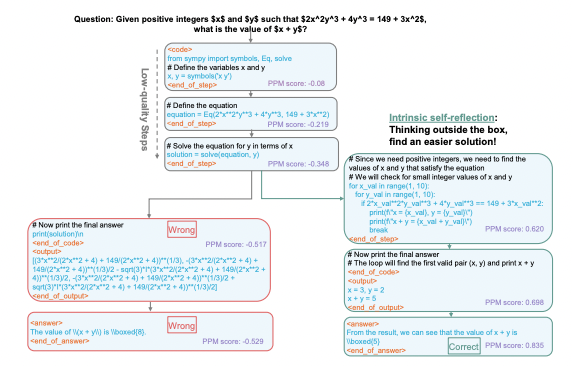
Plain English Papers Creating artificial doubt significantly improves AI math accuracy LLMs are better at math with a "verified reasoning trajectory" An example of intrinsic self-reflection during rStar-Math deep thinking (from the paper).
Netflix's VOID shows video editing has finally learned the laws of physics By treating object removal as a causal simulation rather than a pixel-patching job, VOID eliminates "ghost" physics from edited scenes