
Bringing Still Pictures to Life with Neural Motion Textures
Google researchers published a new technique to animate still photos by predicting how each pixel should move over time
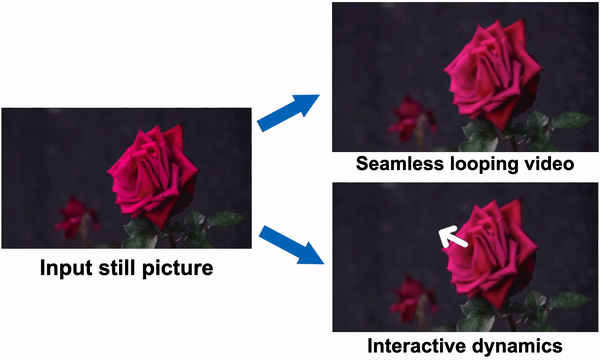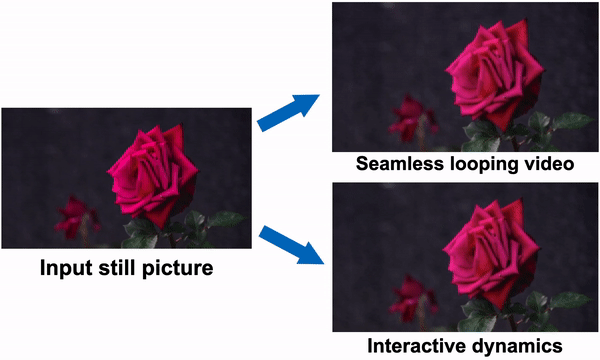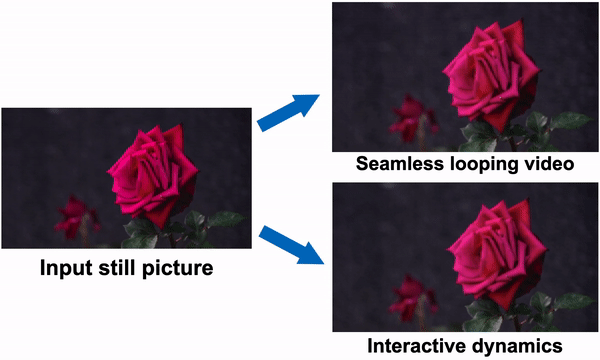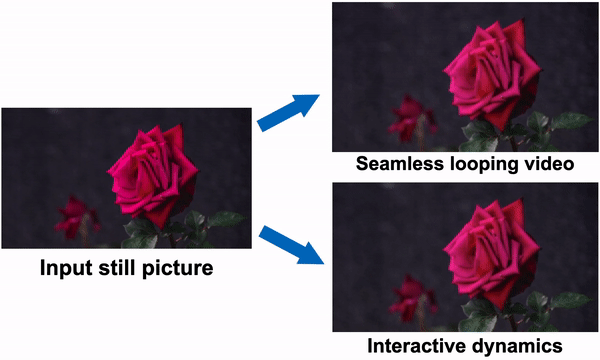
Imagine glancing at a picture of a tree blowing softly in the wind or a candle flickering quietly on a table. Even though it's a still image, you can envision how the leaves and flames are swaying and oscillating. What if we could actually see them come to life as videos? Well, researchers from Google recently published a paper on a technique to do exactly that using "neural motion textures."
In this post, we'll cover how it works, why it matters, and the possibilities it unlocks for generative AI. Read on to learn how still photos can be animated with realistic motion from just a single static picture.
Subscribe or follow me on Twitter for more content like this!
The Challenge of Video Generation
Thanks to rapid advances in AI over the past few years, we now have systems that can generate highly realistic synthetic images from scratch based on text descriptions. However, generating equally realistic videos has proven far more difficult.
Naively extending image generators to produce videos often results in artifacts like flickering textures or objects that don't move properly and violate physical constraints. That's because video adds the complexities of modeling motion and maintaining coherence over time. Humans are exceptionally good at interpreting motion signals and imagining how a scene could play out. Replicating that remains an open challenge in computer vision and graphics research.
Neural Motion Textures for Animation
To address this problem, researchers from Google Brain proposed using "neural motion textures" to animate photos. Their key insight was that for many common real-world scenes with natural repetitive motions like swaying trees, flickering flames, or rippling water, the dynamics can be represented as a stochastic "texture" in the frequency domain.
Essentially, they model scene motion using mathematical functions that characterize the oscillating trajectories of each pixel over time. This builds on prior work in graphics that represented motions like human cloth simulation with low-frequency Fourier basis functions.
The researchers leverage recent advances in generative AI to learn a model that takes a single still picture as input and predicts a neural motion texture depicting plausible dynamics for that specific scene.
Specifically, it uses a conditional latent diffusion model, trained on thousands of videos of natural motions, to output a "stochastic motion texture." This texture captures multi-modal distributions over possible motions for each pixel in a compressed frequency-space representation.
Generating motion textures instead of raw pixel values allows sampling temporally consistent long-term motions needed for video generation. It also enables fine-grained control over properties like speed and magnitude.
Turning Still Photos into Video
To actually render video frames, an image-based neural rendering network uses the predicted neural motion texture for guidance.
It begins by transforming the frequency representation into a sequence of pixel displacement maps over time using an inverse Fourier transform. Then it warps and blends the input photo guided by the displacements to synthesize each output frame.
This approach explicitly modeling scene motion gives the system more understanding of the underlying dynamics compared to treating video as simply a sequence of individual frames.
Advantages Over Prior Techniques
In experiments, videos generated using neural motion textures significantly outperformed other state-of-the-art single image animation methods across quantitative metrics and human evaluations.
The motions and textures also appeared more natural and realistic to human viewers compared to approaches that directly output raw pixel values. That's because modeling dynamics provides better coherence over longer time horizons.
Representing scene motion also enabled creative applications like controlling speed, applying motion transfer, or adding interactivity. For example, they showed how users can grab and jiggle objects in still photos to simulate dynamics.
Limitations and Future Work
Some limitations are that the approach works best for smoothly oscillating motions rather than abrupt, sudden movements. Also, image-based rendering can degrade if there are large disoccluded regions not visible in the original photo.
Nonetheless, neural motion textures demonstrate a promising new technique for generative AI. Modeling the stochastic dynamics of our visually rich world unlocks new capabilities in image and video editing tools. It also moves us closer toward artificial intelligence that more deeply understands motion and physics.
The researchers suggest several exciting directions for future work like extending the approach to model non-repetitive motions, generating sound from motion, or applying similar ideas to 3D scene dynamics. Overall though, animating still images illustrates rapid progress toward replicating human imagination with AI.
Subscribe or follow me on Twitter for more content like this!


Comments ()