


Mike Young

What's the best AI model to handle $1 million in freelance software engineering?
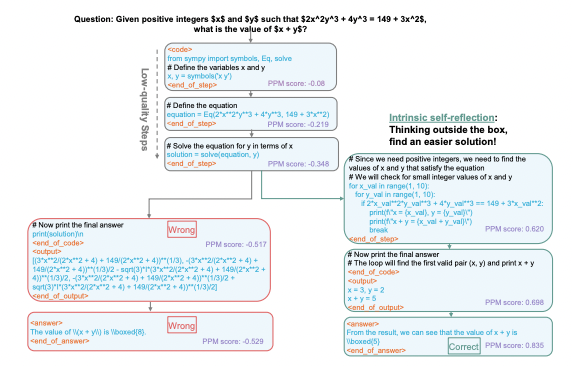
Creating artificial doubt significantly improves AI math accuracy

Step-by-step reasoning can fix madman logic in vision AI
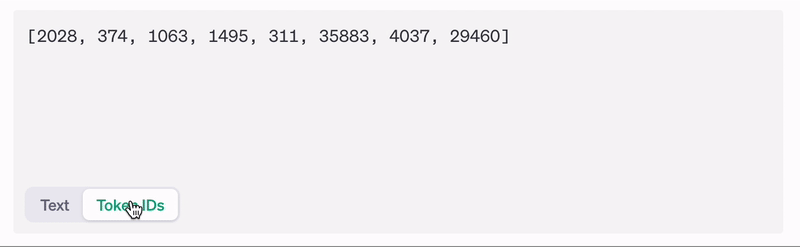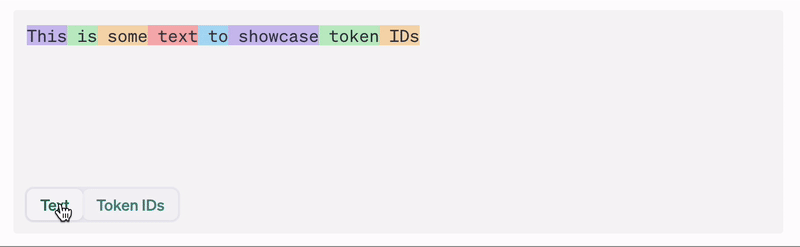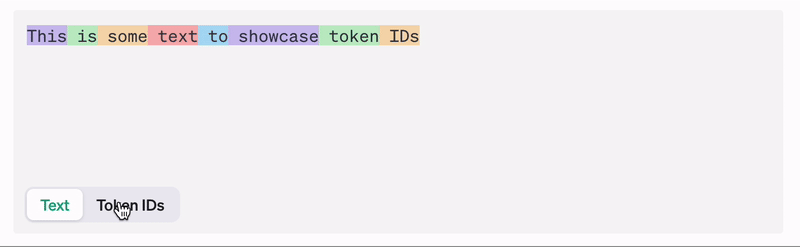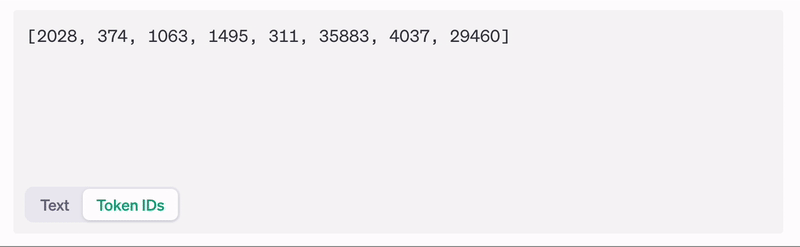
All LLMs use tokenization. Are we doing it totally wrong?
Slashing model size by 85% while redefining how we build adaptable, efficient LLMs

Can image models understand what we’re asking for?
High-quality graphics vs high-quality understanding — which one matters more?
