
Apple is working on multimodal AI. Here's what they've uncovered so far.
Apple researchers reveal scaling laws and training methods for multimodal AI success.
What if I told you that behind the recent buzz about multimodal AI, a quiet revolution has been brewing at Apple? A team of researchers there has been systematically studying how to build the most capable multimodal models, uncovering key insights that challenge conventional wisdom. And now, they're giving us a rare glimpse under the hood.
Their work could change how we approach multimodal projects. But to understand why, you'll need to grasp the nuances of their methods and findings. That's why I've poured over their dense research paper to break it all down for you.
In this post for paid subscribers, I'll cover:
- The specific architectural tradeoffs they tested and what really matters most
- How they achieved state-of-the-art few-shot learning by mixing data in a very intentional way
- Why their scaling laws and training approaches are vital for anyone building multimodal models
- Concrete examples of their model's impressive capabilities, from multi-image reasoning to OCR
- My take on the potential implications of this work and some open questions it raises
This post will give you both a rigorous technical understanding and an accessible plain-English overview of the key ideas. By the end, you'll have a solid grasp of this groundbreaking research and how it could shape the future of AI.
Ready to dive in? This one is exclusive for paid subscribers — if you haven't yet, now's a great time to subscribe so you can access the full analysis. It directly supports my work in breaking down cutting-edge AI research.
Let's begin!
AIModels.fyi is a reader-supported publication. To receive new posts and support my work subscribe and be sure to follow me on Twitter!
Introduction
Multimodal AI has seen rapid progress, with models like Flamingo, EMu2, and MoLLa showcasing the potential of combining vision and language understanding. However, many of these models provide limited insight into the rationale behind their architectural choices and training procedures.
Apple's MM1 paper introduces a family of multimodal AI models and provides significant insights into building highly capable systems that combine vision and language understanding. Through extensive ablation studies and systematic experiments, the team has uncovered key insights into building highly capable multimodal models. Their findings shed light on the relative importance of different architectural choices, data mixing strategies, and scaling approaches.
By sharing their "recipe" for state-of-the-art few-shot learning, the authors are enabling the broader research community to build upon their work. Down the line, the techniques pioneered here could power a new generation of foundation models that deeply integrate vision and language understanding.
In this piece, I'll walk through the key sections of the paper — covering their methods, results, discussion, and conclusions. I'll explain the technical details, while also providing a plain English interpretation focused on the core ideas and their significance. Along the way, I'll share my own analysis and highlight some open questions raised by the work.
Technical Explanation
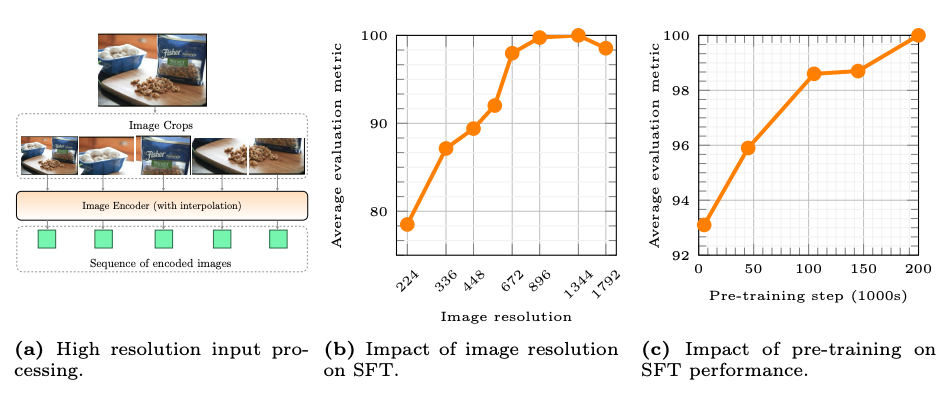
The authors set out to study how to build performant multimodal language models (MLLMs). They systematically analyze two key factors: 1) architecture components like the image encoder and vision-language connector, and 2) data choices in pre-training.
To efficiently assess design choices, they use a base configuration with a 1.2B parameter LLM. They conduct ablations by modifying one component at a time and evaluating impact on zero-shot and few-shot performance across VQA and captioning tasks.
For architecture, they test different pre-trained image encoders (varying objective, data, and resolution) and vision-language connectors. For the vision-language connector, they test average pooling, attention pooling, and a convolutional ResNet block called C-Abstractor. Surprisingly, the specific connector architecture had little effect on performance. For pre-training data, they use mixes of captioned images, interleaved image-text documents, and text-only data.
Results
The final MM1 family, scaled up to 30B parameters with both dense and mixture-of-experts (MoE) variants, achieves SOTA few-shot results on key benchmarks vs Flamingo, IDEFICS, EMu2.
On the architecture side, they find (in order of importance):
- Image resolution has the biggest impact, giving a ~3% boost going from 224px to 336px
- Image encoder size and pre-training data also matter, with a modest <1% lift going from ViT-L to ViT-H
- Vision-language connector design choices have negligible effect
For pre-training data:
- Interleaved data is crucial for few-shot and text-only performance, giving 10%+ lift
- Caption data improves zero-shot the most
- Synthetic captions help few-shot (+2-4%)
- Careful mixing of modalities (5:5:1 ratio of captions, interleaved, text) works best
The final MM1 model, scaled up to 30B parameters, achieves SOTA few-shot results on key benchmarks vs Flamingo, IDEFICS, EMu2.
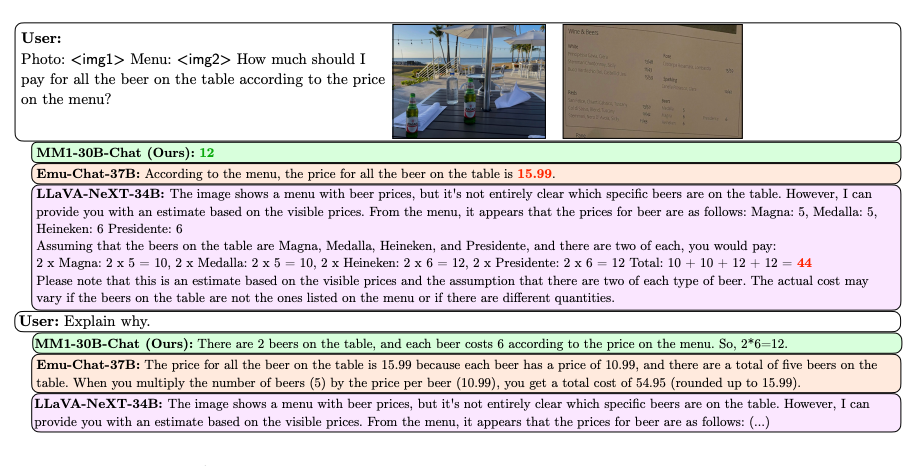
The authors show their pre-training insights hold after supervision fine-tuning (SFT). MM1 exhibits compelling properties like multi-image reasoning, OCR, in-context few-shot learning.
The MM1 recipe of intentional architecture and data choices leads to high performance when scaled up. The authors hope these insights will generalize beyond their specific implementation.
Plain English Explanation
Here's the gist: Apple researchers did a bunch of experiments to figure out the best way to build AI models that understand both images and text.
They tested different model components, like the part that encodes the image and the part that connects the image and text. They found that some things matter a lot (image resolution, encoder size/data), while others really don't (connector design).
They also played with mixing different kinds of data while training the model. Stuff like captioned images, documents with text and images mixed together, and just plain text. The key seems to be having a variety - this helps the model handle different situations, like describing images or answering questions.
When they put it all together and made the model really big (30 billion parameters!), it was the best in the world at learning from just a few examples. And it can do cool things like reason over multiple images, read text in images, and even explain its own outputs.
So in a nutshell: the secret sauce is being intentional about model components and training data. By sharing their recipe, these researchers are paving the way for a whole new generation of powerful multimodal AI systems.
Critical Analysis
Let's consider some caveats and limitations of the MM1 work:
- Evaluation benchmarks: The authors note that current eval sets are centered around captioning. Models optimized for this may not generalize to other multimodal tasks. We need more diverse benchmarks.
- Scaling laws: Extrapolating hyperparameters to larger scales is risky. Stability issues may emerge that didn't show up in small-scale tests. Careful monitoring is needed when training big models.
- Synthetic data: While synthetic captions helped, generated data has limits. Over-optimization could lead to weird failure modes. Use with caution.
- Bias/Fairness: No analysis of social biases in outputs or training data. For responsible deployment, this needs scrutiny, especially with web-scraped data.
- Hardware access: Ablations used a 1.2B model, but final system is 30B. Insights may be less applicable with limited compute. We need to study "small-model" design too.
The authors do acknowledge room for improvement, e.g. scaling vision encoder, enhancing vision-language bridge, iterating on eval suite.
Beyond the limitations they acknowledge, I think there are some deeper questions about the MM1 approach that warrant discussion. For instance, the heavy reliance on web-scraped data raises concerns about the representativeness and potential biases of the training set. It's also worth considering whether the specific architectural choices and scaling laws identified here will generalize to other modalities beyond vision and language, or to more open-ended generative tasks. Engaging with these broader debates in the field would strengthen the impact of the work.
Conclusion
So what can we take away from Apple's MM1 paper?
First, it gives us a clearer roadmap for training high-capability multimodal models. By being deliberate about architecture and data choices, and scaling carefully, we can unlock impressive few-shot learning and reasoning abilities.
Second, it surfaces key open questions for the field. How do we build benchmarks that comprehensively test multimodal skills? What's the right mix of data modalities and tasks for general-purpose models? How low can we go on model size while retaining performance?
Third, it sets a new standard for open research on foundational multimodal models. By detailing their training process and releasing ablations, the authors are enabling the community to reproduce and extend their work. This is critical for accelerating progress.
Looking ahead, the MM1 paper has the potential to be a significant milestone in multimodal AI research. By providing a rigorous empirical foundation for model design and training, it lays the groundwork for future advances in the field. While it remains to be seen if it will have a transformative impact akin to something like GPT-4, the insights generated here can guide researchers as they continue to push the boundaries of what's possible with multimodal systems. Of course, realizing this potential will require sustained effort to build on and extend these findings, while also grappling with the limitations and open questions highlighted above.
I for one am excited to see where this leads. If you're working on anything related, I'd love to hear about it in the comments! And if you found this summary valuable, please consider sharing it with others who might benefit.
As always, thanks for reading and being a paid subscriber. Your support makes these deep dives possible. I'll be back soon with more analysis of the latest in AI - stay tuned!
AIModels.fyi is a reader-supported publication. To receive new posts and support my work subscribe and be sure to follow me on Twitter!


Comments ()