
Bye tokens, hello patches
Meta announces a better way to scale LLMs
Do we really need to break text into tokens, or could we work directly with raw bytes?
First, let’s think about how do LLMs currently handle text. They first chop it up into chunks called tokens using rules about common word pieces. This tokenization step has always been a bit of an odd one out. While the rest of the model learns and adapts during training, tokenization stays fixed, based on those initial rules. This can cause problems, especially for languages that aren’t well-represented in the training data or when handling unusual text formats.
Meta’s new BLT architecture (paper, code) takes a different approach. Instead of pre-defining tokens, it looks at the raw bytes of text and dynamically groups them based on how predictable they are. When the next byte is very predictable (like finishing a common word), it groups more bytes together. When the next byte is unpredictable (like starting a new sentence), it processes bytes in smaller groups.
This dynamic approach leads to three key benefits:
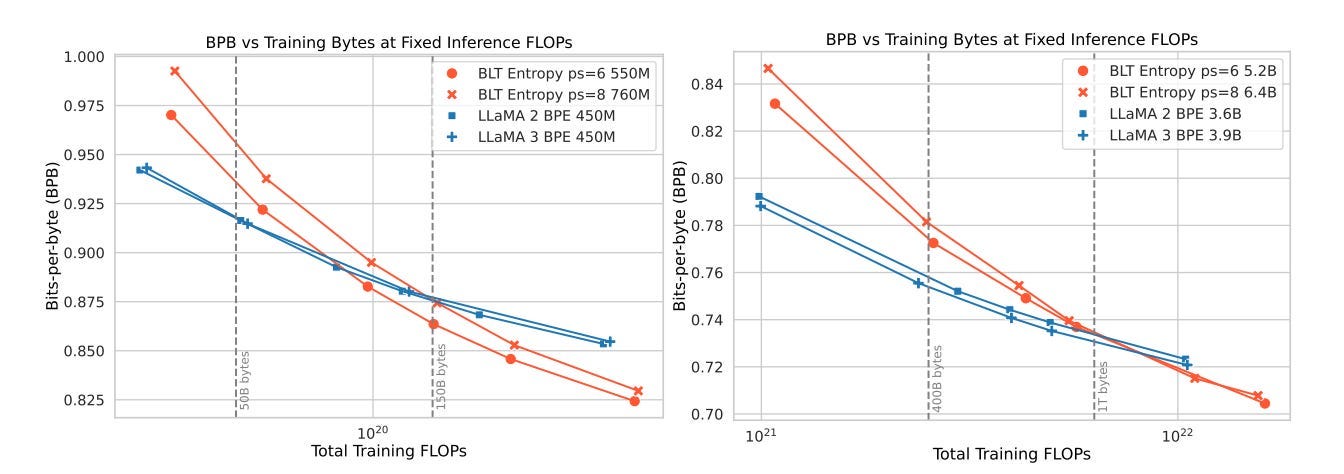
First, it can match the performance of state-of-the-art tokenizer-based models like Llama 3 while offering the option to trade minor performance losses for up to 50% reduction in inference flops. The model saves resources by processing predictable sections more efficiently.
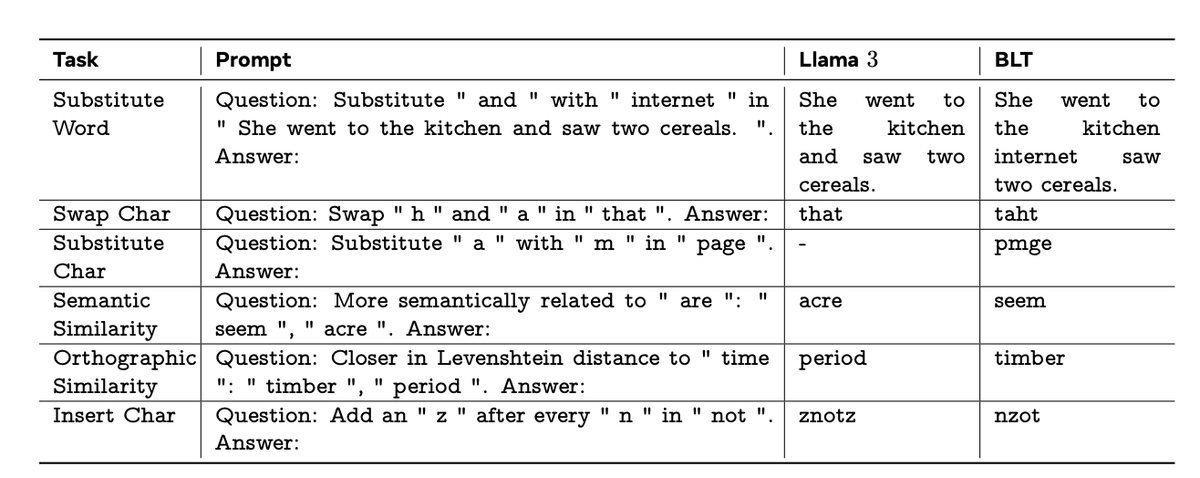
Second, it handles edge cases much better. Consider tasks that require character-level understanding, like correcting misspellings or working with noisy text. BLT significantly outperforms token-based models on these tasks because it can directly access and manipulate individual characters.
Third, it introduces a new way to scale language models. With traditional tokenizer-based models, you’re somewhat constrained in how you can grow them. But BLT lets you simultaneously increase both the model size and the average size of byte groups while keeping the same compute budget. This opens up new possibilities for building more efficient models.
To understand how BLT works in practice, let’s look at its three main components:
- A lightweight local encoder that processes raw bytes and groups them based on predictability
- A large transformer that processes these groups (called “patches”)
- A lightweight local decoder that converts patch representations back into bytes
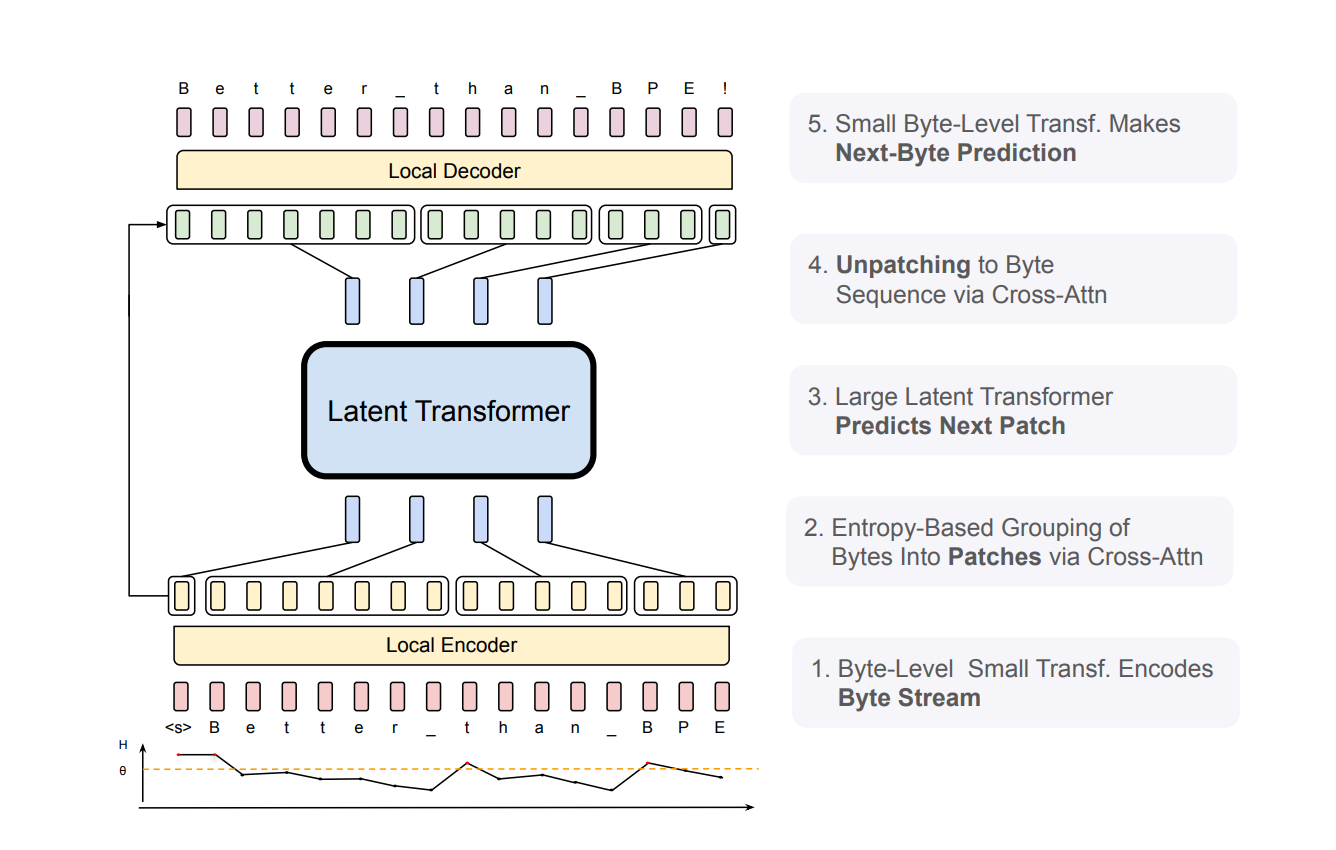
The entropy-based grouping is particularly clever. BLT uses a small language model to predict how surprising each next byte will be. When it encounters a highly unpredictable byte (like the start of a new word), it creates a boundary and begins a new patch. This way, it dedicates more computational resources to the challenging parts of the text while efficiently handling the easier parts.
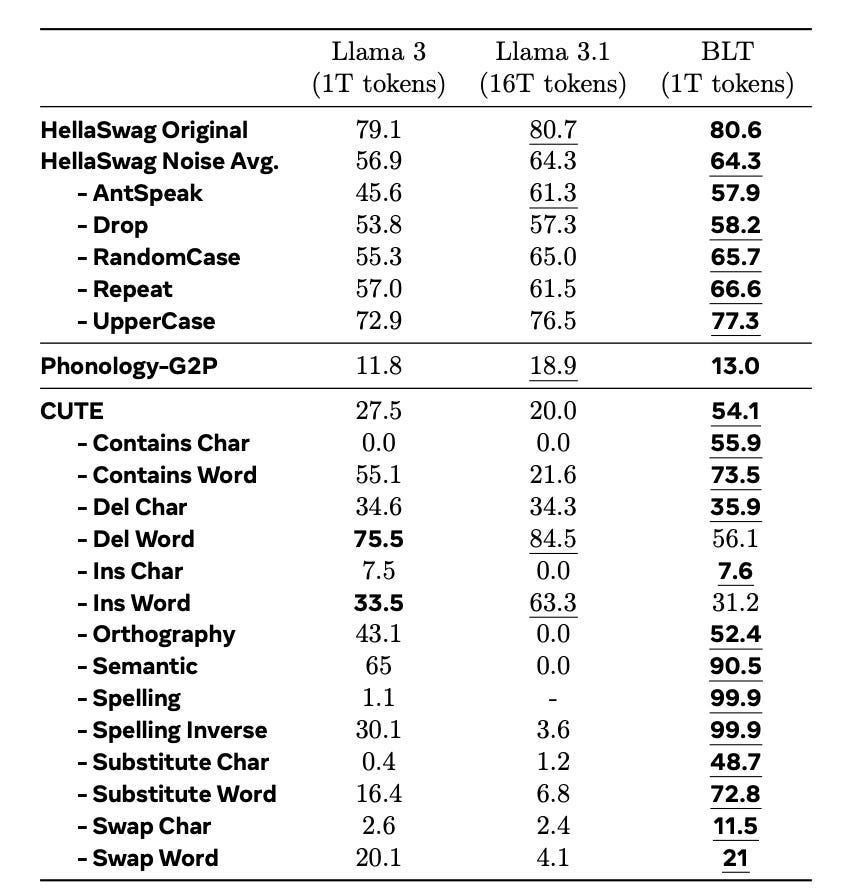
I like the results. On standard benchmarks, BLT matches or exceeds Llama 3’s performance. But where it really shines is on tasks requiring character-level understanding. For instance, on the CUTE benchmark testing character manipulation, BLT outperforms token-based models by more than 25 points — and this is despite being trained on 16x less data than the latest Llama model.
This points to a future where language models might no longer need the crutch of fixed tokenization. By working directly with bytes in a dynamic way, we could build models that are both more efficient and more capable of handling the full complexity of human language.
What do you think about this approach? Does removing the tokenization step seem like the right direction for language models to evolve? Let me know in the comments or on the AImodels.fyi community Discord. I’d love to hear what you have to say.



Comments ()